Python pandas数据分析中常用方法
官方教程
读取写入文件
官方IO
读取 写入
read_csv to_csv
read_excel to_excel
read_hdf to_hdf
read_sql to_sql
read_json to_json
read_msgpack (experimental) to_msgpack (experimental)
read_html to_html
read_gbq (experimental) to_gbq (experimental)
read_stata to_stata
read_sas
read_clipboard to_clipboard
read_pickle to_pickle//速度比csv快
读取CSV文件:
pd.read_csv('foo.csv') //读取CSV
# header参数指定从第几行开始生成,且将header行的数据作为列的name(键),header行以前的数据将不会处理。取值为None表示csv中行不做为列的name(键),取值为0表示将csv的第0行作为列的name。| 如果没有传递参数names那么header默认为0;如果传递参数names,那么header默认为None。
存储为csv文件:
submission = pd.DataFrame({ 'PassengerId': test_df['PassengerId'],'Survived': predictions })
submission.to_csv("submission.csv", index=False)
# index参数是否写入行names键
从dict生成:
pd.DataFrame.from_dict(df, orient='index')
选择数据
官方选择教程
官方多index选择教程
[]:
df['A'] 通过列name(键)选择列
df[['A', 'B']] 通过list选择列
df[0:3] 通过隐含的序列(index所在行值)选择行
df['20130102':'20130104'] 通过行index(键)选择行
dataset[(dataset['Sex'] == i) & (dataset['Pclass'] == j+1)]['Age'] #布尔运算选择数据,以其他列为条件筛选数据,注意做布尔运算时最好将每个运算用括号括起来,像以下这种就会容易出问题:dataset[dataset['TARGET'].notnull() & dataset['need_pre']!=1 ]
加不加[],生成的类型是不同的
type(data["A1"])
pandas.core.series.Series
type(data[["A1"]])
pandas.core.frame.DataFrame
loc:
dataset.loc[ dataset.Age.isnull(),'BB'] //age不是null的数据中选择BB列
train_df.loc[:, ['Age*Class', 'Age', 'Pclass']].head(10)
dataset.loc[ EID,'Age'] //根据index(注意这个是index的取值,而不是index所在行)选取列Age单元数据
iloc:
iloc是选择DataFrame第几行第几列(类似于数组,数值下标从0开始)
df.iloc[3:5,0:2]
df.iloc[1:3,:]
df.iat[1,1]
Multi-index索引:
In [536]: result_df = df.loc[(df.index.get_level_values('A') > 1.7) & (df.index.get_level_values('B') < 666)]
In [537]: result_df
Out[537]:
C
A B
3.3 222 43
333 59
5.5 333 56
In [17]: df.query('0 < A < 4 and 150 < B < 400')
Out[17]:
C
A B
1.1 222 40
3.3 222 20
333 11
x = df.reset_index()
In [16]: x.loc[(x.B>=111.0)&(x.B<=500.0)].set_index(['A','B'])
Out[16]:
C
A B
1.1 111 81
222 45
3.3 222 98
333 13
5.5 333 89
循环行数据:
for i, row in colTypes.iterrows():
# i为dataFrame的index,row为一行数据
使用另一series作为dataframe的筛选条件:
import numpy as np
import pandas as pd
df = pd.DataFrame({ 'A' : [1,2,3,4],
'B' : [4,5,6,7]
})
a = pd.Series([1,2,3,1])
# 对series进行筛选
(a==1).sum()
>>>2
# 对dataframe进行筛选
df[a==1].sum(0)
>>>
A 5
B 11
dtype: int64
判断是否在序列中筛选:
meta_df = meta_df[meta_df['asin'].isin( reviews_df['asin'].unique() )]
new_rate = new_rate[~new_rate['reviewerID'].isin(low_index)] # not in,取反
计算数据
重复数值个数统计:
Series.value_counts() //统计重复重现的数据的个数。返回以数据作为key,以重复个数为value的对象。
X[c].value_counts().index[0] //最多的那个数
中值计算:
Series.median() //计算某个轴的中值
计算均值和偏差:
age_mean = guess_df.mean()
# 计算均值
age_std = guess_df.std()
# 计算标准差
计算众值:
# freq_port = train_df.Embarked.dropna().mode()[0]
# mode返回出现最多的数据,可能出现多个,因此返回数组
其他:
方法 说明
count 非NA值得数量
describe 针对series或各dataframe列计算汇总统计
min max 计算最小值和最大值
argmin,argmax 计算能够获取到最小值和最大值的索引位置(整数)
