K近邻房价评估
k近邻房价预测

import pandas as pd
features=['accommodates','bedroom','bathroom','beds','price','minimum_nights','number_of_reviews']#样本特征,只取全部特征的这些列
dc_listings=pd.read_csv('listings.csv')#读取数据
dc_listings=dc_listings[features]#只取这8个特征的数据
print(dc_listings.shape)#输出(3723,8) 拿到3723条数据,每个数据有8个特征值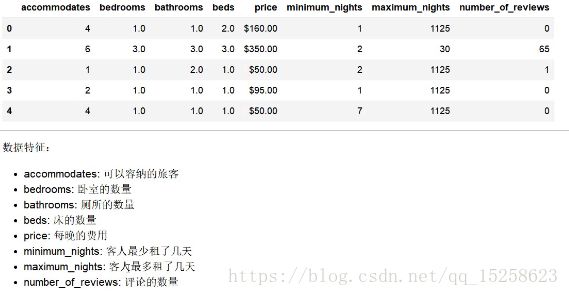
如果有1个房间的房子,能租多少钱?首先,得看看别人都租了多少钱。(看1个房间别人都租了多少钱)
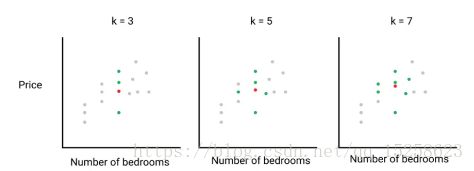
k表示我们的候选对象的个数。也就是和我房间数量最相近的其他房子。
(找3个房间为3的K=3,找5个房间等于3的k=5,以此类推...)
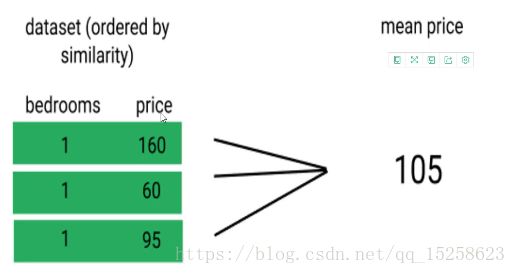
假设数据源中有5个信息,现在我想针对我的房子(只有一个房间)来定一个价格。

现在选K=3,也就是选择3个跟我最近的房源。可以考虑求下平均值。
距离的定义:
如何才能知道哪些数据样本和我最接近呢?采用欧式距离。
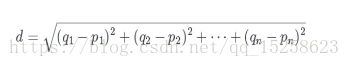
q1-qn为一条数据的所有特征信息,p1-pn为一条数据中的所有特征信息。
假设我们的房子有3个房间。
import numpy as np
our_acc_value=3#房间数量
dc_listings['distance']=np.abs(dc_listings.accommodates-our_acc_value)#特征值为accommodates的值和3作差
dc_listings.distance.value_counts().sort_index()#求对应差值的个数
距离为0,说明房间数量同样为3的房子有461个。
由于刚刚拿到的原始数据,数据分布多多少少存在一些分布规则。需要通过sample操作对数据进行洗牌。
dc_listings=dc_listings.sample(frac=1,random_state=0)
dc_listings=dc_listings.sort_values('distance')
dc_listings.price.head()##显示前五个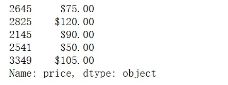
dc_listings['price']=dc_listings.str.replace("\$|,",'').astype(float)
mean_price=dc_listings.price.iloc[:5].mean#求前五个房子价格的均值
mean_price #88.0
这个价格靠谱么? 需要模型进行评估。
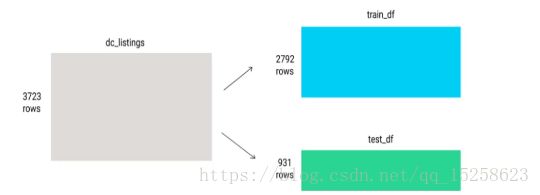
需要将数据集分为训练集和测试集。
#基于单变量预测价格
dc_listings.drop('distance',axis=1)#distance不要了,将其删除
train_df=dc_listings.copy().iloc[:2792]#将前2792个数据作为训练集
test_df=dc_listings.copy().iloc[2792:]#将后2792个数据作为测试集def predict_price(new_listings_value,feature_column):
temp_df=train_df
temp_df['distance']=np.abs(dc_listings[feature_column]-new_listings_value)#真实值和样本中数据值的差值,算好距离
temp_df=temp_df.sort.values('distance')#距离排序
knn_5=temp_df.price.iloc[:5]#取前五个
predict_price=knn_5.mean()#
return(predict_price)
test_df['predict_price']=test_df.accommodates.apply(predict_price,features_column='accommodates')#apply对所有样本执行同样的操作,每个样本都执行了predict_price
#这样便得到样本中所有房子的价格。
test_df['squared_error']=(test_df['predict_price'])-test_df['price']**(2)
mse=test_df['squared_error'].mean()
rmse=mse**(1/2)
rmse#212.989 #得到了一个模型评估得分,for feature in ['accommodates','bedrooms','bathrooms','number_of_reviews']:
test_df['predicted_price']=test_df[feature].apply(predict_price,feature_colomn=feature)
test_df['squared_error'] = (test_df['predict_price']-test_df['price'])**(2)
mse=test_df['squared_error'].mean()
rmse=mse**2
print('RMSE for the {} column: {}').format(feature,rmse)#format的一个feature放进第一个{},rmse放进第二个{}
看起来差异蛮大的,接下来综合所有信息一起进行测试。