Centos7搭建Hadoop HA完全分布式集群(6台机器)(内含hbase,hive,flume,kafka,spark,sqoop,phoenix,storm)
目录
Centos7搭建Hadoop HA完全分布式集群(6台机器)(内含hbase,hive,flume,kafka,spark,sqoop,phoenix,storm). 1
前期配置. 2
安装jdk 5
安装zookeeper 7
安装hadoop 8
启动集群. 17
安装hbase 21
安装hive 27
安装Flume 34
安装kafka 37
安装spark 43
安装Sqoop 47
安装Phoenix 49
安装Storm 51
安装Redis 55
角色担任

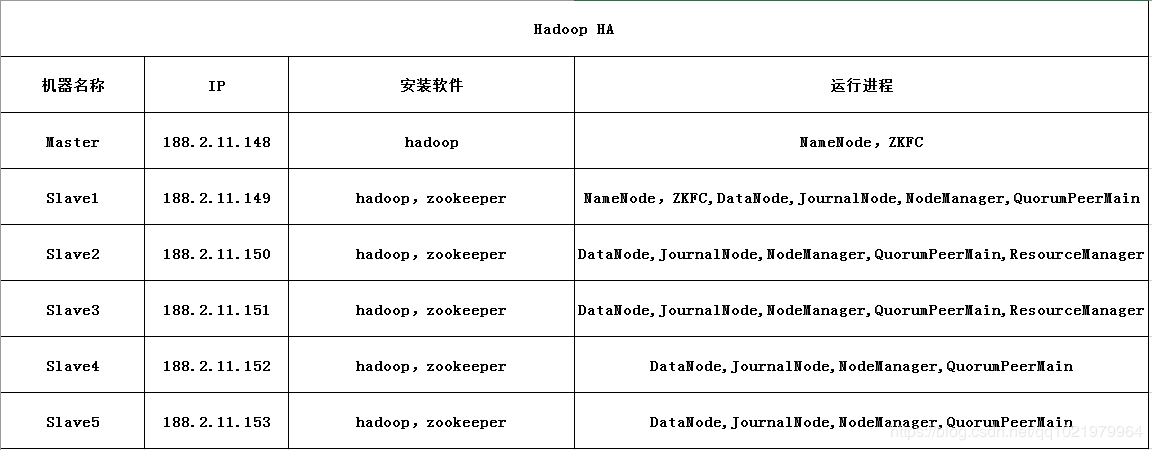
Hadoop HA
HBase HA

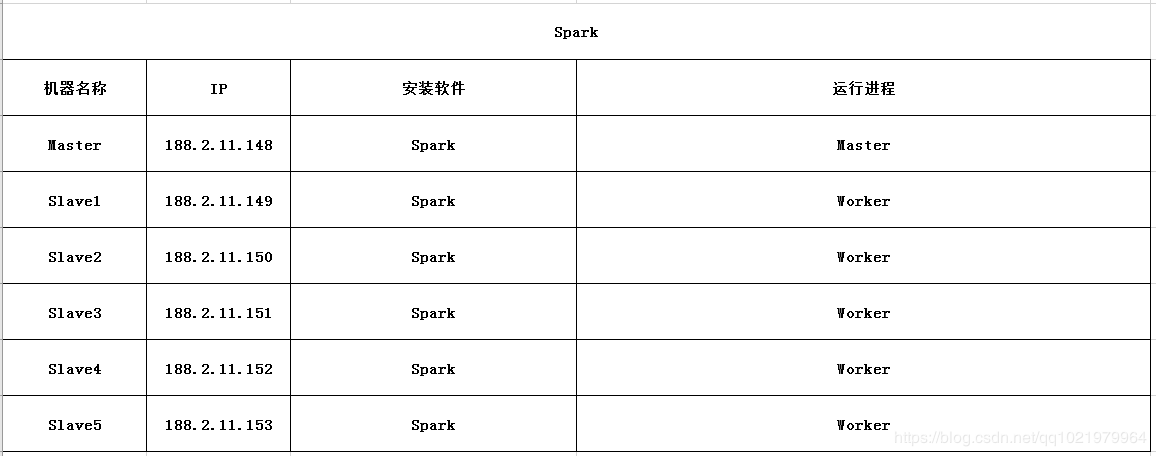
Spark
Storm HA

Centos7搭建Hadoop HA完全分布式集群(6台机器)(内含hbase,hive,flume,kafka,spark,sqoop,phoenix,storm)
采用6台机器
主机名 ip 对应的角色
Master 188.2.11.148 namenode(主)
Slave1 188.2.11.149 namenode2,datanode1(主备,从1)
Slave2 188.2.11.150 datanode2(从2)
Slave3 188.2.11.151 datanode3(从3)
Slave4 188.2.11.152 datanode4(从4)
Slave5 188.2.11.153 datanode5(从5)
前期配置
1.修改主机名(6台机器都要操作,以Master为举例)
hostnamectl set-hostname Master(永久修改主机名)
reboot(重启系统)

