在标记的图像训练集上进行面向梯度的直方图(HOG)特征提取并训练分类器线性SVM分类器
应用颜色转换,并将分箱的颜色特征以及颜色的直方图添加到HOG特征矢量中
对于上面两个步骤,不要忘记标准化您的功能,并随机选择一个用于训练和测试的选项
实施滑动窗口技术,并使用您训练的分类器搜索图像中的车辆
在视频流上运行流水线(从test_video.mp4开始,稍后在完整的project_video.mp4中实现),并逐帧创建循环检测的热图,以拒绝异常值并跟踪检测到的车辆
估算检测到的车辆的边界框
定向梯度直方图(HOG)
定向梯度直方图(HOG)是计算机视觉和图像处理中用于目标检测的特征描述符。该技术计算图像的局部部分中梯度定向的发生。这种方法类似于边缘方向直方图,尺度不变特征变换描述符和形状上下文,但不同之处在于它是在均匀间隔的单元的密集网格上计算的,并使用重叠的局部对比度归一化来提高准确性。
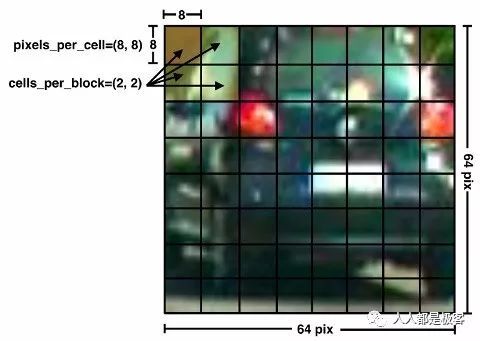
从训练图像中提取HOG特征
此步骤的代码包含在方法“get_hog_features”中的文件vehicle_detection.py中
# Define a function to return HOG features and visualizationdefget_hog_features(self, img, orient, pix_per_cell, cell_per_block,
vis=False, feature_vec=True):# Call with two outputs if vis==Trueifvis ==True: features, hog_image = hog(img, orientations=orient, pixels_per_cell=(pix_per_cell, pix_per_cell), cells_per_block=(cell_per_block, cell_per_block), transform_sqrt=True, visualise=vis, feature_vector=feature_vec)returnfeatures, hog_image# Otherwise call with one outputelse: features = hog(img, orientations=orient, pixels_per_cell=(pix_per_cell, pix_per_cell), cells_per_block=(cell_per_block, cell_per_block), transform_sqrt=True, visualise=vis, feature_vector=feature_vec)returnfeatures
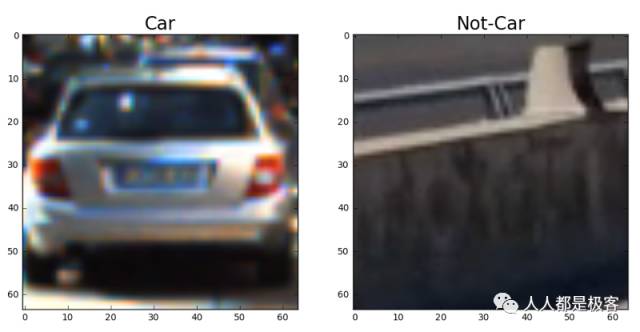
我开始阅读所有的车辆和非车辆图像。这里是每一个中的一个的一个例子vehicle和non-vehicle类:
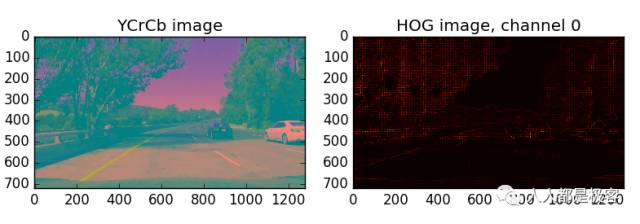
然后我探索不同的色彩空间和不同的skimage.hog()参数(orientations,pixels_per_cell,和cells_per_block)。我从两个类的每一个中抓取随机图像,并显示它们,以感受skimage.hog()输出的样子。使用后的图像以不同的对比度和光度多次试验,它的工作最好使用YCrCb相结合的色彩空间与HOG提取的特征orientations=9,pixels_per_cell=(8, 8)和cells_per_block=(2, 2)。
这是一个使用YCrCb色彩空间和HOG参数的例子orientations=9,pixels_per_cell=(8, 8)并且cells_per_block=(2, 2):
提取颜色特征的空间分级
为了使算法在识别汽车时更加稳健,HOG特征还增加了一种新的特征。除非你确切地知道你的目标对象是什么样子,否则模板匹配不是一个特别可靠的寻找车辆的方法。但是,原始像素值在搜索汽车中包含在您的特征向量中仍然非常有用。
虽然包含全分辨率图像的三个颜色通道可能很麻烦,但是我们可以对图像执行空间分级,并且仍然保留足够的信息来帮助查找车辆。
正如你在下面的例子中看到的那样,即使一路下降到32×32像素分辨率,汽车本身仍然可以被眼睛清楚地识别,这意味着相关特征仍然保留在这个分辨率下。

OpenCV的cv2.resize()是一个方便的缩小图像分辨率的函数。
# Define a function to compute binned color featuresdefbin_spatial(self, img, size=(32,32)):# Use cv2.resize().ravel() to create the feature vector#features = cv2.resize(img, size).ravel()# Return the feature vector#return featurescolor1 = cv2.resize(img[:,:,0], size).ravel() color2 = cv2.resize(img[:,:,1], size).ravel() color3 = cv2.resize(img[:,:,2], size).ravel()returnnp.hstack((color1, color2, color3))
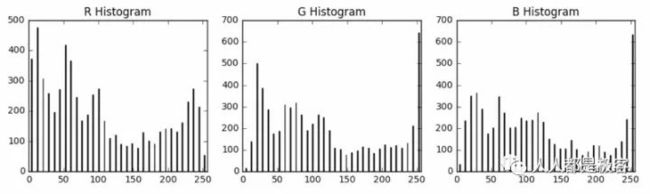
提取颜色特征的直方图
在这个项目中使用的另一个技术,使更多的功能是颜色强度的直方图,如下图所示。
并执行如下所示:
# Define a function to compute color histogram features# NEED TO CHANGE bins_range if reading .png files with mpimg!defcolor_hist(self, img, nbins=32, bins_range=(0,256)):# Compute the histogram of the color channels separatelychannel1_hist = np.histogram(img[:,:,0], bins=nbins, range=bins_range) channel2_hist = np.histogram(img[:,:,1], bins=nbins, range=bins_range) channel3_hist = np.histogram(img[:,:,2], bins=nbins, range=bins_range)# Concatenate the histograms into a single feature vectorhist_features = np.concatenate((channel1_hist[0], channel2_hist[0], channel3_hist[0]))# Return the individual histograms, bin_centers and feature vectorreturnhist_features
合并和规范化的功能
