遇到问题---CDH重启namenode--Command timed-out after 150 seconds--角色正在启动
情况
我们由于某些配置参数的调整 有时候需要重启namenode。
最方便的操作就是在CM后台直接操作–重新启动。
但是这次遇到的情况比较诡异,点击重启之后 namenode的状态变成了 已停止。
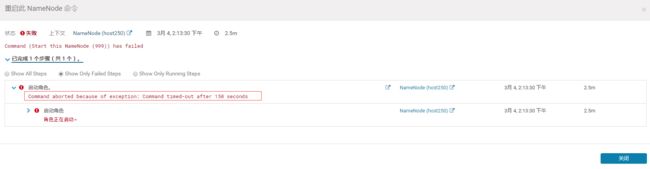
再次去点击重新启动则报错:
Command aborted because of exception:Command timed-out after 150 seconds
角色正在启动
HDFS启动的时候,如果DataNode上报的block个数达到了元数据记录的block个数的0.999倍才可以离开安全模式,否则一直是这种只读模式。
本来以为namenode需要去重新平衡块的情况,但是已经过了8个小时还没启动好,就有点慌了。
查了下资料,一般如果secondryNamenode节点没问题的话 fileimage文件大小并不会很大(GB左右)。
namenode的重启应该在50分钟左右是正常的。
时间超过了8个小时还没重启好,肯定是哪里出了问题。
排查第一步,先看namenode的角色日志
tail -f -n 800 /var/log/hadoop-hdfs/hadoop-cmf-hdfs-NAMENODE-host250.log.out发现输出比较正常,namenode一直在移动块和新增删除块,没有报异常。

第二步
查看cloudera-scm-server的日志
首先需要找到cloudera-scm-server在哪台服务器上。
任意一台机子使用命令
cat /etc/cloudera-scm-agent/config.ini可以看到cloudera-scm-server的ip地址
然后在cloudera-scm-server服务器上使用命令
sudo cat -n 800 /var/log/cloudera-scm-server/cloudera-scm-server.log 发现报错
Connection refused to http://host250:9000/heartbeat

这里有很多种可能
1、host250的namenode没启动
2、host250的防火墙阻止了对端口9000的访问
3、cloudera-scm-agent用来查看集群节点状态的9000端口未启用
需要一一排查
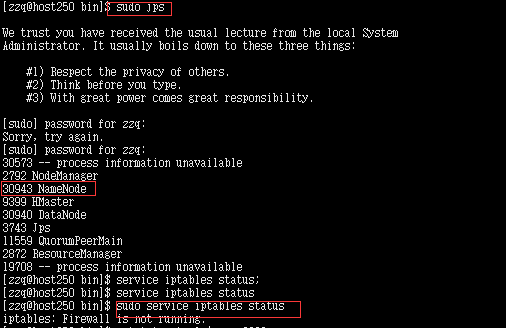
在host250上使用命令
sudo jps
sudo service iptables status发现 namenode节点其实已经起来了。
使用链接可以访问到namenode的情况,使用hive shell提交命令,namenode节点可以正常使用。
访问链接
http://192.168.30.250:50070/dfshealth.html#tab-overview防火墙也是关的,所以不是这两个原因,那么我们的症状是namenode节点其实已经启动好了,只是cm后台没有识别到。
如果防火墙没关需要使用命令
sudo service iptables stop查看cloudera-scm-agent用来查看集群节点状态的9000端口是否启用,果然没有

第三步
查看cloudera-scm-agent的日志
在host250上使用命令
sudo cat -n 200 /var/log/cloudera-scm-agent/cloudera-scm-agent.log发现报错
No socket could be created on (‘host250’, 9000) – [Errno 98] Address already in use

原因
根据上面的排查 我们已经可以推断问题出在host250的cloudera-scm-agent客户端服务上。
因为namenode其实已经启动起来了,是可以正常访问使用的,但是cm操作后台里还是显示的已停止。
主要是cloudera-scm-agent客户端跟集群节点通信的端口9000被占用导致无法通信导致的。
解决方式
我们这里需要排查9000端口使用的情况
在host250上使用命令
netstat -anp|grep 9000如果有应用程序占用了 需要把应用的程序端口修改一下,不要占用9000端口。
使用命令
kill -9 pid如果没有应用程序占用9000但是还是有这个错误。那么就是python的进程残留问题。
因为socket默认是不支持地址复用的。为什么程序跑完了端口还是被占用着?这个问题就要TCP连接的“四次挥手”。
更多细节可以参考
https://www.jianshu.com/p/ec7fecc64165
总的来说
就是
如果并发连接请求过多的时候,即短时间内连接请求很多,系统自动释放已占用端口的时间还没有到,又有连接请求(可用的端口已经被用完),所以还会出现 Address already in use错误提示),就会产生大量的TIME_WAIT状态的连接。这种情况下就有必要调整下linux的TCP/IP内核参数,让系统更快的释放TIME_WAIT连接。对于并发连接量大的情况我们需要这样设置:
用vi打开配置文件:
vi /etc/sysctl.conf 然后,在这个文件中,加入下面的几行内容:
net.ipv4.tcp_syncookies = 1 # 这一行配置文件里如果有就不用添加了
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_fin_timeout = 5 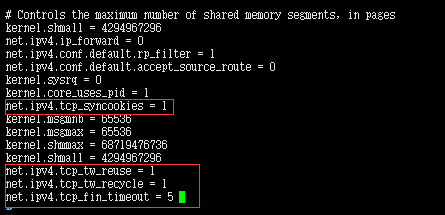
最后输入下面的命令,让内核参数生效:
/sbin/sysctl -p最后使用命令重启host250节点的cloudera-scm-agent
sudo service cloudera-scm-agent restart查看9000端口是否启动
使用命令
sudo netstat -anp|grep 9000发现cloudera-scm-agent客户端跟集群节点通信的端口9000已经起来了。
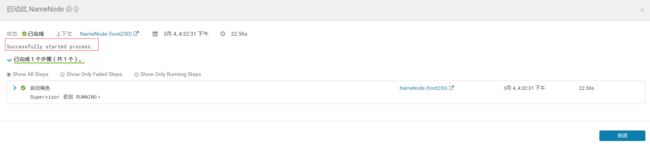
然后在cm操作后台重启 namenode节点,重启成功。