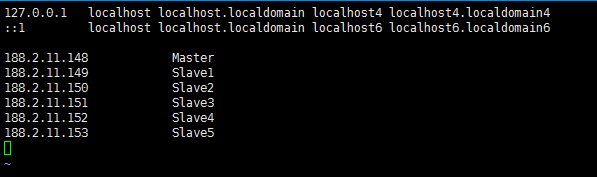
2.修改hosts(6台机器都要操作,以Master举例)
188.2.11.148 Master
188.2.11.149 Slave1
188.2.11.150 Slave2
188.2.11.151 Slave3
188.2.11.152 Slave4
188.2.11.153 Slave5
![]()
3.准备hadoop专用用户
adduser kfs 创建kfs用户
passwd kfs 设置用户密码

4.尝试能否ping通(6台机器都要操作,以Master举例)
ping -c 3 Slave1

5.ssh生成密钥(6台机器都要操作)
ssh-keygen -t rsa (连续三次回车)

6.切换到.ssh目录下,查看公钥和私钥,并将id_rsa.pub复制到authorized_keys,然后将6台机器的authorized_key复制到本地将内容合并
cd .ssh
cp id_rsa.pub authorized_keys

7.来到root用户下为.ssh赋值权限
su root
cd ..
chmod 700 .ssh
chmod 600 .ssh/authorized_keys

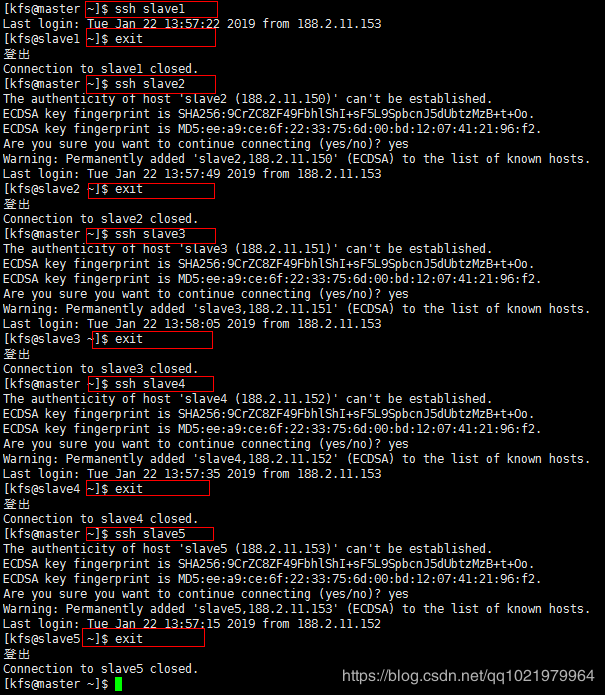
8.ssh 与别的节点无密钥连接(6台机器都需要进行无密钥连接,master举例)
ssh slave1 (连接到slave1)
exit (登出)
ssh slave2 (连接到slave2)
exit (登出)
ssh slave3 (连接到slave3)
exit (登出)
ssh slave4 (连接到slave4)
exit (登出)
ssh slave5 (连接到slave5)
exit (登出)
9.关闭防火墙(6台机器都要关闭,master举例)
systemctl stop firewalld.service
![]()
安装jdk
10.安装jdk之前,先检查是否已经安装了open的jdk,有的话需要先卸载(6台机器都要卸载)
java -version

11.查看有jdk的存在,需要先卸载然后再安装oracle的jdk
rpm -qa | grep java (查询java版本)

rpm -e --nodeps xxx (逐个删除完)
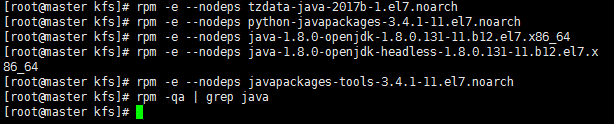
rpm -qa | grep java (没有显示有了,那就是删除完了,可以安装oracle的jdk)
12.在usr目录下创建java文件夹,将jdk拷贝到java目录
cd /usr/java
ls
tar zxvf jdk-8u144-linux-x64.tar.gz

ls
![]()
13.jdk的环境变量配置(使用的是在root目录下的全局配置文件/etc/profile,6台机器都要配置,master举例)
vi /etc/profile
![]()
export JAVA_HOME=/usr/java/jdk1.8.0_144
export PATH=$JAVA_HOME/bin:$PATH
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:${JRE_HOME}/lib

