Spark分布式集群环境搭建
一、平台环境
虚拟机:VMware Workstation Pro 64位
操作系统:Ubuntu16.04 64位
二、 软件包
Jdk-8u171-linux-x64.tar(java version 1.8.0_171)
Hadoop 2.9.1.tar
Scala-2.11.6
Spark-2.3.1-bin-hadoop2.7
三、Spark分布式集群环境搭建过程
0. 准备工作
首先,我们只建立一台虚拟机出来。待配置好基本通用的配置信息后,我们再克隆出两台来,这样会方便许多。
系统采用的是Ubuntu16.04,虚拟机网络适配器选择NET模式,手动配置静态IP地址,关闭防火墙。
接下来,到网站上下载搭建Spark集群环境所需的各种软件。所有下载的软件都保存在ubuntu16.04的~/spark工作目录下,其绝对路径为:/home/hadoop/spark。
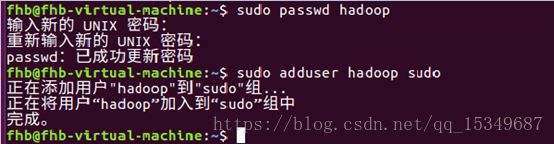
1. 创建hadoop用户
因为之前我的虚拟机上已安装 Ubuntu16.04,但是为了方便,我们需要创建一个新的系统用户名,比如,我新增加了一个名为“hadoop”的用户。其具体过程如下:
创建hadoop用户、设置密码、为hadoop用户增加管理员权限、注销当前用户(点击屏幕右上角的齿轮,选择注销),在登陆界面使用刚创建的 hadoop 用户进行登陆。
按 ctrl+alt+t 打开终端窗口,输入以下命令,完成创建:

2. 修改计算机环境
1) 集群环境:1台master,2台slave,即slave1、slave2
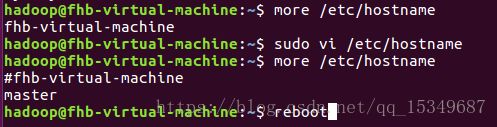
2) 修改主机名hostname,将主机名改为master,并查看修改后的主机名,之后必须重启计算机!!否则执行其他命令时会报错。
![]()
3) 修改自身的IP地址,可通过ifconfig查看修改后的IP地址。

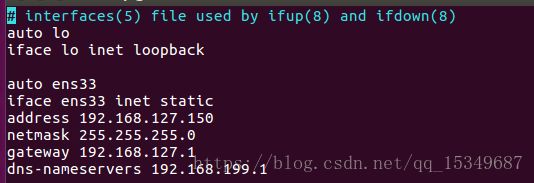
4)修改hosts文件
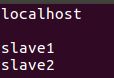
注意:hosts文件里正常会存在一个localhost 及其对应的IP地址,千万不要删除它,直接把以上三行信息给加到后边就行了,删除了localhost,Spark会找不到入口!


3. 更新apt(不是必须的)
使用命令sudo apt-get update进行更新,目的是更新所有的依赖软件,以防后面某些软件安装不成功。如果所有主机 Ubuntu 的软件都是最新的,就不需要这一步了。
4. 安装vim
5. 安装JDK
1) 在~/spark目录下,使用命令tar -zvxf jdk-8u171-linux-x64.tar.gz解压该压缩包。
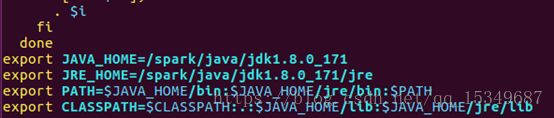
2) 修改环境变量,使用命令sudo vi /etc/profile 修改配置文件,之后使用命令 source /etc/profile,使文件修改生效。
3) 使用命令java –version检查jdk是否安装成功。

6. 安装SCALA
1) 使用命令sudo apt install scala进行在线安装scala
2) 使用命令scala –version检查scala是否安装成功
3) 使用命令which scala查看scala的安装位置路径
4) 与JDK一样,使用命令sudo vi /etc/profile 修改环境变量的配置文件,之后使用命令 source /etc/profile,使文件修改生效。