much_nuclei = df_img['nuclei'].argmax()
plt.imshow(imgs[much_nuclei])
idxmin , idxmax 计算获取到最小值和最大值索引值
df.idxmax() //按列
df.idxmax(axis=1) //按行
quantile 计算样本的分位数(0到1)
sum 值得总和
df.sum() //按列求和
df.sum(axis=1) //按行求和
mean 值得平均数
df.mean(axis=1) //按行求和,注意,如果存在Nan值会忽略,如果整个都为nan,则取nan
df.mean(axis=1, skipna = False) //禁止忽略nan值
median 值的算数中位数
mad 根据平均值计算平均绝对离差
var 样本值得方差
std 样本值得标准差
skew 样本值得偏度(三阶矩)
kurt 样本值的峰度(四阶矩)
cumsum 样本值的累计和,累计累积,也就是说从开始位置到当前位置的总和
df.cumsum() //按列求累积和,如果当前位置为nan,直接返回nan,如果不是,而前面某个位置是,则忽略前面位置的nan
df.cumsum(axis=1) //按行求累积和
cummin,cummax 样本值的累计最大值和累计最小值
cumprod 样本值的累计积
diff 计算一阶差分(对时间序列很有用)
pct_change 计算百分数变化
isin 判断series,dataframe数据是否在另一个变量其中
缺失值处理
性质:
np.nan == np.nan
>>> False
np.isnan(np.nan)
>>> True
np.nan is None
>>> False
type(np.nan)
>>> float
检测:
np.isnan(df)
pd.isnull(df)
方法 说明
count 非NA值得数量
dropna 根据各标签的值中是否存在缺失数据对轴标签进行过滤,可通过阈值调节对缺失值得容忍度
fillna 用指定值或插值方法(如ffill或bfill)填充确实数据
isnull 返回一个含有布尔值的对象,这些布尔值表示哪些值是缺失值/NA,该对象的类型与源类型一样
notnull isnull的否定式
存在三种方法来完善连续数字特征:
1、简单方式:在中值和标准偏差间产生一个随机数
2、准确方式:通过相关特征猜测缺失值
3、联合1、2基于特征组合,在中值和偏差间产生一个随机数
显示缺失值行列:
train_cat[train_cat.isnull().values==True]
判断某列是否包含nan:
df.isnull().any() # 判断列是否有 NaN
df.isnull().all() # 判断列是否全部为NaN
删除缺失行:
df.dropna(axis=0, how='any', inplace=True)
缺失值填充:
dataset['E'] = dataset['E'].fillna(f)
# 对缺失值处进行填充0,参数value可为 scalar, dict, Series, 或者DataFrame,但不能是list;Series应用于每个index,DataFrame应用于每个列。如果不在dict/Series/DataFrame中,将不会被填充
清除空值:.dropna()
dataset.loc[ (dataset.Age.isnull()) & (dataset.Sex == i) & (dataset.Pclass == j+1),'Age'] = guess_ages[i,j]
# 多条件填充
方法1:
for dataset in full_data:
age_avg = dataset['Age'].mean()
age_std = dataset['Age'].std()
age_null_count = dataset['Age'].isnull().sum()
age_null_random_list = np.random.randint(age_avg - age_std, age_avg + age_std, size=age_null_count)
dataset['Age'][np.isnan(dataset['Age'])] = age_null_random_list
dataset['Age'] = dataset['Age'].astype(int)
方法3:
# 生成一个空数组来存储Age的猜测值:
# guess_ages = np.zeros((2,3))
# guess_ages
# 遍历Sex和Pclass来猜测Age猜测值:
# for dataset in combine:
# for i in range(0, 2):
# for j in range(0, 3):
# guess_df = dataset[(dataset['Sex'] == i) & (dataset['Pclass'] == j+1)]['Age'].dropna()
# 根据相关特征值Pclass,Sex选取数据并除空值
# age_mean = guess_df.mean()
# 计算均值
# age_std = guess_df.std()
# 计算标准差
# age_guess = rnd.uniform(age_mean - age_std, age_mean + age_std)
# 产生随机值
# age_guess = guess_df.median()
# 或计算中值
# Convert random age float to nearest .5 age
# guess_ages[i,j] = int( age_guess/0.5 + 0.5 ) * 0.5
for i in range(0, 2):
for j in range(0, 3):
dataset.loc[ (dataset.Age.isnull()) & (dataset.Sex == i) & (dataset.Pclass == j+1),'Age'] = guess_ages[i,j]
# 赋值
dataset['Age'] = dataset['Age'].astype(int)
填充众值:
# freq_port = train_df.Embarked.dropna().mode()[0]
# mode返回出现最多的数据,可能出现多个,因此返回数组
# 填充:
# for dataset in combine:
# dataset['E'] = dataset['E'].fillna(freq_port)
查看数据
