【机器学习】数据清洗常用的函数汇总
目录
数据规整化:合并、清理、过滤
1) merge()函数参数----合并数据集
2) pandas 的value_counts()函数----对Series里面的每个值进行计数并且排序
3)astype()--修改列类型
4) 字符替换的方法
5)成员判定
6)判断DataFrame中是否有缺失值
7) DataFrame.sort_values
数据规整化:合并、清理、过滤
1) merge()函数参数----合并数据集
| 参数 | 说明 |
|---|---|
| left | 参与合并的左侧DataFrame |
| right | 参与合并的右侧DataFrame |
| how | 连接方式:‘inner’(默认);还有,‘outer’、‘left’、‘right’ |
| on | 用于连接的列名,必须同时存在于左右两个DataFrame对象中,如果位指定,则以left和right列名的交集作为连接键 |
| left_on | 左侧DataFarme中用作连接键的列 |
| right_on | 右侧DataFarme中用作连接键的列 |
| left_index | 将左侧的行索引用作其连接键 |
| right_index | 将右侧的行索引用作其连接键 |
| sort | 根据连接键对合并后的数据进行排序,默认为True。有时在处理大数据集时,禁用该选项可获得更好的性能 |
| suffixes | 字符串值元组,用于追加到重叠列名的末尾,默认为(‘_x’,‘_y’).例如,左右两个DataFrame对象都有‘data’,则结果中就会出现‘data_x’,‘data_y’ |
| copy | 设置为False,可以在某些特殊情况下避免将数据复制到结果数据结构中。默认总是赋值 |
df1 = pd.DataFrame({'key':['b','b','a','c','a','a','b'],'data1': range(7)})
data1 key 0 0 b 1 1 b 2 2 a 3 3 c 4 4 a 5 5 a 6 6 b
df2 = pd.DataFrame({'key':['a','b','d'],'data2':range(3)})
data2 key 0 0 a 1 1 b 2 2 d
pd.merge(df1,df2)#默认情况
data1 key data2 0 0 b 1 1 1 b 1 2 6 b 1 3 2 a 0 4 4 a 0 5 5 a 0
df1.merge(df2,on = 'key',how = 'outer')#外链接,取并集,并用nan填充
data1 key data2 0 0.0 b 1.0 1 1.0 b 1.0 2 6.0 b 1.0 3 2.0 a 0.0 4 4.0 a 0.0 5 5.0 a 0.0 6 3.0 c NaN 7 NaN d 2.0
更多的例子转见:https://blog.csdn.net/ly_ysys629/article/details/73849543
2) pandas 的value_counts()函数----对Series里面的每个值进行计数并且排序

每个区域都被计数,并且默认从最高到最低做降序排列。
如果想用升序排列,可以加参数ascending=True:#ascending 上升的,向上的
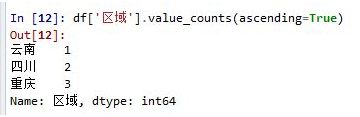
如果想得出的计数占比,可以加参数normalize=True:
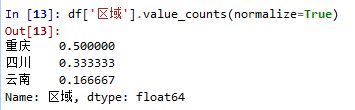
空值是默认剔除掉的。value_counts()返回的结果是一个Series数组,可以跟别的数组进行运算。
3) astype()--修改列类型
a = [['a', '1', '4.2'], ['b', '70', '0.03'], ['x', '5', '0']]
df = pd.DataFrame(a, columns=['one', 'two', 'three'])
print df
one two three
0 a 1 4.2
1 b 70 0.03
2 x 5 0
print df.dtypes
one object
two object
three object
dtype: object
批量操作
df[['two', 'three']] = df[['two', 'three']].astype(float)
print (df.dtypes)
one object
two float64
three float64
dtype: object
df['two'] = df['two'].astype(int)
print df.dtypes
one object
two int64
three float64
dtype: object4) 字符替换的方法
-
replace()方法
描述:Python replace() 方法把字符串中的 old(旧字符串)替换成 new(新字符串),如果指定第三个参数max,则替换不超过 max 次。
replace()方法语法:str.replace(old, new[, max])
str = "this is string example....wow!!! this is really string";
print str.replace("is", "was");
print str.replace("is", "was", 3);
[out]:
thwas was string example....wow!!! thwas was really string
thwas was string example....wow!!! thwas is really string- 正则中的应用
- re.sub()
text = ”JGood is a handsome boy, he is cool, clever, and so on…”
print re.sub(r‘\s+’, ‘-‘, text)re.sub功能是对于一个输入的字符串,利用正则表达式,来实现字符串替换处理的功能返回处理后的字符串。
re.sub的函数原型为:re.sub(pattern, repl, string, count),其中第二个函数是替换后的字符串;本例中为’-‘第四个参数指替换个数。默认为0,表示每个匹配项都替换。
-
re.split()----支持正则及多个字符切割
line="abc aa;bb,cc | dd(xx).xxx 12.12' xxxx"
按空格切
>>> re.split(r' ',line)
['abc', 'aa;bb,cc', '|', 'dd(xx).xxx', "12.12'\txxxx"]
加将空格放可选框内[]内
