HOG+SVM行人检测的两种方法
关于HOG+SVM,CSDN上有一些非常好的文章,这里给出我觉得写的比较好的几篇,仅供大家参考
目标检测的图像特征提取之(一)HOG特征
HOG:从理论到OpenCV实践
opencv 学习笔记-入门(21)之三线性插值-hog(二)
这篇博客写的是关于三线性插值的,为了减少混叠效应的,写的很好OpenCV中的HOG+SVM物体分类
OpenCV HOGDescriptor 参数图解
利用Hog特征和SVM分类器进行行人检测
以上就是个人觉得写的比较好的博客,基本上将上面的博客看懂了,HOG也比较理解了,如果还想输入了解HOG,建议直接看OpenCV HOG的源码
下面,就说说使用OpenCV 中的HOG+SVM实现行人检测的两种方式
说明:程序运行环境为VS2013+OpenCV3.0
第一种
先说第一种方式,直接上代码:
///////////////////////////////////HOG+SVM识别方式2///////////////////////////////////////////////////
void Train()
{
////////////////////////////////读入训练样本图片路径和类别///////////////////////////////////////////////////
//图像路径和类别
vector<string> imagePath;
vector<int> imageClass;
int numberOfLine = 0;
string buffer;
ifstream trainingData(string(FILEPATH)+"TrainData.txt");
unsigned long n;
while (!trainingData.eof())
{
getline(trainingData, buffer);
if (!buffer.empty())
{
++numberOfLine;
if (numberOfLine % 2 == 0)
{
//读取样本类别
imageClass.push_back(atoi(buffer.c_str()));
}
else
{
//读取图像路径
imagePath.push_back(buffer);
}
}
}
//关闭文件
trainingData.close();
////////////////////////////////获取样本的HOG特征///////////////////////////////////////////////////
//样本特征向量矩阵
int numberOfSample = numberOfLine / 2;
Mat featureVectorOfSample(numberOfSample, 3780, CV_32FC1);//矩阵中每行为一个样本
//样本的类别
Mat classOfSample(numberOfSample, 1, CV_32SC1);
Mat convertedImage;
Mat trainImage;
// 计算HOG特征
for (vector<string>::size_type i = 0; i <= imagePath.size() - 1; ++i)
{
//读入图片
Mat src = imread(imagePath[i], -1);
if (src.empty())
{
cout << "can not load the image:" << imagePath[i] << endl;
continue;
}
//cout << "processing:" << imagePath[i] << endl;
// 归一化
resize(src, trainImage, Size(64, 128));
// 提取HOG特征
HOGDescriptor hog(cvSize(64, 128), cvSize(16, 16), cvSize(8, 8), cvSize(8, 8), 9);
vector<float> descriptors;
double time1 = getTickCount();
hog.compute(trainImage, descriptors);//这里可以设置检测窗口步长,如果图片大小超过64×128,可以设置winStride
double time2 = getTickCount();
double elapse_ms = (time2 - time1) * 1000 / getTickFrequency();
//cout << "HOG dimensions:" << descriptors.size() << endl;
//cout << "Compute time:" << elapse_ms << endl;
//保存到特征向量矩阵中
for (vector<float>::size_type j = 0; j <= descriptors.size() - 1; ++j)
{
featureVectorOfSample.at<float>(i, j) = descriptors[j];
}
//保存类别到类别矩阵
//!!注意类别类型一定要是int 类型的
classOfSample.at<int>(i, 0) = imageClass[i];
}
///////////////////////////////////使用SVM分类器训练///////////////////////////////////////////////////
//设置参数,注意Ptr的使用
Ptr svm = SVM::create();
svm->setType(SVM::C_SVC);
svm->setKernel(SVM::LINEAR);//注意必须使用线性SVM进行训练,因为HogDescriptor检测函数只支持线性检测!!!