保存退出之后使用命令让配置生效
source /etc/profile
![]()
验证版本

安装zookeeper
14.上传和解压zookeeper解压到/home/kfs目录(在Slave1,2,3,4,5节点上配置)
cd software/
ls
tar -zxvf zookeeper-3.4.5.tar.gz -C /home/kfs/

15.来到解压的zookeeper-3.4.5/conf目录下,将zoo_sample.cfg复制到zoo.cfg
cd ..
cd zookeeper-3.4.5/conf/
ls
cp zoo_sample.cfg zoo.cfg

16.修改zookeeper的配置
添加以下配置
dataDir=/home/kfs/zookeeper-3.4.5/data
dataLogDir=/home/kfs/zookeeper-3.4.5/log
clientPort=2181
server.1=Slave1:2888:3888
server.2=Slave2:2888:3888
server.3=Slave3:2888:3888
server.4=Slave4:2888:3888
server.5=Slave5:2888:3888

17.创建log和data目录,新建myid加入对应的server.x参数(比如slave1的myid内容是1)每台服务器都需要
mkdir log
mkdir data
echo "1"
![]()
![]()
![]()
安装hadoop
18.安装解压hadoop到/home/kfs目录下(Master举例)
tar -zxvf hadoop-2.7.4.tar.gz -C /home/kfs/
![]()
解压成功

19.进入配置文件目录下修改配置文件
cd hadoop-2.7.4
cd etc/hadoop

20.修改core-site.xml
vi core-site.xml
![]()

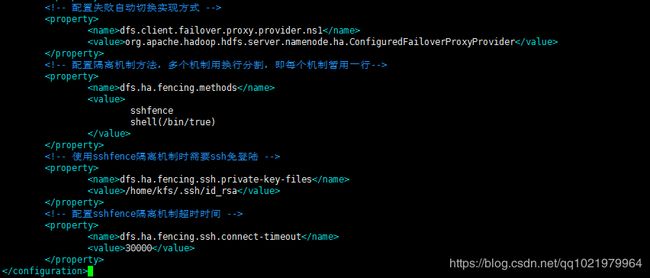
21.修改hdfs-site.xml
vi hdfs-site.xml
![]()
sshfence
shell(/bin/true)

22.新增mapred-site.xml
vi mapred-site.xml
![]()

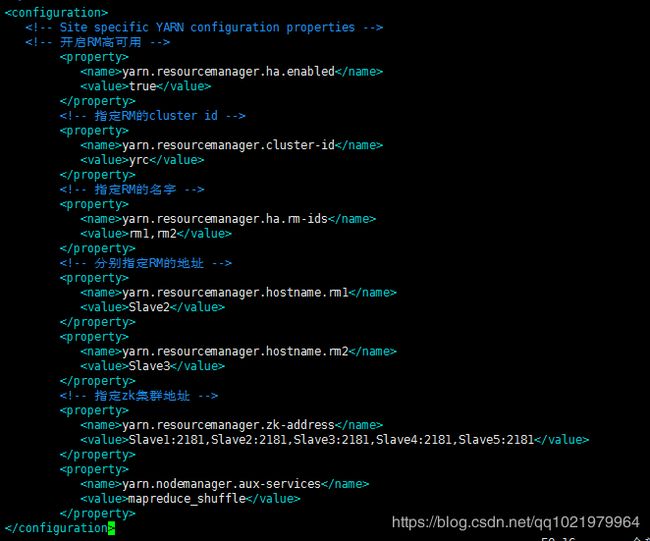
23.修改yarn-site.xml
vi yarn-site.xml
![]()
24.修改slaves
vi slaves
![]()
Slave1
Slave2
Slave3
Slave4
Slave5

25.修改hadoop-env.sh
vi hadoop-env.sh
![]()
export JAVA_HOME=/usr/java/jdk1.8.0_144
![]()
26.修改yarn-env.sh
vi yarn-env.sh
![]()
export JAVA_HOME=/usr/java/jdk1.8.0_144
![]()
27. 所有需要修改的配置文件
( core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
slaves
hadoop-env.sh
yarn-env.sh)