查看键和值:
train_data = pd.read_csv('train.csv')
# 查看数据的行键index(index.values)、列键columns(columns.values)、值values
print(train_data.index)
print(train_data.index.values)
查看数据统计:
train_data.info()
# 主要统计有各列键非空数据数量(便于后面填充空值)、各列数据类型、及数据类型统计(一般object表示字符串对象数量)。
print(train_data.describe())
# 默认统计数值型数据每列数据平均值,标准差,最大值,最小值,25%,50%,75%比例。
print(train_data.describe(include=['O']))
# 统计字符串型数据的总数,取不同值数量,频率最高的取值。其中include参数是结果数据类型白名单,O代表object类型,可用info中输出类型筛选。
print("Before", train_data.shape)
# 数据行数和列数
查看部分数据内容:
# 查看前五条和后五条数据,大致了解数据内容
print(train_data.head())
print(train_data.tail())
# 选取三条数据
data_train.sample(3)
排序:
features.sort_values(by='EID', ascending=True)
features.sort_index(axis=1, ascending=True)
python原生排序list和dict
sorted([wifi for wifi in line[5]], key=lambda x:int(x[1]), reverse=True)[:5] // 默认从小到大
sorted(dict.items(),key=lambda x:x[1],reverse=True)[0][0]
sorted(L, cmp=lambda x,y:cmp(x[1],y[1])) //x,y代表前后两个元素
输出格式控制:
pandas dataframe数据全部输出,数据太多也不用省略号表示。
pd.set_option('display.max_columns',None)
或者
with option_context('display.max_rows', 10, 'display.max_columns', 5):
某列字符长度统计
lens = train.comment_text.str.len()
lens.mean(), lens.std(), lens.max()
print('mean text len:',train["comment_text"].str.count('\S+').mean())
print('max text len:',train["comment_text"].str.count('\S+').max())
分析数据相关性
groupby数据:
train_data[['Pclass','Survived']].groupby(['Pclass'], as_index=False).mean().sort_values(by='Survived',ascending=False)
# 选取数据中两列,以Pclass分组,计算每个分组内平均值,最后根据Survived平均值降序排列。其中as_index=False不以Pclass做结果行键。
分组后,可以通过size()分组内数据数量,sum()分组内数据和,count()分组内:
df = DataFrame({'key1':['a','a','b','b','a'],'key2':['one','two','one','two','one'],'data1':np.random.randn(5),'data2':np.random.randn(5)})
df
#[Out]# data1 data2 key1 key2
#[Out]# 0 0.439801 1.582861 a one
#[Out]# 1 -1.388267 -0.603653 a two
#[Out]# 2 -0.514400 -0.826736 b one
#[Out]# 3 -1.487224 -0.192404 b two
#[Out]# 4 2.169966 0.074715 a one
group2 = df.groupby(['key1','key2'])
group2.size()
#[Out]# key1 key2
#[Out]# a one 2 //注意size返回的对象2,1,1,1没有列键
#[Out]# two 1
#[Out]# b one 1
#[Out]# two 1
#[Out]# dtype: int64
group2.count()
#[Out]# data1 data2
#[Out]# key1 key2
#[Out]# a one 2 2 //注意count返回的对象2,1,1,1有列键data1,data2
#[Out]# two 1 1
#[Out]# b one 1 1
#[Out]# two 1 1
group2.sum()
data1 data2
key1 key2
a one 0.222249 1.188488
two 0.627373 0.406101
b one -2.527461 0.267850
two -0.594238 -0.137129
自定义组内统计函数:
BRA_CLOSE_DECADE = branch2[['EID', 'B_ENDYEAR']].groupby('EID').agg(lambda df:df[df['B_ENDYEAR']>2007].count())
分组后循环:
for reviewerID, hist in reviews_df.groupby('reviewerID'):
pos_list = hist['asin'].tolist()
crosstab数据:

pd.crosstab(train_data['Title'], train_data['Sex'])
# 分别以Title(Mrs,Mr等)为行,Sex(female,male)为例,计算出现频数。观察二者的对应关系。
Pivot数据:
impute_grps = data.pivot_table(values=["LoanAmount"], index=["Gender","Married","Self_Employed"], aggfunc=np.mean)

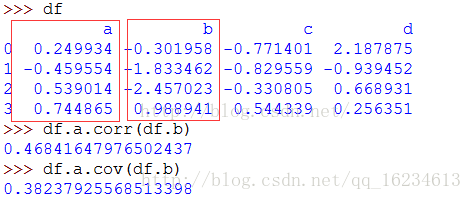
COV(),CORR()计算
协方差cov():表示线性相关的方向,取值正无穷到负无穷。协方差为正值,说明一个变量变大另一个变量也变大;协方差取负值,说明一个变量变大另一个变量变小,取0说明两个变量咩有相关关系。
相关系数corr():不仅表示线性相关的方向,还表示线性相关的程度,取值[-1,1]。也就是说,相关系数为正值,说明一个变量变大另一个变量也变大;取负值说明一个变量变大另一个变量变小,取0说明两个变量没有相关关系。同时,相关系数的绝对值越接近1,线性关系越显著。
corrwith():计算DataFrame的列(axis=0,默认)或行(axis=1)跟另外一个Series或DataFrame之间的相关系数。

删除数据
print(df.drop(0,axis=0)) #删除行,注意原数据不变,返回一个新数据
print(df.drop(['col1'],axis=1,inplace=True)) #删除列,inplace=True表示直接在原数据修改而不新建对象
合并数据
对于不同列名,但是内容相同时,可以先修改表的列名。
concat:
相同字段的表首尾相接
result = pd.concat([df1, df2, df3], keys=['x', 'y', 'z']) //keys给合并的表来源加一个辨识号
注意多张表concat后可能会出现index重复情况,这是最好使用reset_index重新组织下index。
result.reset_index(drop=True)
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False)
append方式:
# append方式
result = df1.append([df2, df3]) //将df2,df3追加到df1后返回
# [官方合并教程](http://pandas.pydata.org/pandas-docs/stable/merging.html#)
merge方式:
merge(left, right, how=‘inner’, on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=True, suffixes=(’_x’, ‘_y’), copy=True, indicator=False)
merge方式用于通过一个或多个键将两个数据集的行连接起来,类似于 SQL 中的 JOIN
on=None 用于显示指定列名(键名),如果该列在两个对象上的列名不同,则可以通过 left_on=None, right_on=None 来分别指定。或者想直接使用行索引作为连接键的话,就将left_index=False, right_index=False 设为 True。如果没有指定且其他参数也未指定则以两个DataFrame的列名交集做为连接键.
how=‘inner’ 参数指的是当左右两个对象中存在不重合的键时,取结果的方式:inner 代表交集;outer 代表并集;left 和 right 分别为取一边。
suffixes=(’_x’,’_y’) 指的是当左右对象中存在除连接键外的同名列时,结果集中的区分方式,可以各加一个小尾巴。
对于多对多连接,结果采用的是行的笛卡尔积。
# merge方式
# 其中how取值 : {‘left’, ‘right’, ‘outer’, ‘inner’}, default ‘inner’类似于SQL中 left outer join,right outer join, full outer join,inner join
>>> A >>> B
lkey value rkey value
0 foo 1 0 foo 5
1 bar 2 1 bar 6
2 baz 3 2 qux 7
3 foo 4 3 bar 8
>>> A.merge(B, left_on='lkey', right_on='rkey', how='outer')
lkey value_x rkey value_y
0 foo 1 foo 5
1 foo 4 foo 5
2 bar 2 bar 6
3 bar 2 bar 8
4 baz 3 NaN NaN
5 NaN NaN qux 7
join方式:
其中参数的意义与merge方法基本相同,只是join方法默认为左外连接how=left。默认按索引合并,可以合并相同或相似的索引。主要用于索引上的合并
join(self, other, on=None, how='left', lsuffix='', rsuffix='',sort=False):
修改数据
从数据中提取数据:
dataset['Title'] = dataset.Name.str.extract(' ([A-Za-z]+)\.', expand=False)
# 左边dataset['Title']为DataFrame添加一列,右边dataset.Name取出DataFrame的name列,然后对于该Series里的string匹配正则,返回匹配到的正则子集。[官方api](http://pandas.pydata.org/pandas-docs/stable/generated/pandas.Series.str.extract.html)
# 对列使用函数处理
meta_df['categories'] = meta_df['categories'].map(lambda x: x[-1][-1])
data['sum_Times']=data['Times'].groupby(['userID']).cumsum() //统计单个userid组内到当前行之前的所有time和
替换数据:
dataset['Title'] = dataset['Title'].replace('Ms', 'Miss')
dataset['Title'].replace('Ms', 'Miss')
#将一列中数据Ms替换Miss,[详解](https://jingyan.baidu.com/article/454316ab4d0e64f7a6c03a41.html)
将分类数据数值化:
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5}
for dataset in combine:
dataset['Title'] = dataset['Title'].map(title_mapping)
# dataset['Sex'] = dataset['Sex'].map( {'female': 1, 'male': 0} ).astype(int)
转成矩阵:
big_X_imputed[0:train_df.shape[0]].as_matrix() //将DataFrame对象转成numpy矩阵
将连续值分成几部分:
# 自动
pd.cut(np.array([.2, 1.4, 2.5, 6.2, 9.7, 2.1]), 3,
labels=["good","medium","bad"])
[good, good, good, medium, bad, good]
# 手动,一般手动前先自动分析一波。
# train_df['AgeBand'] = pd.cut(train_df['Age'], 5)
# train_df[['AgeBand', 'Survived']].groupby(['AgeBand'], as_index=False).mean().sort_values(by='AgeBand', ascending=True)
# 手动区分
# for dataset in combine:
# dataset.loc[ dataset['Age'] <= 16, 'Age'] = 0
# dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 32), 'Age'] = 1
# dataset.loc[ dataset['Age'] > 64, 'Age'] = 4
对每一行或每一列应用函数:
def num_missing(x):
return sum(x.isnull())
#应用列:
print data.apply(num_missing, axis=0)
#应用行:
print data.apply(num_missing, axis=1).head()
def get_title(name):
title_search = re.search(' ([A-Za-z]+)\.', name)
# If the title exists, extract and return it.
if title_search:
return title_search.group(1)
return ""
for dataset in full_data:
dataset['Title'] = dataset['Name'].apply(get_title)
df.Cabin = df.Cabin.apply(lambda x: x[0])
将字符型数据转成数值型数值:
from sklearn import preprocessing
def encode_features(df_train, df_test):
features = ['Fare', 'Cabin', 'Age', 'Sex', 'Lname', 'NamePrefix']
df_combined = pd.concat([df_train[features], df_test[features]])
for feature in features:
le = preprocessing.LabelEncoder()
le = le.fit(df_combined[feature])
df_train[feature] = le.transform(df_train[feature])
df_test[feature] = le.transform(df_test[feature])
return df_train, df_test
data_train, data_test = encode_features(data_train, data_test)
除去离群点:
通过画图如果发现数据中出现一些离群点,应将其除去,使用pandas布尔运算即可:
train = train[abs(train['length'])<10]
categorial无序特征哑编码one-hot:
星期为无序特征,如果该特征有三种取值:星期一、星期二、星期三,那么可用三维向量分别表示(1,0,0)(0,1,0)(0,0,1)。使用pd.get_dummies(),如果特征取值过多就应根据数据分布规律将不重要的几个取值归为一类。

去重相同行:
alter.duplicated() //返回每行是否重复的bool值,frame.duplicated(['state'])可选择指定列进行查重。
alter.duplicated().value_counts()
alter2 = alter.drop_duplicates() //除去相同行,注意返回新数据,而不是在旧有的上面修改
df.drop_duplicates(subset='column A', keep='last') //根据特定列去重,且保留最后一个
修改index名,列键名:
df.columns = ['a', 'b', 'c', 'd', 'e']
df.columns = df.columns.str.strip('$')
df.columns = df.columns.map(lambda x:x[1:])
df.rename(columns=('$a': 'a', '$b': 'b', '$c': 'c', '$d': 'd', '$e': 'e'}, inplace=True)
df.rename(columns=lambda x:x.replace('$',''), inplace=True)
investFeature.index.rename('EID', inplace=True)
列转index、index转列:
df.set_index('date', inplace=True)
df['index'] = df.index
df.reset_index(level=0, inplace=True)
df.reset_index(level=['tick', 'obs'])
df['si_name'] = df.index.get_level_values('si_name') # where si_name is the name of the subindex.