svm->setTermCriteria(TermCriteria(CV_TERMCRIT_ITER, 1000, FLT_EPSILON));
//使用SVM学习
svm->train(featureVectorOfSample, ROW_SAMPLE, classOfSample);
//保存分类器(里面包括了SVM的参数,支持向量,α和rho)
svm->save(string(FILEPATH) + "Classifier.xml");
/*
SVM训练完成后得到的XML文件里面,有一个数组,叫做support vector,还有一个数组,叫做alpha,有一个浮点数,叫做rho;
将alpha矩阵同support vector相乘,注意,alpha*supportVector,将得到一个行向量,将该向量前面乘以-1。之后,再该行向量的最后添加一个元素rho。
如此,变得到了一个分类器,利用该分类器,直接替换opencv中行人检测默认的那个分类器(cv::HOGDescriptor::setSVMDetector()),
*/
//获取支持向量机:矩阵默认是CV_32F
Mat supportVector = svm->getSupportVectors();//
//获取alpha和rho
Mat alpha;//每个支持向量对应的参数α(拉格朗日乘子),默认alpha是float64的
Mat svIndex;//支持向量所在的索引
float rho = svm->getDecisionFunction(0, alpha, svIndex);
//转换类型:这里一定要注意,需要转换为32的
Mat alpha2;
alpha.convertTo(alpha2, CV_32FC1);
//结果矩阵,两个矩阵相乘
Mat result(1, 3780, CV_32FC1);
result = alpha2*supportVector;
//乘以-1,这里为什么会乘以-1?
//注意因为svm.predict使用的是alpha*sv*another-rho,如果为负的话则认为是正样本,在HOG的检测函数中,使用rho+alpha*sv*another(another为-1)
for (int i = 0; i < 3780; ++i)
result.at<float>(0, i) *= -1;
//将分类器保存到文件,便于HOG识别
//这个才是真正的判别函数的参数(ω),HOG可以直接使用该参数进行识别
FILE *fp = fopen((string(FILEPATH) + "HOG_SVM.txt").c_str(), "wb");
for (int i = 0; i<3780; i++)
{
fprintf(fp, "%f \n", result.at<float>(0,i));
}
fprintf(fp, "%f", rho);
fclose(fp);
}
// 使用训练好的分类器识别
void Detect()
{
Mat img;
FILE* f = 0;
char _filename[1024];
// 获取测试图片文件路径
f = fopen((string(FILEPATH) + "TestData.txt").c_str(), "rt");
if (!f)
{
fprintf(stderr, "ERROR: the specified file could not be loaded\n");
return;
}
//加载训练好的判别函数的参数(注意,与svm->save保存的分类器不同)
vector<float> detector;
ifstream fileIn(string(FILEPATH) + "HOG_SVM.txt", ios::in);
float val = 0.0f;
while (!fileIn.eof())
{
fileIn >> val;
detector.push_back(val);
}
fileIn.close();
//设置HOG
HOGDescriptor hog;
hog.setSVMDetector(detector);// 使用自己训练的分类器
//hog.setSVMDetector(HOGDescriptor::getDefaultPeopleDetector());//可以直接使用05 CVPR已训练好的分类器,这样就不用Train()这个步骤了
namedWindow("people detector", 1);
// 检测图片
for (;;)
{
// 读取文件名
char* filename = _filename;
if (f)
{
if (!fgets(filename, (int)sizeof(_filename)-2, f))
break;
//while(*filename && isspace(*filename))
// ++filename;
if (filename[0] == '#')
continue;
//去掉空格
int l = (int)strlen(filename);
while (l > 0 && isspace(filename[l - 1]))
--l;
filename[l] = '\0';
img = imread(filename);
}
printf("%s:\n", filename);
if (!img.data)
continue;
fflush(stdout);
vector found, found_filtered;
double t = (double)getTickCount();
// run the detector with default parameters. to get a higher hit-rate
// (and more false alarms, respectively), decrease the hitThreshold and
// groupThreshold (set groupThreshold to 0 to turn off the grouping completely).
//多尺度检测
hog.detectMultiScale(img, found, 0, Size(8, 8), Size(32, 32), 1.05, 2);
t = (double)getTickCount() - t;
printf("detection time = %gms\n", t*1000. / cv::getTickFrequency());
size_t i, j;
//去掉空间中具有内外包含关系的区域,保留大的
for (i = 0; i < found.size(); i++)
{
Rect r = found[i];
for (j = 0; j < found.size(); j++)
if (j != i && (r & found[j]) == r)
break;
if (j == found.size())
found_filtered.push_back(r);
}
// 适当缩小矩形
for (i = 0; i < found_filtered.size(); i++)
{
Rect r = found_filtered[i];
// the HOG detector returns slightly larger rectangles than the real objects.
