Innodb引擎,MySQL修改参数
InnoDB是事务安全的MySQL存储引擎,设计上采用了类似了Oracle数据库的架构。通常来说,InnoDB存储引擎是OLTP应用中核心表的首选存储引擎。同时,也正是因为InnoDB的存在,才使MySQL数据库变得更有魅力。
InnoDB存储引擎概述:
InnoDB存储引擎最早由Innobase Oy公司开发,被包括在MySQL数据库所有的二进制发行版本中,从MySQL5.5版本开始是默认的表存储引擎(之前的版本InnoDB存储引擎仅在Windows下为默认的存储引擎)。该存储引擎是第一个完整支持ACID事务的MySQL存储引擎(BDB是第一个支持事务的MySQL存储引擎,现在已经停止开发),其特点是:行锁设计、支持MVCC、支持外键、提供一致性非锁定读,同时被设计用来最有效地利用以及使用内存和CPU。
==============引擎,是基于表实现的。
存储引擎:
- 1.在建立表的时候,会选择存储引擎engine
- 2.mysql支持多种存储引擎,每一种存储引擎有自己的独立的特色,面向不同的使用场景。
(现在大部分场景在用InnoDB引擎)
mysql经典版本:
5.1
5.5
5.6
5.7
=====看mysql版本的方法:
- ①select version();
- ②show variables like ‘%version%’;
- ③刚开始登录的时候。
show engines; --》查看所有引擎
===
mysql> show engine innodb status \G;
=====InnoDB引擎(也有版本)的特点:
- 1.支持行锁(各干各的活,互不影响)、并发性能好;
- 2.支持MVCC(多版本并发控制Multi-Version Concurrency Control)(避免使用锁);
- 3.支持外键(核心:在外表上插入一个值时,要在主表上有才能插入;在主表上查询时,外表上要有相关的引用);
- 4.提供一致性非锁定读,并发性能更强;
- 5.能够使用大内存和充分利用cpu资源。
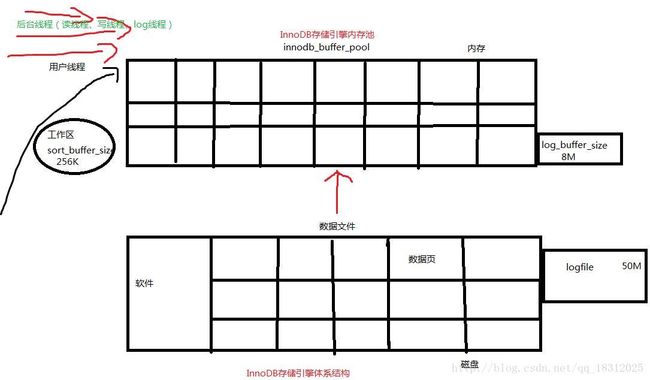
=======InnoDB体系架构
下图简单显示了InnoDB的存储引擎的体系结构,从图可见,InnoDB存储引擎有多个内存块,可以认为这些内存块组成了一个大的内存池,负责以下工作:
- 维护所有进程/线程需要访问的多个内部数据结构;
- 缓存磁盘上的数据,方便快速地读取,同时在对磁盘文件的数据修改之前在这里缓存。
- 重做日志(redo log)缓冲。
- ……

====InnoDB存储引擎体系结构讲到了:
- 1.用户线程
- 2.后台线程
- 读线程、写线程、log线程
- 3.innodb buffer pool(数据缓存池)
- 4.log buffer
- 5.logfile
===========
mysql
server:版本
innodb:版本
软件:rdbms(数据库管理系统)
实例:instance:内存和线程
数据库:database:一般情况,一个数据库对应一个实例;
发现这台服务器的资源占用率大约在20%左右(不忙)(正常80%左右最好)。此时,需要加入10个新服务,需要10台服务器:
【在一台mysql服务器上安装2个mysql实例库,可选择相同端口或不同端口】