![]()
7. 安装SSH服务
使用命令sudo apt-get install openssh-server进行安装,SSH具体配置在克隆出两台slave后再配置。
![]()
8. 克隆主机
1) 在配置完上述内容后,集群中节点的通用配置已基本完成。接下来,我们克隆两台slave出来,形成1台master、两台slave(slave1、slave1)的集群环境。
2) 修改克隆出的主机hostname文件及自身IP地址(因为克隆的master,则这里的hosts文件不用修改),必须和hosts文件里的主机名和IP地址要对应,可通过ifconfig查看IP地址(参照第2步)。
3) 重启计算机,使用ping命令,查看修改后的计算机能否连通。


9. 配置master与slave
1) 配置每台主机的SSH免密码登录环境
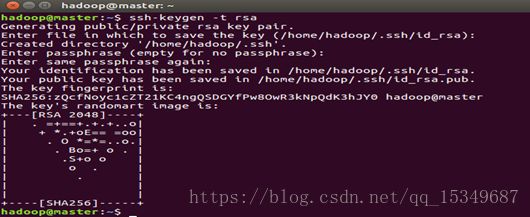
2) 在每台主机上生成公钥和私钥对
3) 将slave1与slave2上的id_rsa.pub发送给master


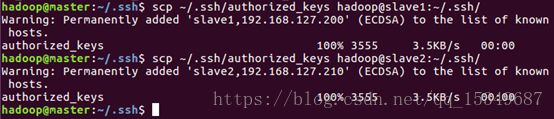
4) 在master上,将所有公钥加载到用于认证的公钥文件authorized_key中,并查看生成的文件。

5) 将master上的公钥文件authorized_key分发给slave1、slave2.
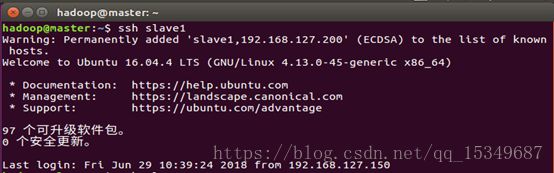
6) 最后使用SSH命令,检验是否能免密码登录。
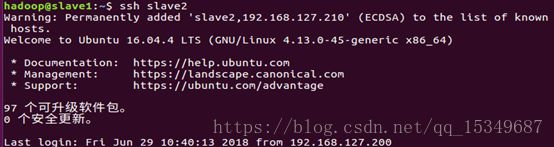
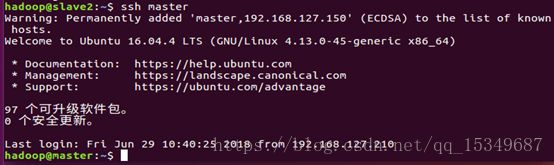
10. 安装hadoop
1) 在~/spark目录下,解压已下载的hadoop压缩包。
2) 使用命令cd spark/hadoop/hadoop-2.9.1/etc/hadoop,进入hadoop配置目录,在该目录下,需要修改配置文件,分别是:hadoop-env.sh , yarn-env.sh , slaves , core-site.xml , hdfs-site.xml , mapred-site.xml , yarn-site.xml 。使用以下命令依次对上述文件进行修改:

![]()
修改hadoop-env.sh,添加JAVA_HOME

修改yarn-env.sh ,添加JAVA_HOME

修改slaves,配置slave节点的ip或hostname
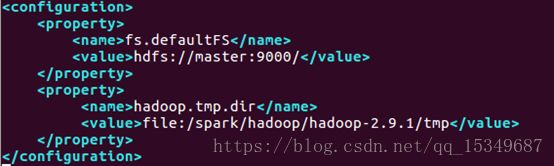
修改core-site.xml
修改hdfs-site.xml
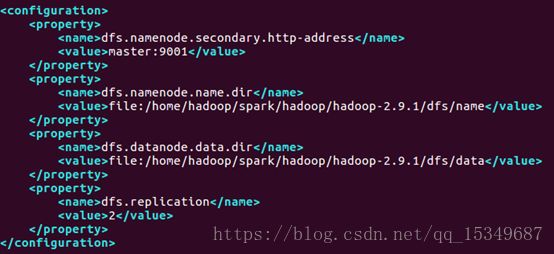
修改mapred-site.xml(先拷贝该文件的模板,再重命名为mapred-site.xml,最后进行修改)
![]()
![]()
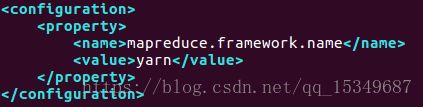
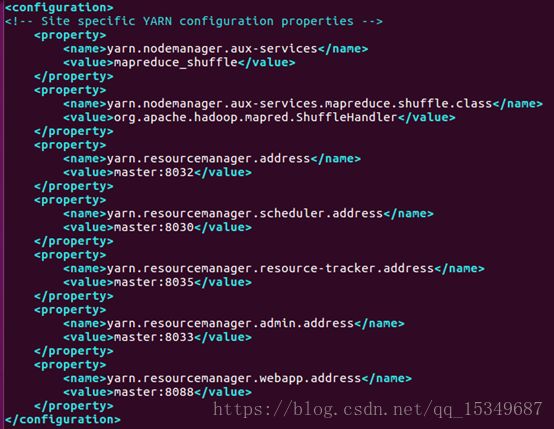
修改yarn-site.xml
3) 将配置好的hadoop-2.9.1文件分发给所有slave。
![]()
![]()
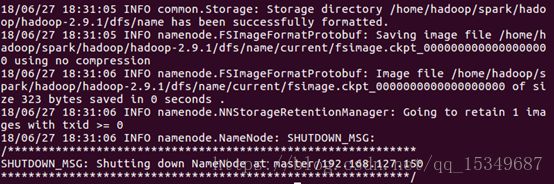
4) 最后,格式化namenode。
![]()
5) 启动hadoop集群
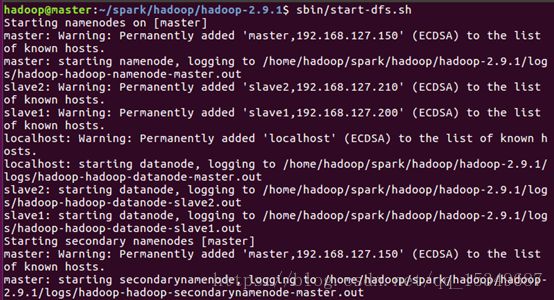
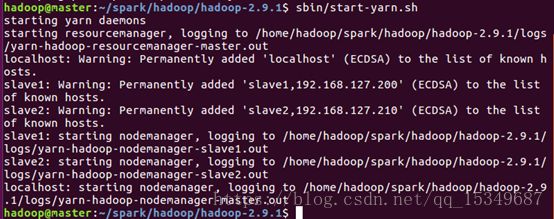
6) 验证hadoop是否安装成功
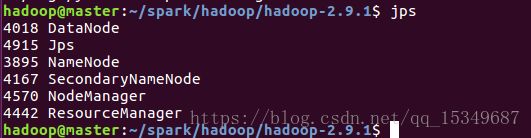
i) 使用jps命令查看hadoop进程。
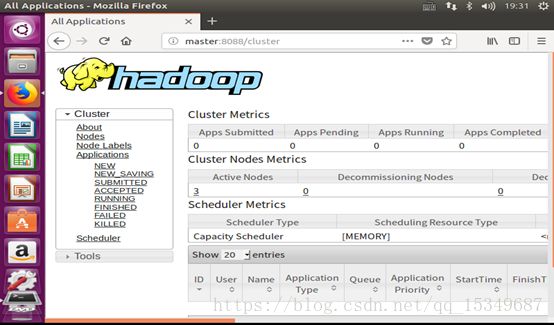
ii) 在浏览器中输入 http://master:8088 能够访问hadoop管理界面。
11. 安装Spark
1) 在~/spark目录下,解压已下载的spark压缩包。
2) 使用命令cd spark/spark-2.3.1/conf,在该目录下,看到很多文件都是以template结尾的,这是因为spark给我们提供的是模板配置文件,我们可以先拷贝一份,然后将.template给去掉,变成真正的配置文件后再编辑。
3) 配置spark-env.sh,该文件包含spark的各种运行环境。


4) 配置slaves文件
![]()