// so we slightly shrink the rectangles to get a nicer output.
r.x += cvRound(r.width*0.1);
r.width = cvRound(r.width*0.8);
r.y += cvRound(r.height*0.07);
r.height = cvRound(r.height*0.8);
rectangle(img, r.tl(), r.br(), cv::Scalar(0, 255, 0), 3);
}
imshow("people detector", img);
int c = waitKey(0) & 255;
if (c == 'q' || c == 'Q' || !f)
break;
}
if (f)
fclose(f);
return;
}
void HOG_SVM2()
{
//如果使用05 CVPR提供的默认分类器,则不需要Train(),直接使用Detect检测图片
Train();
Detect();
}
int main()
{
//HOG+SVM识别方式1:直接输出类别
//HOG_SVM1();
//HOG+SVM识别方式2:输出图片中的存在目标的矩形
HOG_SVM2();
} 这里我想说明一下TrainData.txt,这个文件放置了所有样本的路径和类别,如下:
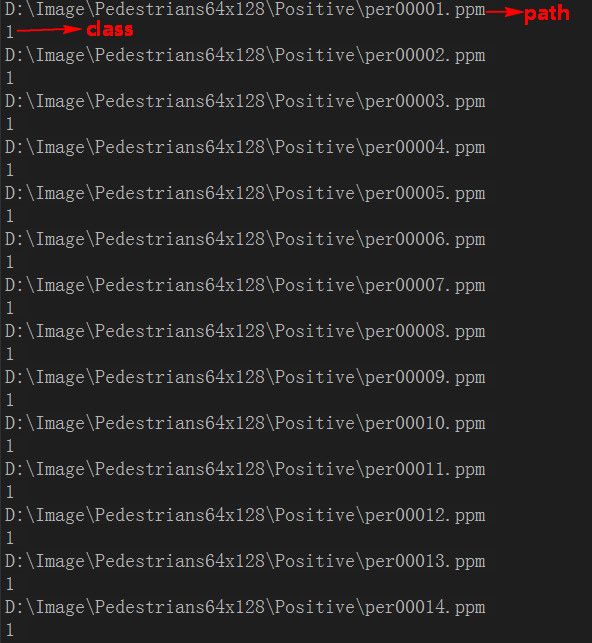
关
于如何读取正负样本的路径到txt文件,可以使用批处理文件,批处理文件我上传到了CSDN,大家可以去下载
点击下载
正负样本至少保证有1000,不能太少,否则效果就不好了,其中HOG_SVM.txt里面包含了判别函数的参数,这个参数可以直接给HOG用
下面就是我的测试效果:


检测效果还可以.
测试图片我也上传到网上了
点击下载
当然你也可以不用自己训练分类器,直接使用OpenCV自带的分类器,OpenCV自带的分类器使用的是05年CVPR那篇文章中作者训练好的分类器,下面我们就来看看效果:

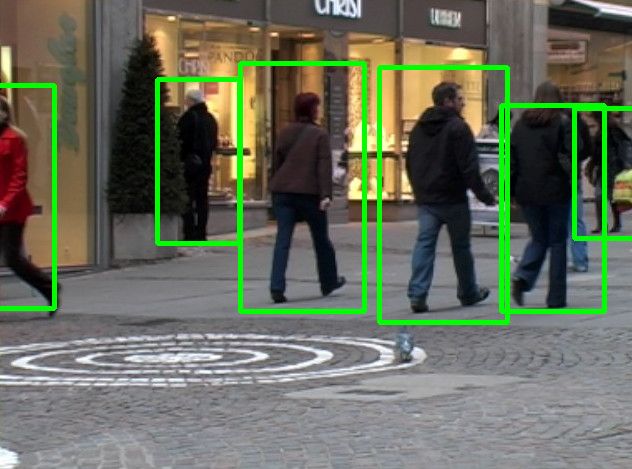
图中可以看出,OpenCV自带的分类器效果要比自己训练的好,主要原因大概有以下几点
1.训练样本不足,我的正负样本才900多
2.正样本图片不够清晰,导致特征提取有比较大的误差
最近有人在运行博客中程序的时候出现了问题,让我看看程序,我也不太清楚什么问题,所以我将整个程序和程序测试数据打包了一下,上传到了CSDN上。
点击下载
解压后,将”Pedestrians64x128”文件夹放置在D盘根目录,然后使用HOG.cpp新建一个工程,直接可以运行。
注:环境是VS2013+OpenCV3.0.0,Release版本
第二种
下面说说第二种方式,第二种方式就是传统的方式了,就是对于测试样本,提取特征,然后使用训练好的分类器进行识别,代码
///////////////////////////////////HOG+SVM识别方式1///////////////////////////////////////////////////
void HOG_SVM1()
{
////////////////////////////////读入训练样本图片路径和类别///////////////////////////////////////////////////
//图像路径和类别
vector<string> imagePath;
vector<int> imageClass;
int numberOfLine = 0;
string buffer;
ifstream trainingData(string(FILEPATH) + "TrainData.txt", ios::in);
unsigned long n;
while (!trainingData.eof())
{
getline(trainingData, buffer);
if (!buffer.empty())
{
++numberOfLine;
if (numberOfLine % 2 == 0)
{
//读取样本类别
imageClass.push_back(atoi(buffer.c_str()));
}
else
{
//读取图像路径
imagePath.push_back(buffer);
}
}
}
trainingData.close();
////////////////////////////////获取样本的HOG特征///////////////////////////////////////////////////
//样本特征向量矩阵
int numberOfSample = numberOfLine / 2;
Mat featureVectorOfSample(numberOfSample, 3780, CV_32FC1);//矩阵中每行为一个样本
//样本的类别
Mat classOfSample(numberOfSample, 1, CV_32SC1);
//开始计算训练样本的HOG特征
for (vector<string>::size_type i = 0; i <= imagePath.size() - 1; ++i)
{
//读入图片
Mat src = imread(imagePath[i], -1);
if (src.empty())
{
cout << "can not load the image:" << imagePath[i] << endl;
continue;
}
cout << "processing" << imagePath[i] << endl;
//缩放
Mat trainImage;
