Nearest Neighbor分类算法的实现
Nearest Neighbor分类器
通过寻找最近的一个点来分类,可以实现一个简单的分类器。
具体步骤,总结如下:
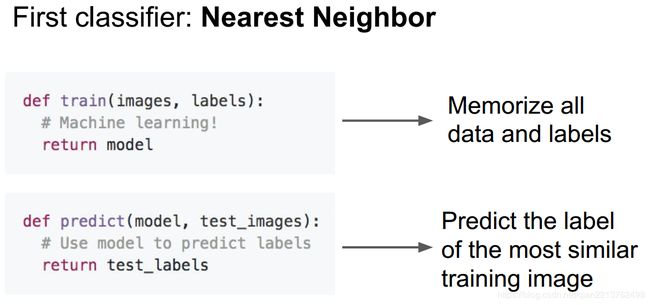
1、def train(self,X,y): #使用训练集的训练数据和标签来进行训练
2、def predict(self,X): #在新遇到的测试图像上预测分类标签
我们只需要在训练阶段,记住所有的训练数据和标签;在预测步骤,我们会拿一些新的测试图片去在训练数据中寻找与新图片最相似的,然后基于此来给出一个标签。
_________________________________________________________________________________________________
NN与KNN区别:
NN:我们找训练数据中最相似的1张图片的标签来作为测试图像的标签。
KNN:我们找训练数据中最相似的k个图片的标签,然后让他们针对测试图片进行投票,最后把票数最高的标签作为对测试图片的预测。
所以当k=1的时候,k-Nearest Neighbor分类器就是Nearest Neighbor分类器。从直观感受上就可以看到,更高的k值可以让分类的效果更平滑,使得分类器对于异常值更有抵抗力。http://vision.stanford.edu/teaching/cs231n-demos/knn/
不同颜色区域代表的是使用L2距离的分类器的决策边界。白色的区域是分类模糊的例子(即图像与两个以上的分类标签绑定)。需要注意的是,在NN分类器中,异常的数据点(比如:在蓝色区域中的绿点)制造出一个不正确预测的孤岛。5-NN分类器将这些不规则都平滑了,使得它针对测试数据的泛化(generalization)能力更好(例子中未展示)。注意,5-NN中也存在一些灰色区域,这些区域是因为近邻标签的最高票数相同导致的(比如:2个邻居是红色,2个邻居是蓝色,还有1个是绿色)
___________________________________________________________________________________________________
# encoding: utf-8
import numpy as np
#打开一个cifar10的batch文件,返回一个字典
def unpickle(file):
import cPickle
with open(file,'rb') as fo:#以二进制读模式打开
dict=cPickle.load(fo)
return dict #字典dict包含data labels
#导入CIFAR-10数据集
def load_CIFAR10(file):
#得到训练数据traing data
dataTrain=[] #training data
labelTrain=[]#training labels
for i in range(1,6):
dic = unpickle(file+"/data_batch_"+str(i))
for item in dic["data"]:
dataTrain.append(item)
for item in dic["labels"]:
labelTrain.append(item)
#得到测试数据test data
dataTest=[]
labelTest=[]
dic = unpickle(file+"/test_batch")
for item in dic["data"]:
dataTest.append(item)
for item in dic["labels"]:
labelTest.append(item)
return (dataTrain,labelTrain,dataTest,labelTest)#函数返回训练数据、训练标签、测试数据、测试标签
datatr,labeltr,datate,labelte=load_CIFAR10("/home/qianyu/Desktop/cifar-10-batches-py")
#将结构数据转化为ndarray,且不能copy对象
Xtr=np.asarray(datatr) #训练数据
Ytr=np.asarray(labeltr)#训练标签
Xte=np.array(datate) #测试数据
Yte=np.array(labelte) #测试标签
#把数组的另外三维都拉长为行向量
Xtr_rows=Xtr.reshape(Xtr.shape[0],32*32*3)
Xte_rows=Xte.reshape(Xte.shape[0],32*32*3)
print Xtr.shape
print Xte.shape
print Ytr.shape
print Yte.shape
print type(Xtr)
class NearnestNeighbor(object):
def __init__(self):
pass
def train(self,X,y): #使用训练集的数据和标签来进行训练
#X是N×D的数组,其中每列是个例子;Y是长度为N的一维向量
#最近邻分类器记住所有的训练数据、训练标签
self.Xtr=X
self.ytr=y
def predict(self,X): #预测输入的新数据的分类标签
#X是N×D的数组,其中每列是个我们想预测标签的例子
num_test=X.shape[0]
#确保预测的输出标签Ypred的类型与输入的训练标签ytr的类型一致
Ypred=np.zeros(num_test,dtype=self.ytr.dtype) #Return a new array of given shape and type, filled with zeros.
num=0
#遍历每个测试数据的行,找到最相近的训练数据,然后对于这个最邻近的图像预测标签
for i in xrange(num_test):
#找到与第i个测试数据 最邻近的训练数据,然后用最相似的该训练数据的标签作为测试图像的标签。
distances=np.sum(np.abs(self.Xtr-X[i,:]),axis=1) #使用L1距离:计算每一像素向量差的绝对值的和 axis=1,对列进行运算
#distances=np.sum(np.sqrt(self.Xtr-X[i,:]),axis=1) #使用L2距离:计算每一像素向量差的平方的和 再求平凡根
min_index=np.argmin(distances) #找到具有最小距离的index
Ypred[i]=self.ytr[min_index]
num=num+1
if num%10==0:
print "num=",num/10
return Ypred
nn=NearnestNeighbor() #创建最邻近分类器
nn.train(Xtr_rows,Ytr) #在训练集的图像和标签上训练分类器
Yte_predict=nn.predict(Xte_rows)#在测试图像上预测标签
#print出分类准确度(标签被正确预测出的个体的平均数)
print 'accuracy: %f' % ( np.mean(Yte_predict == Yte) )代码解读
通过使用训练数据、训练标签来学习一个模型(训练一个分类器),然后对于陌生的新数据(测试数据、测试标签)进行图像分类的预测。
datatr,labeltr,datate,labelte=load_CIFAR10("/home/qianyu/Desktop/cifar-10-batches-py")
#将结构数据转化为ndarray,且不能copy对象
Xtr=np.asarray(datatr) #训练数据
Ytr=np.asarray(labeltr)#训练标签
Xte=np.array(datate) #测试数据
Yte=np.array(labelte) #测试标签
Xtr 是训练数据、Ytr是训练标签(一个一维数组,存有值为0~9的图像分类标签)
Xte 是测试数据、Ytr是测试标签(一个一维数组,存有值为0~9的图像分类标签)
Xtr(大小是50000x32x32x3),Ytr是对应的大小是50000×1
Xte(大小是10000x32x32x3),Ytr是对应的大小是50000×1
拉长成为行向量了:
#把数组的另外三维都拉长为行向量
Xtr_rows=Xtr.reshape(Xtr.shape[0],32*32*3)
Xte_rows=Xte.reshape(Xte.shape[0],32*32*3)