28.将配置好的hadoop拷贝到其他节点
cd
scp -r ./hadoop-2.7.4 slave1:/home/kfs/
scp -r ./hadoop-2.7.4 slave2:/home/kfs/
scp -r ./hadoop-2.7.4 slave3:/home/kfs/
scp -r ./hadoop-2.7.4 slave4:/home/kfs/
scp -r ./hadoop-2.7.4 slave5:/home/kfs/
![]()
![]()
![]()
![]()
![]()
29.来到root用户配置环境变量
su root
vi /etc/profile

export HADOOP_HOME=/home/kfs/hadoop-2.7.4
export PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin
![]()
30.生效配置文件
source /etc/profile
![]()
31.回到kfs用户的hadoop目录创建hadoop的临时文件夹和存放hdfs的文件夹
su kfs
cd hadoop-2.7.4/
mkdir tmp
mkdir journaldata

启动集群
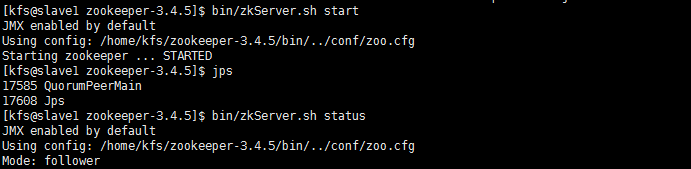
32.启动zookeeper集群(需要启动Slave1,2,3,4,5,以Slave1举例)
bin/zkServer.sh start (启动服务)
bin/zkServer.sh status (查看服务状态)
33.启动 journalnode(需要启动Slave1,2,3,4,5,以Slave1举例)
cd
cd hadoop-2.7.4
./sbin/hadoop-daemon.sh start journalnode

34.格式化HDFS(在Matser上执行)(主用)
./bin/hdfs namenode -format ns
![]()
35. 启动namenode进程
./sbin/hadoop-daemon.sh start namenode
![]()
36.格式化HDFS(在Slave1上执行)(备用,或者是直接将Master下的/home/data/hadoop-data/tmp复制到Slave1)
./bin/hdfs namenode -bootstrapStandby
![]()
37. 启动namenode进程
./sbin/hadoop-daemon.sh start namenode
![]()
38.在两台namenode节点都启动ZKFC
./sbin/hadoop-daemon.sh start zkfc
![]()
![]()
39.启动datanode(需要启动Slave1,2,3,4,5,以Slave1举例)
./sbin/hadoop-daemon.sh start datanode
![]()
40.启动ResourceManager(在Slave2和Slave3启动)
./sbin/start-yarn.sh
![]()
![]()
41.启动的时候如果只有namenode,应该是VERSION下的cluster的id不匹配。可以将Master下复制到其他节点下
vi /home/data/hadoop-data/tmp/dfs/name/current/VERSION
![]()

![]()

42.用jps查看一下起的进程是否正确
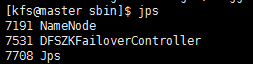





43.使用管理员方式运行hosts文件
在其中添加
188.2.11.148 Master
188.2.11.149 Slave1
188.2.11.150 Slave2
188.2.11.151 Slave3
188.2.11.152 Slave4
188.2.11.153 Slave5


44.访问master:50070和slave1:50070可以看出都是namenode,但一个是Active一个是Standby


安装hbase
45.解压Hbase到hbase(master举例,别的节点再拷贝过去就行)
cd software
ls
tar -zxvf hbase-1.2.3-bin.tar.gz -C /home/kfs

46.来到/home/data目录下创建hbase-data存放hbase的数据
mkdir hbase-data
cd hbse-data
mkdir logs
mkdir pids

47.修改hbase-env.sh
vi hbase-env.sh
![]()

48.修改hbase-site.xml
vi hbase-site.xml
![]()

49.修改regionservers
vi regionservers
![]()
Slave1
Slave2
Slave3
Slave4
Slave5

50.复制hadoop下的core-site.xml和hdfs-site.xml文件到hbase的conf下
cp /home/kfs/hadoop-2.7.4/etc/hadoop/core-site.xml /home/kfs/hbase-1.2.3/conf/
cp /home/kfs/hadoop-2.7.4/etc/hadoop/hdfs-site.xml /home/kfs/hbase-1.2.3/conf/
![]()
![]()
51.拷贝新建的文件夹到别的节点上
scp -r /home/data/hbase-data/ slave1:/home/data/hbase-data/
scp -r /home/data/hbase-data/ slave2:/home/data/hbase-data/
scp -r /home/data/hbase-data/ slave3:/home/data/hbase-data/
scp -r /home/data/hbase-data/ slave4:/home/data/hbase-data/
scp -r /home/data/hbase-data/ slave5:/home/data/hbase-data/

