我的工程实践是脱机手写汉字识别相关的,准备借助GoogLeNet作为网络重要模块,在GitHub上找到了基于GoogLeNet的图像分类算法开源项目。
(一)在源代码目录结构、文件名/类名/函数名/变量名等命名、接口定义规范和单元测试组织形式等方面的做法和特点;
代码的目录结构如下:
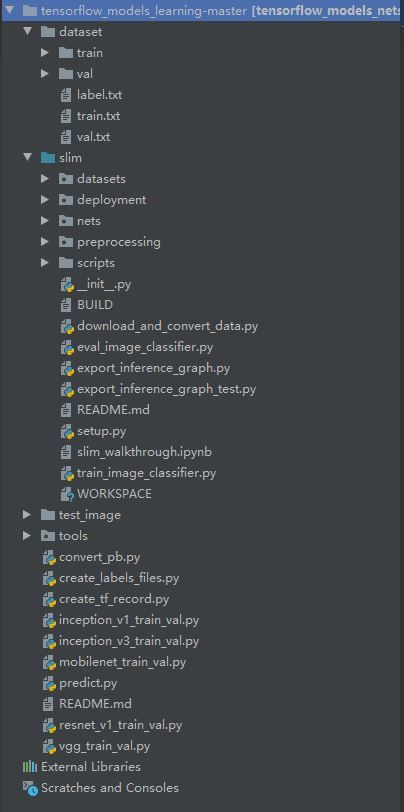
1.文件名命名
dataset中主要存放训练测试数据集,以及相关标签数据;
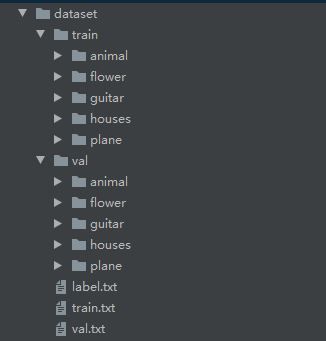
tools中:create_tf_record.py——图片生成训练数据
VGG、inception_v1、inception_v3、mobilenet_v、resnet_v1——训练文件
README.md——项目概要,向读者快速介绍这项工程
predict.py——根据图片预测类别
2.类名/函数名/变量名命名
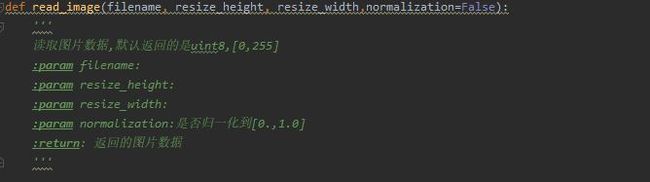
以最基本的读取图片的函数为例,函数名(read_image),变量名(filename/height/width)都清晰明了,注释也相当清晰。
3.接口定义规范
在Python中接口由抽象类和抽象方法去实现,接口是不能实例化的,只能被别的类继承去实现相应的功能。
4.单元测试组织形式
对于test_image中的图片,用predict.py对于网络训练结果进行预测,来测试模型的效果。
(二)哪些做法符合代码规范和风格一般要求;

1.命名规范
命名可读性强,且对于变量的注释详尽,对于其功能和用途的说明清晰到位。
2.缩进规范
代码整体看起来清晰规整,排版缩进等非常整齐。
3.注释规范
注释内容详细,不仅准确描述了“做了什么”,也说明了“为什么这么做”。
(三)列举哪些做法有悖于“代码的简洁、清晰、无歧义”的基本原则,及如何进一步优化改进;

部分代码一行过长,每一行的代码尽量不要超出80个字的长度,超出的回车排版, 方法名的冒号对齐。
(四)总结同类编程语言或项目在代码规范和风格的一般要求。
1.编码
如无特殊情况, 文件一律使用 UTF-8 编码
如无特殊情况, 文件头部必须加入#--coding:utf-8--标识
2.格式
缩进:统一使用 4 个空格进行缩进
行宽:每行代码尽量不超过 80 个字符(在特殊情况下可以略微超过 80 ,但最长不得超过 120) ;
3.空行
模块级函数和类定义之间空两行; 类成员函数之间空一行;
4.空格
在二元运算符两边各空一格[=,-,+=,==,>,in,is not, and];
5.注释
行注释:行注释是与代码语句同行的注释。行注释和代码至少要有两个空格分隔。注释由#和一个空格开始
块注释:“#”号后空一格,段落件用空行分开(同样需要“#”号)
文档注释:作为文档的Docstring一般出现在模块头部、函数和类的头部,这样在python中可以通过对象的__doc__对象获取文档.编辑器和IDE也可以根据Docstring给出自动提示.
6.命名
模块:模块尽量使用小写命名,首字母保持小写,尽量不要用下划线(除非多个单词,且数量不多的情况)
类名:类名使用驼峰(CamelCase)命名风格,首字母大写,私有类可用一个下划线开头
函数名:函数名一律小写,如有多个单词,用下划线隔开
变量名:变量名尽量小写, 如有多个单词,用下划线隔开
常量名:常量使用以下划线分隔的大写命名