删除index
df_load.reset_index(inplace=True)
del df_load['index']
合并列名不同的列:
先修改列名
train_cat = train[[0,1,2,3,4]]
col = train_cat.columns
for i in range(5,20,4):
tem = train[[0,i,i+1,i+2,i+3]]
tem.columns = col
train_cat = pd.concat([train_cat,tem])
train_cat.head()
设置一列类型:
df[[column]] = df[[column]].astype(str)
深浅复制:
Shallow copy shares data and index with original.
Deep copy has own copy of data and index.
Updates to the data shared by shallow copy and original is reflected in both; deep copy remains unchanged.
deep = s.copy()
shallow = s.copy(deep=False)
apply返回series数据:
这样组合成的仍然是dataframe类型
def mer(x):
sss = []
for i,line in x.iterrows():
sss.extend([line[1],line['pre']])
return pd.Series(sss)
merged = sub_cat.groupby([0]).apply(mer)
根据键值和列名合并:
save.merge(merged, left_on=['a'], right_index=True)
groupby后筛选数据:
使用filter或transform
np.random.seed(130)
df=pd.DataFrame(np.random.randint(3, size=(10,2)), columns=['item_id_copy','sales_quantity'])
print (df)
item_id_copy sales_quantity
0 1 1
1 1 2
2 2 1
3 0 1
4 2 0
5 2 0
6 0 1
7 1 2
8 1 2
9 1 2
df1 = df.groupby('item_id_copy').filter(lambda x: len(x["asin"].unique()) >= 4)
print (df1)
item_id_copy sales_quantity
0 1 1
1 1 2
7 1 2
8 1 2
9 1 2
df1 = df[df.groupby('item_id_copy')['sales_quantity'].transform('size') >= 4]
print (df1)
item_id_copy sales_quantity
0 1 1
1 1 2
7 1 2
8 1 2
9 1 2
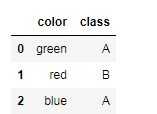
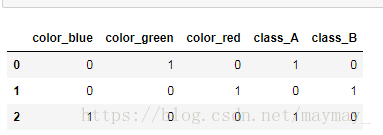
pandas进行one-hot编码:
import pandas as pd
df = pd.DataFrame([
['green' , 'A'],
['red' , 'B'],
['blue' , 'A']])
df.columns = ['color', 'class']
df = pd.get_dummies(df)
one-hot后:
apply返回多列:
def myfunc1(row):
C = row['A'] + 10
D = row['A'] + 50
return pd.Series([C, D])
df[['C', 'D']] = df.apply(myfunc1 ,axis=1)
def sizes(s):
return locale.format("%.1f", s / 1024.0, grouping=True) + ' KB', \
locale.format("%.1f", s / 1024.0 ** 2, grouping=True) + ' MB', \
locale.format("%.1f", s / 1024.0 ** 3, grouping=True) + ' GB'
df_test['size_kb'], df_test['size_mb'], df_test['size_gb'] = zip(*df_test['size'].apply(sizes))
按列最大最小值归一化
In [11]: df
Out[11]:
a b
A 14 103
B 90 107
C 90 110
D 96 114
E 91 114
In [12]: df -= df.min()
In [13]: df /= df.max()
In [14]: df
Out[14]:
a b
A 0.000000 0.000000
B 0.926829 0.363636
C 0.926829 0.636364
D 1.000000 1.000000
E 0.939024 1.000000
判断一列数据是不是类型混合:
sorted(sad["size"].unique())
'<' not supported between instances of 'str' and 'float'
对df的某一行的某些值进行修改:
aad.loc[aad["type"]==2,"cdate"] = aad.loc[aad["type"]==2,"adid"].map(lambda x: cdate_map[x] if x in cdate_map.keys() else -1)
groupby 后提取前多少数据,并生成pandas
orgin = reviews_map.sort_values(["reviewerID","unixReviewTime"]).groupby("reviewerID",group_keys=False)
print(orgin.get_group(1))
history = orgin.apply(lambda df: df[:-2])
ads = orgin.apply(lambda df: df[-2:])