52.拷贝hbase的文件夹到别的节点
scp -r /home/kfs/hbase-1.2.3/ slave1:/home/kfs/hbase-1.2.3/
scp -r /home/kfs/hbase-1.2.3/ slave2:/home/kfs/hbase-1.2.3/
scp -r /home/kfs/hbase-1.2.3/ slave3:/home/kfs/hbase-1.2.3/
scp -r /home/kfs/hbase-1.2.3/ slave4:/home/kfs/hbase-1.2.3/
scp -r /home/kfs/hbase-1.2.3/ slave5:/home/kfs/hbase-1.2.3/
![]()
![]()
![]()
![]()
![]()
53.来到root用户修改环境变量
su root
vi /etc/profile

export HBASE_HOME=/home/kfs/hbase-1.2.3
:$HBASE_HOME/bin
![]()
让配置生效
![]()
54.返回kfs用户启动主HMaster
su kfs
cd ..
./bin/start-hbase.sh

55.启动Slave1作为备份的HMaster
./bin/hbase-daemon.sh start master
![]()
56.如果启动时有个别节点没有启动HRegionserver,则单独启动
./hbase-daemon.sh start regionserver
57.如果还是自动关闭,查看是不是时间差别大,可以同步时间,或者是在hbase的hbase-site.xml配置文件下添加,将时间改大点

58.通过浏览器访问hbase管理页面
Master:16010
Slave1:16010

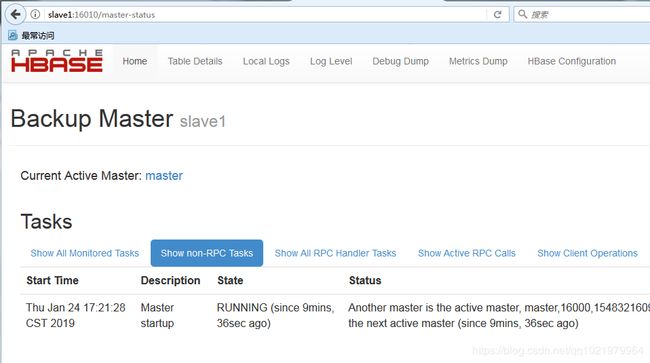
安装hive
59.安装hive之前先安装MySQL,要使用MySQL做元数据,但在安装MySQL之前先删除mariadb
rpm -qa |grep -i mariadb (查看是否有mariadb)
![]()
60.存在mariadb则卸载
rpm -e --nodeps mariadb-libs-5.5.56-2.el7.x86_64

61. 判断mysql是否存在,有则删除
rpm -qa |grep -i mysql (查看mysql是否存在)
![]()
62.来到software目录下的mysql8.0文件夹安装mysql
cd software/mysql-8.0
rpm -ivh mysql-community-common-8.0.11-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-8.0.11-1.el7.x86_64.rpm
rpm -ivh mysql-community-client-8.0.11-1.el7.x86_64.rpm
rpm -ivh mysql-community-server-8.0.11-1.el7.x86_64.rpm

63.启动mysql的服务
service mysqld start
![]()
64.查看初始密码
vi /var/log/mysqld.log
初始密码是_#?1j&OjVp=E
![]()

65.登录mysql
mysql -u root -p
输入密码:_#?1j&OjVp=E

66.修改mysql的root密码(注:密码需要有8位,包含数字,小写字母,大写字母,特殊符号)
alter user 'root'@'localhost' identified by '1qaz@WSX';
![]()
67.创建一个hive的用户并设置权限
create user 'hive'@'%' identified by '1qaz@WSX';
grant all privileges on *.* to 'hive'@'%' with grant option;
flush privileges;

68.返回kfs用户解压hive到kfs目录下
quit (退出mysql界面)
exit 返回kfs用户
cd software
tar -zxvf apache-hive-2.3.2-bin.tar.gz -C /home/kfs/

69.来到hive目录的conf文件夹下,新增hive-site.xml,设置元数据库等
cd
ls
cd apache-hive-2.3.2-bin/conf/
vi hive-site.xml



70.将mysql-connector-java-8.0.11.jar复制到hive的lib目录下
cp /home/kfs/software/mysql-8.0/mysql-connector-java-8.0.11.jar /home/kfs/apache-hive-2.3.2-bin/lib/
![]()
71.修改环境变量
vi /etc/profile
![]()
export HIVE_HOME=/home/kfs/apache-hive-2.3.2-bin
:$HIVE_HOME/bin:$HIVE_HOME/conf
![]()
![]()
生效配置文件
![]()
72.返回kfs用户并返回hive目录
exit
cd ..