>>> re.split(r'[ ]',line)
['abc', 'aa;bb,cc', '|', 'dd(xx).xxx', "12.12'\txxxx"]
按所有空白字符来切割:\s([\t\n\r\f\v])\S(任意非空白字符[^\t\n\r\f\v]
>>> re.split(r'[\s]',line)
['abc', 'aa;bb,cc', '|', 'dd(xx).xxx', "12.12'", 'xxxx']
*********多字符匹配***************
/////////////////////////////////
*********多字符匹配***************
>>> re.split(r'[;,]',line)
['abc aa', 'bb', "cc | dd(xx).xxx 12.12'\txxxx"]
>>> re.split(r'[;,\s]',line)
['abc', 'aa', 'bb', 'cc', '|', 'dd(xx).xxx', "12.12'", 'xxxx']
使用括号捕获分组的适合,默认保留分割符
re.split('([;])',line)
['abc aa', ';', "bb,cc | dd(xx).xxx 12.12'\txxxx"]这里要区别在字符串:
str.split不支持正则及多个切割符号,不感知空格的数量,比如用空格切割,会出现下面情况 。
>>> s1="aa bb cc"
>>> s1.split(' ')
['aa', 'bb', '', 'cc']5) 成员判定
-
in----(检查一个值是否在序列中)
一般来说,in运算符会检查一个对象是否为某个序列(或者是其他的数据集合)的成员(也就是元素)。
>>> letters="abcdefg"
>>> 'd' in letters
True
>>> 'h' in letters
False
>>> users = ['jack','peter','jakson']
>>> input('Enter your name:') in users;
Enter your name:jack
True- contain----包含
6) 判断DataFrame中是否有缺失值
- 判断是否存在缺失值
df.isnull()
- 判断哪些列存在缺失值
df.isnull().any()
- 只显示存在缺失值的行
df[df.isnull().values==True]
7) DataFrame.sort_values
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last')
by : str or list of str
Name or list of names to sort by.
- if axis is 0 or ‘index’ then by may contain index levels and/or column labels
- if axis is 1 or ‘columns’ then by may contain column levels and/or index labels
Changed in version 0.23.0: Allow specifying index or column level names.
axis : {0 or ‘index’, 1 or ‘columns’}, default 0
Axis to be sorted
ascending : bool or list of bool, default True
Sort ascending vs. descending. Specify list for multiple sort orders. If this is a list of bools, must match the length of the by.
inplace : bool, default False
if True, perform operation in-place
kind : {‘quicksort’, ‘mergesort’, ‘heapsort’}, default ‘quicksort’
Choice of sorting algorithm. See also ndarray.np.sort for more information.mergesort is the only stable algorithm. For DataFrames, this option is only applied when sorting on a single column or label.
na_position : {‘first’, ‘last’}, default ‘last’
first puts NaNs at the beginning, last puts NaNs at the end
Examples
>>> df = pd.DataFrame({
... 'col1' : ['A', 'A', 'B', np.nan, 'D', 'C'],
... 'col2' : [2, 1, 9, 8, 7, 4],
... 'col3': [0, 1, 9, 4, 2, 3],
... })
>>> df
col1 col2 col3
0 A 2 0
1 A 1 1
2 B 9 9
3 NaN 8 4
4 D 7 2
5 C 4 3Sort by col1
>>> df.sort_values(by=['col1'])
col1 col2 col3
0 A 2 0
1 A 1 1
2 B 9 9
5 C 4 3
4 D 7 2
3 NaN 8 4Sort by multiple columns
>>> df.sort_values(by=['col1', 'col2'])
col1 col2 col3
1 A 1 1
0 A 2 0
2 B 9 9
5 C 4 3
4 D 7 2
3 NaN 8 4Sort Descending
>>> df.sort_values(by='col1', ascending=False)
col1 col2 col3
4 D 7 2
5 C 4 3
2 B 9 9
0 A 2 0
1 A 1 1
3 NaN 8 4Putting NAs first(na_position : {‘first’, ‘last’}, default ‘last’)
>>> df.sort_values(by='col1', ascending=False, na_position='first')
col1 col2 col3
3 NaN 8 4
4 D 7 2
5 C 4 3
2 B 9 9
0 A 2 0
1 A 1 1