5) 将配置好的spark-2.3.1文件分发给所有slave。
![]()
![]()
6) 启动spark集群
i) 使用命令cd spark/hadoop/hadoop-2.9.1进入hadoop目录,在该目录下,启动 hadoop 文件管理系统 HDFS以及启动 hadoop 任务管理器 YARN。
ii) 启动 spark
![]()
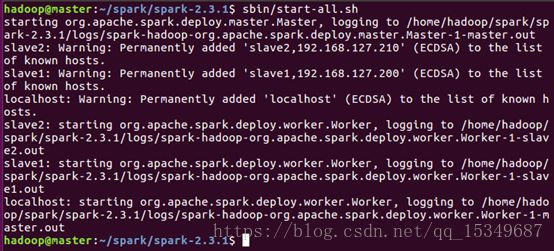
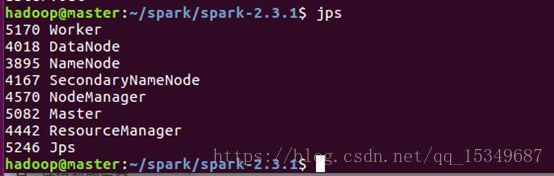
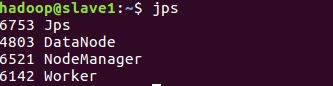
7) 查看Spark集群信息
i) 使用jps命令查看spark进程。
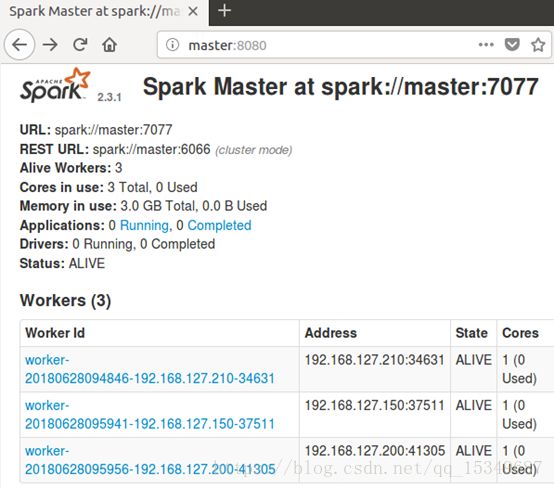
ii) 查看spark管理界面,在浏览器中输入:http://master:8080
8) 运行 spark-shell,可以进入 Spark 的 shell 控制台。
9) 停止运行集群
停止集群时,运行sbin/stop-all.sh停止Spark集群,运行sbin/stop-dfs.sh来关闭hadoop 文件管理系统 HDFS,最后运行sbin/stop-yarn.sh来关闭hadoop 任务管理器 YARN。
四、Spark运行示例
使用Spark shell的交互式方式分析数据
1. 加载本地文件到HDFS中
1) 使用命令bin/hdfs dfs -mkdir -p /data/input ,即在虚拟分布式文件系统上创建一个测试目录/data/input
2) 使用命令hdfs dfs -put README.txt /data/input ,即将/hadoop-2.9.1目录下的README.txt文件复制到虚拟分布式文件系统中
3) 使用命令bin/hdfs dfs -ls /data/input ,即查看HDFS文件系统中是否存在我们所复制的文件

2. 在spark-shell 窗口,编写scala语句,将从HDFS中加载README.txt文件,并对该文件作简单分析
1) 首先,将README.txt的文件打开,可以看到里面的内容,如下所示:

2) 在spark-shell窗口上,通过使用count()、first()、collect()等操作,来对README.txt进行分析
i) 从HDFS中加载README.txt文件
![]()
ii) Count()操作的含义:RDD 中的 item 数量,对于文本文件来说,就是其总行数。First()的含义:RDD 中的第一个 item,对于文本文件,就是指其第一行内容,与第1步骤中的第一行内容一样,说明没出错。

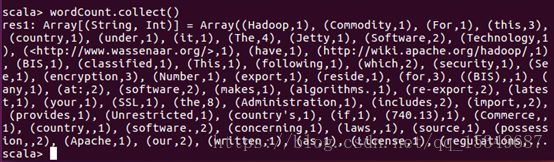
iii) 使用collect(),对文件进行词数统计