73.启动hive的metastore
./bin/hive --service metastore &
![]()

74.启动hive的hiveserver2
./bin/hive --service hiveserver2&

75.查看jps有两个RunJar就可以了

76.启动hive
./bin/hive (方式一)

./bin/hive -hiveconf hive.root.logger=DEBUG,console(方式二,启动这个可以打印出各种log)

安装Flume
77.解压flume到/home/kfs/ (以Slave1举例,其他的节点拷贝,并修改环境变量)
cd software
tar -zxvf apache-flume-1.8.0-bin.tar.gz -C /home/kfs/
![]()
![]()
78.来到flume的conf目录下复制两个文件
cd apache-flume-1.8.0-bin/conf/
cp flume-env.sh.template flume-env.sh
![]()
79.修改flume-env.sh文件
vi flume-en.sh
![]()
export JAVA_HOME=/usr/java/jdk1.8.0_144
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"

80.配置一个配置文件作为测试,flume-conf.properties
vi flume-conf.properties
![]()
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
a1.sources.r1.channels = c1
a1.sinks.k1.type = logger
a1.sinks.k1.channel = c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100

81.来到root用户修改环境变量
su root
vi /etc/profile

export FLUME_HOME=/home/kfs/apache-flume-1.8.0-bin
export FLUME_CONF_DIR=$FLUME_HOME/conf
:FLUME_HOME/bin
![]()
生效配置
source /etc/profile
![]()
82.将flume文件夹拷贝到其他节点
scp -r /home/kfs/apache-flume-1.8.0-bin/ slave2:/home/kfs/
scp -r /home/kfs/apache-flume-1.8.0-bin/ slave3:/home/kfs/
scp -r /home/kfs/apache-flume-1.8.0-bin/ slave4:/home/kfs/
scp -r /home/kfs/apache-flume-1.8.0-bin/ slave5:/home/kfs/
![]()
![]()
![]()
![]()
83.启动flume
./bin/flume-ng agent --conf ./conf/ --conf-file ./conf/flume-conf.properties --name a1 -Dflume.root.logger=INFO,console
![]()
启动成功

安装kafka
84.解压kafka到/home/kfs/ (以Slave1举例,其他的节点拷贝,并修改环境变量)
cd software
tar -zxvf kafka_2.11-0.10.0.0.tgz -C /home/kfs/
![]()
85.来到kafka的config目录修改server配置文件
cd kafka_2.11-0.10.0.0/config/
vi server.properties

86.修改server.properties配置文件
broker.id=0
host.name=188.2.11.149
port=9092
log.dirs=/home/data/kafka-data/log-0
zookeeper.connect=localhost:2181
![]()
![]()
![]()
![]()
87.将其他kafka的文件夹拷贝到其他节点
scp -r /home/kfs/kafka_2.11-0.10.0.0/ slave2:/home/kfs/
scp -r /home/kfs/kafka_2.11-0.10.0.0/ slave3:/home/kfs/
scp -r /home/kfs/kafka_2.11-0.10.0.0/ slave4:/home/kfs/
scp -r /home/kfs/kafka_2.11-0.10.0.0/ slave5:/home/kfs/
![]()
![]()
![]()
![]()
88.修改其他的配置文件
修改slave2的server.properties

修改slave3的server.properties

修改slave4的server.properties

修改slave5的server.properties

89.启动kakfa服务(分别启动5台,以slave1举例)
./bin/kafka-server-start.sh config/server.properties &
![]()
启动成功

安装spark
90.先安装scala,在root用户下的usr创建一个scala文件夹将scala安装包复制到其中然后解压
cd /usr
mkdir scala
cp /home/kfs/software/scala-2.12.8.tgz /usr/scala/
cd scala/
ls
tar -zxvf scala-2.12.8.tgz