resize(src, trainImage, Size(64, 128));
//提取HOG特征
HOGDescriptor hog(Size(64, 128), Size(16, 16), Size(8, 8), Size(8, 8), 9);
vector<float> descriptors;
hog.compute(trainImage, descriptors);//这里可以设置检测窗口步长,如果图片大小超过64×128,可以设置winStride
cout << "HOG dimensions:" << descriptors.size() << endl;
//保存特征向量矩阵中
for (vector<float>::size_type j = 0; j <= descriptors.size() - 1; ++j)
{
featureVectorOfSample.at<float>(i, j) = descriptors[j];
}
//保存类别到类别矩阵
//!!注意类别类型一定要是int 类型的
classOfSample.at<int>(i, 0) = imageClass[i];
}
///////////////////////////////////使用SVM分类器训练///////////////////////////////////////////////////
//设置参数
//参考3.0的Demo
Ptr svm = SVM::create();
svm->setKernel(SVM::RBF);
svm->setType(SVM::C_SVC);
svm->setC(10);
svm->setCoef0(1.0);
svm->setP(1.0);
svm->setNu(0.5);
svm->setTermCriteria(TermCriteria(CV_TERMCRIT_EPS, 1000, FLT_EPSILON));
//使用SVM学习
svm->train(featureVectorOfSample, ROW_SAMPLE, classOfSample);
//保存分类器
svm->save("Classifier.xml");
///////////////////////////////////使用训练好的分类器进行识别///////////////////////////////////////////////////
vector<string> testImagePath;
ifstream testData(string(FILEPATH) + "TestData.txt", ios::out);
while (!testData.eof())
{
getline(testData, buffer);
//读取
if (!buffer.empty())
testImagePath.push_back(buffer);
}
testData.close();
ofstream fileOfPredictResult(string(FILEPATH) + "PredictResult.txt"); //最后识别的结果
for (vector<string>::size_type i = 0; i <= testImagePath.size() - 1; ++i)
{
//读取测试图片
Mat src = imread(testImagePath[i], -1);
if (src.empty())
{
cout << "Can not load the image:" << testImagePath[i] << endl;
continue;
}
//缩放
Mat testImage;
resize(src, testImage, Size(64, 64));
//测试图片提取HOG特征
HOGDescriptor hog(cvSize(64, 64), cvSize(16, 16), cvSize(8, 8), cvSize(8, 8), 9);
vector<float> descriptors;
hog.compute(testImage, descriptors);
cout << "HOG dimensions:" << descriptors.size() << endl;
Mat featureVectorOfTestImage(1, descriptors.size(), CV_32FC1);
for (int j = 0; j <= descriptors.size() - 1; ++j)
{
featureVectorOfTestImage.at<float>(0, j) = descriptors[j];
}
//对测试图片进行分类并写入文件
int predictResult = svm->predict(featureVectorOfTestImage);
char line[512];
//printf("%s %d\r\n", testImagePath[i].c_str(), predictResult);
std::sprintf(line, "%s %d\n", testImagePath[i].c_str(), predictResult);
fileOfPredictResult << line;
}
fileOfPredictResult.close();
}
int main()
{
//HOG+SVM识别方式1:直接输出类别
HOG_SVM1();
//HOG+SVM识别方式2:输出图片中的存在目标的矩形
//HOG_SVM2();
} 大家可以分别使用自己的数据集测试一下上面的两种方式,如果有上面疑问,欢迎留言讨论
非常感谢您的阅读,如果您觉得这篇文章对您有帮助,欢迎扫码进行赞赏。
