模仿AlphaGo围棋博弈,MuGo实现策略网络以及蒙特卡洛树搜索
AlphaGo数次击败了人类围棋高手,大家是不是摩拳擦掌,想对Alphago一探究竟。
网友brliee的作品MuGO实现了AlphaGo的策略网络(policy)和蒙塔卡罗树搜索(mcts)两大主要策略,并且能够训练自己的深度神经网络,可视化在线对弈。本文即是MuGo的实现过程,一起来看看吧。
MuGo标题镇楼:
![]()
本文实现环境:
- ubuntu14.04
- Python 3.5.2 |Anaconda custom (64-bit)
- tensorflow1.2.1
- gogui1.4.9
- 环境配置及其他工具配置见下文
主要环境配置:
1.tensorflow
tensorflow相较于其他深度学习框架,配置十分简单,只需在Terminal中使用pip安装指令即可
pip3 install tensorflow
我先后在win10、ubuntu14.04虚拟机、ubuntu14.04台式都顺利配置成功,没有遇到过多Bug。如过你tensorflow配置不顺利,可以参看 官网教程也可参看 网友博文,安装成功后,不要忘记测试一下,首先进入python环境,然后执行
python
import tensorflow as tf
hello = tf.constant('i want alphago')
sess = tf.Session()
print sess.run(hello)
打印出“i want alphago”,说明tensorflow安装成功,如图。

2.gogui
- MuGo的可视化采用了多种方法,我采用的是gogui这一款在线围棋博弈程序。如果你直接Google会发现该软件已经下线,但仍有下载途径:gogui1.4.9下载
- 此处有坑:请下载zip压缩包版本,否则现在tar.gz版本的话,使用时会报错。
下载完成后解压,进入解压后文件夹,执行:
sudo ./install.sh

如果什么错都没有,基本可以说安装成功了,测试gogui是否安装成功:
gogui-twogtp -black 'gogui-display' -white 'gogui-display' -size 19 -komi 7.5 -verbose -auto
出现棋盘,说明安装成功。
3.其他必要工具安装见下文
获取MuGo源码:
1.源码获取
下载地址:https://github.com/brilee/MuGo ,下载后unzip解压即可。
2.安装需要的工具
- 打开MuGo-master文件夹中的requirements.txt 逐个安装所需要的工具(一定要安装),其中的tensorflow刚才已经安装过了。
- 这里使用pip命令即可轻松安装,例如要安装argh:
- pip install argh

MuGo代码实现:
如果以上均安装成功的话,那么现在就可以来跑一跑作者已经训练好了的小狗了
1.自带Demo实现
命令行进入MuGo-master文件夹,执行:
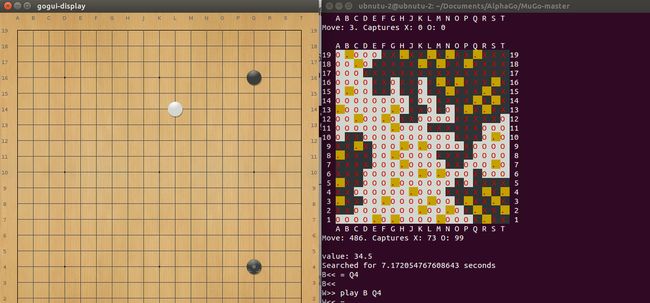
gogui-twogtp -black 'python3 main.py gtp policy --read-file=saved_models/20170718' -white 'gogui-display' -size 19 -komi 7.5 -verbose -auto
white加载的是交互程序,也就是你;black选手就是main.py中的plicy策略网络,运用的是saved_models文件夹下,名为20170718的训练好的数据。另外,程序实现必须用python3
![]()
执行命令后出现了棋盘,恭喜你,游戏加载成功,你可以和模仿的alphago程序一决高下了,注意:此时使用的是策略网络。

也可以将plicy改为mcts,此时运用蒙特卡洛树搜索,速度较策略网络慢一点。
2.训练自己的小狗
以上加载已经训练好的数据,跑通了程序,但是这还不算,程序最关键的在于能够训练自己的网络,下面来训练自己的网络。
(1)下载对弈棋局
从这个网站上下载训练数据,上面有近15年的SGF格式围棋棋盘,任选一年zip格式下载,解压得到kgs开头的文件夹,删除里面的大部分,剩余30个左右文件即可(后面你就知道为啥)。
(2)预处理训练数据
在MuGo-master文件夹下面,新建data子文件夹,把刚才解压的kgs开头的文件夹放入data中,执行预处理训练数据命令:
python main.py preprocess data/kgs-*
执行完毕,MuGo-master下面出现了processed_data文件夹,里面就是预处理后的数据。
(3)训练
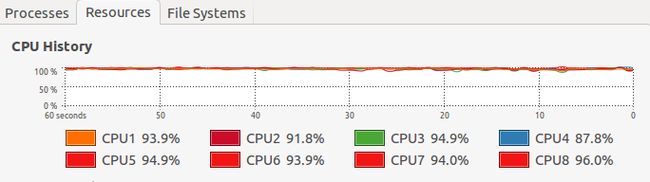
在MuGo-master文件夹下面,新建tmp子文件夹,用来存放训练数据。执行:
python main.py train processed_data/ --save-file=tmp/savedmodel --epochs=1 --logdir=logs/my_training_run
出现:
![]()
说明正在训练,如果你刚才没有删除训练数据中的大部分,那你估计要等上20个小时,如果你删除了大部分数据,几分钟就可以训练完毕。tmp文件夹中出现了几个名为savedmodel的文件,就是训练好的数据。注意:训练需要很久,根据棋盘数量定,一年的棋盘,用cpu训练怎么也得几天,而且,如果没有训练完毕,ctrl+c强行中断,就算出现了训练数据,也是使用不了的。我用cpu训练的时候,感觉cpu要疯,也不想等,就减少数据量仅做测试。

启动gogui引擎,加载训练好的数据,实现对弈。
gogui-twogtp -black 'python main.py gtp policy --read-file=tmp/savedmodel' -white 'gogui-display' -size 19 -komi 7.5 -verbose -auto
OK! 到此为止,已经完成了程序的全部功能,如何使用GPU加速还有待探究。
参考:
- tensorflow中文文档:
http://wiki.jikexueyuan.com/project/tensorflow-zh/ - AlphaGo原理:
https://www.zhihu.com/question/41176911
http://www.shenlanxueyuan.com/course/5/task/15/show - tensorflow安装:
https://www.leiphone.com/news/201606/ORlQ7uK3TIW8xVGF.html - http://f.dataguru.cn/thread-743474-1-1.html