91.修改环境变量
vi /etc/profile
![]()
export SCALA_HOME=/usr/scala/scala-2.12.8
:$SCALA_HOME/bin
![]()
生效配置
source /etc/profile
![]()
92.查看scala版本
scala -version
![]()
93.退回kfs用户,安装spark
exit
cd software/
ls

tar -zxvf spark-2.3.0-bin-hadoop2.7.tgz -C /home/kfs/
![]()
94.来到spark目录下的conf文件夹,修改配置spark-env.sh配置文件
cd
cd spark-2.3.0-bin-hadoop2.7/conf/
cp spark-env.sh.template spark-env.sh
vi spark-env.sh

export JAVA_HOME=/usr/java/jdk1.8.0_144
export SCALA_HOME=/usr/scala/scala-2.12.8
export HADOOP_HOME=/home/kfs/hadoop-2.7.4
export HADOOP_CONF_DIR=/home/kfs/hadoop-2.7.4/etc/hadoop
export SPARK_WORKER_MEMORY=1g
export SPARK_EXECUTOR_MEMORY=600m
export SPARK_DRIVER_MEMORY=600m
export SPARK_WORKER_CORES=1
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoverMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=Slave1:2181,Slave2:2181,Slave3:2181,Slave4:2181,Slave5:2181 -Dspark.deploy.zookeeper.dir=/spark"

95.修改slaves
vi slaves
![]()
Slave1
Slave2
Slave3
Slave4
Slave5

96.复制文件修改配置文件spark-defaults.conf
cp spark-defaults.conf.template spark-defaults.conf
vi spark-defaults.conf
![]()
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master:9000/historyServerforSpark
spark.yarn.historyServer.address Master:18080
spark.history.fs.logDirectory hdfs://master:9000/historyServerforSpark

97.将spark拷贝到其他节点
cd
ls
scp -r spark-2.3.0-bin-hadoop2.7/ slave1:/home/kfs/spark-2.3.0-bin-hadoop2.7/
scp -r spark-2.3.0-bin-hadoop2.7/ slave2:/home/kfs/spark-2.3.0-bin-hadoop2.7/
scp -r spark-2.3.0-bin-hadoop2.7/ slave3:/home/kfs/spark-2.3.0-bin-hadoop2.7/
scp -r spark-2.3.0-bin-hadoop2.7/ slave4:/home/kfs/spark-2.3.0-bin-hadoop2.7/
scp -r spark-2.3.0-bin-hadoop2.7/ slave5:/home/kfs/spark-2.3.0-bin-hadoop2.7/

其他几个拷贝的图片就不截了
98.修改环境变量(以master举例,其他节点也需要修改环境变量)
vi /etc/profile
![]()
export SPARK_HOME=/home/kfs/spark-2.3.0-bin-hadoop2.7
:$SPARK_HOME/bin
![]()
source /etc/profile
![]()
99.回到kfs用户,来到spark目录
exit
cd spark-2.3.0-bin-hadoop2.7/
![]()
100.创建一个软连接(可以忽略)
ln -s spark-2.3.0-bin-hadoop2.7/ spark
![]()
101.启动spark集群
./sbin/start-all.sh
![]()
102.查看master:8080
http://master:8080/

安装Sqoop
103.解压sqoop到/home/kfs目录下(Slave1)
tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /home/kfs/
![]()
104.重命名sqoop,将名称改简短一点
mv sqoop-1.4.7.bin__hadoop-2.6.0/ sqoop-1.4.4
![]()
105.来到conf下将sqoop-env-template.sh复制成sqoop-env.sh
cd sqoop-1.4.7/conf/
cp sqoop-env-template.sh sqoop-env.sh
![]()
106.修改sqoop-env.sh
vi sqoop-env.sh
![]()
export HADOOP_COMMON_HOME=/home/kfs/hadoop-2.7.4
export HADOOP_MAPRED_HOME=/home/kfs/hadoop-2.7.4

source sqoop-env.sh
![]()
107.返回将sqoop-1.4.7.ar复制到 $HADOOP_HOME/share/hadoop/mapreduce/
cd..
ls
cp sqoop-1.4.7.jar $HADOOP_HOME/share/hadoop/mapreduce/

来到$HADOOP_HOME/share/hadoop/mapreduce/看看有没有
cd $HADOOP_HOME/share/hadoop/mapreduce/
ls

108.将JDBC.jar包拷贝到sqlserver和MySQL分别需要用到的jar包拷贝至lib下(自己选择拷贝什么jar)
cd
cd sqoop-1.4.4/lib/

cp /home/kfs/software/sqljdbc4.jar ./
cp /home/kfs/software/mysql-connector-java-8.0.11.jar ./
![]()
ls