==============
详细描述一下commit的过程和rollback的过程,为什么commit速度总是那么快,rollback很多时候执行的很慢,可能非常慢:
commit的过程为啥显得那么快?
答:commit过程很快,当用户要修改一万行表时,首先在工作区sort_buffer_size(256K)产生大量的redo log,redo log大量的写入到log_buffer_size中,但logbuffer很小(8M),存不下大量的redolog,但是logbuffer有很多的工作机制,比如
- ①数据大于4M(1/2)时会写到logfile;
- ②每秒会写入logfile;
- ③commit时也会写入到logfile。
但产生的大量脏块是在后台慢慢写入到磁盘的,所以commit时,会感觉速度很快。因为logbuffer中并没有太多的东西。
下面是图解:

=======Rollback很多时候执行的很慢,为什么?
答:rollback时,首先要通过命令start TRANSACTION开启一个事务,在这个事务中执行的sql不会commit。所以可以rollback,在rollback时,首先要读取大量的undo,之后在执行sql,这个sql是之前sql相反的操作,之后产生大量的redo,在敲下rollback按下回车时(也就是事物结束之时)会自动回滚并且自动commit,undo页会清空,多了读取undo的过程,会导致速度比commit慢很多。
==========后台线程(读线程、写线程、日志线程等)的作用:
- 1.脏页的刷新(write线程的作用)
- 2.合并插入缓冲(insert buffer)
- 3.undo页的回收
- 4.日志写入
- 5.物理读
在数据库里面,有这么一个现象:如果这个线程或者进程是多个,那么这个进程或者线程就是一个主要的干活的线程,工作量很大。
=====master thread线程
是一个非常核心的后台线程,主要负责将缓冲池中的数据异步刷新到磁盘,保证数据的一致性,包括脏页的刷新、合并插入缓冲(insert buffer、undo页的回收等)
===============修改参数
下面的三个线程(会影响数据库的性能!)的作用、什么时候需要加大数量,怎么调整数量:
1.掌握指标的监控、对应的作用、是否需要调整、怎么调整?
对数据库工程师来说,核心的技术是怎么监控指标和参数,确认是否需要做调整,重点不在于怎么调整!
innodb_purge_threads
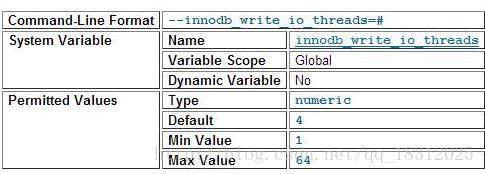
innodb_read_io_threads
innodb_write_io_threads
如果所有读线程或写线程全都工作的话,就要增加线程的数量了!!
一、理论依据
1.这些线程都很繁忙;
2.这些线程对应的作用,出现了异常
二、如何改参数?
- 1.参照官方文档
- 2.这个参数是否动态,如果是动态,可 set@@global.参数名=允许的值;注意,全局修改的话要重新登录一下。
3.如果是global+session的话,可以set@@global或者session,如果在会话级别修改的话,不用重新登录,立即生效。
如果是全局+会话,那么这个参数肯定是动态参数,不需要重启数据库就生效;
如果是全局,那么还要看是否是动态;(非动态要改配置文件,并且重启数据库)
4.对于静态参数,要修改/etc/my.cnf文件,完了show一下参数,看修改时候生效;
- 5.动态参数
- set @@global修改一下;让所有会话重新登录;修改/etc/my.cnf中的参数;
- 6.修改参数的时候,需要看一下这个参数允许的值的范围,以及数据类型。
- 7.强烈建议,修改参数以前,详细阅读参数的作用说明。
===========实例:修改innodb_support_xa 为OFF:
①参看官方文档:
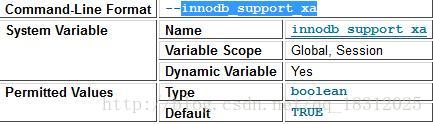
发现是global,session变量,并且是动态的。
方法一:
②set @@global.innodb_support_xa=flase;
③退出mysql,重新登录
④show variables like ‘%xa%’;
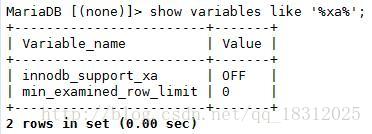
方法二:
①set @@session.innodb_support_xa=false;
②直接:show variables like ‘%xa%’;
发现结果和刚才一样,修改成功。
=============InnoDB Purge Thread线程
事务被提交后,其所使用的undolog可能不再需要,因此需要purge thread来回收已经使用并分配的undo页。在InnoDB1.1版本以前,purge操作仅在InnoDB存储引擎的Master Thread中完成。而从InnoDB1.1版本开始,purge操作可以独立到单独的线程中进行,以此来减轻Master Thread的工作,从而提高CPU的使用率以及提升存储引擎的性能。
可以在mysql的配置文件中添加命令来启用独立的Purge Thread。
Innodb_purge_threads=1
注意:在InnoDB1.1版本中,设为大于1的,存储引擎启动时也会自动改为1;在1.2版本,InnoDB支持多个purge thread,目的是为了加快undo页的回收。
===========undo(oracle、mysql独有的东西)
①先开启一个事务:
START TRANSACTIONrollback时,首先要通过命令“start TRANSACTION”开启一个事务,在这个事务中执行的sql不会commit。所以可以rollback,在rollback时,首先要读取大量的undo,之后在执行sql,这个sql是之前sql相反的操作,之后产生大量的redo,在敲下rollback按下回车时(也就是事物结束之时)会自动回滚并且自动commit,undo页会清空,多了读取undo的过程,会导致速度比commit慢很多。
undo操作:

为什么需要undo?
- 对于一个事务来说,会有rollback和commit。
- rollback本质:读取undo,反向操作,commit!
undo最基本的作用:
- 1.rollback
- 2.提供一致性读,同时,写不锁定读(线程2上来要读的时候,线程1正在写,那么线程2就会去找undo)。
undo:
- 前滚方式:旧的数据块+redo log
- 回滚方式: 假设产生了8万行undo,rollback时,会读取undo
log,反向操作,把8万行数据改回去,会产生大量的redo,实际就是反向操作,然后commit。所以,rollback会很慢。
=======rollback过程原理图解:
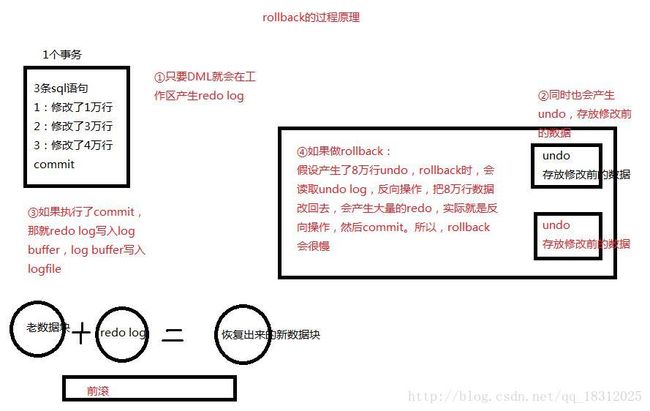
事务操作过程中:
1.物理读undo数据页
2.物理读表的数据页
3.修改undo数据页,产生redo
4.修改表的数据页,产生redo
5.commit;速度非常快
6.rollback;则是读取undo中的数据,根据这些数据,修改数据页,也会产生redo;然后commit
如下图所示:

对于undo数据来说,事务提交以后,这些undo数据就可以删除了。
purger thread线程 回收undo页。读取undo页,将里面的一些内容清空。
==========innodb_buffer_pool
- 可以将buffer pool 调整为物理内存的50%-80%
- 我们在关注innodb_buffer_pool的时候,还需要关注池子的数量。
- 什么时候增加池子的数量。
1.调整buffer大小
60-70%
2.调整instance的数量-》池子的数量。
讲到锁的时候再详解。现在默认即可。
下图是缓冲池(innodb_buffer_pool)里面的结构图:

=======
数据库里面占用空间的都有哪些对象:
- 表
- 索引(把某一列拿出来,建成一棵树)
- undo
- 数据字典
不占的:
- 视图;
- 存储过程;
- 触发器;
- event。
========用来存储数据库自身信息(如下)的表叫做数据字典
1.数据库里面有多少用户?
2.有多少表、列、名字是啥、多少索引等等。
mysql、performance_schema、information_schema
数据字典本身也是表,只不过他们里面存储的是数据库自身的信息,不是生产数据。
比如,user这个表,存储的就是数据库里有多少用户。