109.来到root修改环境变量
su root
vi /etc/profile
![]()
export SQOOP_HOME=/home/kfs/sqoop-1.4.7
:$SQOOP_HOME/bin
![]()
source /etc/profile
![]()
安装Phoenix
110.去到software目录将phoenix解压到/home/kfs(Slave1节点安装)
cd software/
![]()
111.将phoenix目录下的其中三个jar复制到所有节点的hbase的lib目录下
scp phoenix-4.14.1-HBase-1.2-client.jar Slave2:/home/kfs/hbase-1.2.3/lib/
scp phoenix-4.14.1-HBase-1.2-server.jar Slave2:/home/kfs/hbase-1.2.3/lib/
scp phoenix-core-4.14.1-HBase-1.2.jar Slave2:/home/kfs/hbase-1.2.3/lib/
![]()
![]()
![]()
112.将hbase中conf下的hbase-site.xml复制到phoenix的bin覆盖掉原有的配置文件
cp /home/kfs/hbase-1.2.3/conf/hbase-site.xml ./bin/hbase-site.xml
cd bin/
ls

113.去到root用户修改环境变量
su root
vi /etc/profile

export PHOENIX_HOME=/home/kfs/apache-phoenix-4.14.1-HBase-1.2-bin
export PHOENIX_CLASSPATH=$PHOENIX_HOME
:$PHOENIX_HOME/bin

source /etc/profile
![]()
114.为psql和sqlline赋予权限
chmod 777 psql.py
chmod 777 sqlline.py
![]()
115.返回到kfs用户,将hdfs集群的配置文件core和hdfs复制到phoenix的bin目录下
exit

cp /home/kfs/hadoop-2.7.4/etc/hadoop/core-site.xml ./
cp /home/kfs/hadoop-2.7.4/etc/hadoop/hdfs-site.xml ./
![]()
ls

116.启动phoenix测试
./sqlline.py slave1,slave2,slave3,slave4,slave5:2181

!tables 查看所有数据表,!exit退出
安装Storm
117.解压Storm到/home/kfs目录下
tar zxvf apache-storm-1.2.2.tar.gz -C /home/kfs/
![]()
118.修改storm.yaml
cd
ls
cd apache-storm-1.2.2/conf/

vi storm.yaml
![]()
storm.zookeeper.servers:
- "Slave1"
- "Slave2"
- "Slave3"
- "Slave4"
- "Slave5"
storm.local.dir: "/home/data/storm-data/tmp"
nimbus.seeds: ["Slave4", "Slave5"]
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703

119.创建文件夹(Slave1, Slave2, Slave3, Slave4, Slave5节点都需要创建,Slave5举例)
cd /home/data/
mkdir storm-data
ls
cd storm-data
mkdir tmp

120.来到root用户修改环境变量
su root
vi /etc/profile
![]()
export STORM_HOME=/home/kfs/apache-storm-1.2.2
:$STORM_HOME/bin
![]()
source /etc/profile (让配置生效)
![]()
121.返回kfs用户
exit
![]()
122.将storm复制到其他的节点
scp -r /home/kfs/apache-storm-1.2.2/ slave1:/home/kfs/
scp -r /home/kfs/apache-storm-1.2.2/ slave2:/home/kfs/
scp -r /home/kfs/apache-storm-1.2.2/ slave3:/home/kfs/
scp -r /home/kfs/apache-storm-1.2.2/ slave4:/home/kfs/
![]()
![]()
![]()
![]()
123.先启动storm的nimbus再启动supervisor
124.对nimbus的主备节点启动(Slave5, Slave4节点上执行)
nohup sh storm nimbus &
![]()
![]()
125.对nimbus主节点启动(Slave5)
nohup sh storm ui &
![]()
126.对supervisor节点启动(Slave1,Slave2,Slave3,Slave4启动)
nohup sh storm supervisor &
![]()
![]()
![]()
![]()
127.执行logviewer(Slave1,Slave2,Slave3,Slave4,Slave5都启动)
nohup sh storm logviewer &
![]()
![]()
![]()
![]()
![]()
128.查看所有的节点的jps看是否启动成功
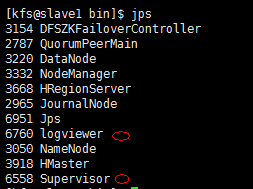


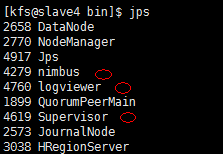

129. 启动网页查看状态
Slave5:8080