现在我们的工具箱中已经有了几个特征提取方法,我们几乎已经准备好对分类器进行训练了,但是首先,就像在任何机器学习应用程序中一样,我们需要规范化数据。Python的sklearn包为您提供了StandardScaler()方法来完成这个任务。要详细了解如何使用StandardScaler()方法选择不同的标准化,请后台留言查阅文档。
将单个图像的所有不同特征组合为一组特征:
defconvert_color(self, image, color_space='RGB'):ifcolor_space =='HSV': image = cv2.cvtColor(image, cv2.COLOR_RGB2HSV)elifcolor_space =='LUV': image = cv2.cvtColor(image, cv2.COLOR_RGB2LUV)elifcolor_space =='HLS': image = cv2.cvtColor(image, cv2.COLOR_RGB2HLS)elifcolor_space =='YUV': image = cv2.cvtColor(image, cv2.COLOR_RGB2YUV)elifcolor_space =='YCrCb': image = cv2.cvtColor(image, cv2.COLOR_RGB2YCrCb)returnimage# Define a function to extract features from a list of images# Have this function call bin_spatial() and color_hist()defextract_features(self, image, color_space='RGB', spatial_size=(32,32), hist_bins=32, orient=9, pix_per_cell=8, cell_per_block=2, hog_channel=0, spatial_feat=True, hist_feat=True, hog_feat=True):file_features = []# apply color conversion if other than 'RGB'ifcolor_space !='RGB': feature_image = self.convert_color(image, color_space)else: feature_image = np.copy(image)ifspatial_feat ==True: spatial_features = self.bin_spatial(feature_image, size=spatial_size) file_features.append(spatial_features)ifhist_feat ==True:# Apply color_hist()hist_features = self.color_hist(feature_image, nbins=hist_bins) file_features.append(hist_features)ifhog_feat ==True:# Call get_hog_features() with vis=False, feature_vec=Trueifhog_channel =='ALL': hog_features = []forchannelinrange(feature_image.shape[2]): hog_features.append(self.get_hog_features(feature_image[:,:,channel], orient, pix_per_cell, cell_per_block, vis=False, feature_vec=True)) hog_features = np.ravel(hog_features)else: hog_features = self.get_hog_features(feature_image[:,:,hog_channel], orient, pix_per_cell, cell_per_block, vis=False, feature_vec=True)# Append the new feature vector to the features listfile_features.append(hog_features)returnfile_features
规范化是需要避免一些功能类型更重要的其他:
# Extract featuresoffromallnot-car images notcar_features = []forfileinnotcar_filenames: #Readineachonebyone image = mpimg.imread(file) features =self.extract_features(image, color_space=self.color_space, spatial_size=self.spatial_size, hist_bins=self.hist_bins, orient=self.orient, pix_per_cell=self.pix_per_cell, cell_per_block=self.cell_per_block, hog_channel=self.hog_channel, spatial_feat=self.spatial_feat, hist_feat=self.hist_feat, hog_feat=self.hog_feat) notcar_features.append(np.concatenate(features)) X = np.vstack((car_features, notcar_features)).astype(np.float64) # Fit a per-column scalerself.X_scaler = StandardScaler().fit(X) # Apply the scalertoX scaled_X =self.X_scaler.transform(X)
使用规范化的功能来训练分类器
我使用2类图像车辆和非车辆图像训练了一个线性支持向量机。首先加载图像,然后提取归一化的特征,并在2个数据集中训练(80%)和测试(20%)中的混洗和分裂。在使用StandardScaler()训练分类器之前,将特征缩放到零均值和单位方差。源代码可以在vechicle_detection.py中找到
def__train(self):print ('Training the model ...')# Read in and make a list of calibration imagescar_filenames = glob.glob(self.__train_directory+'/vehicles/*/*') notcar_filenames = glob.glob(self.__train_directory+'/non-vehicles/*/*')# Extract features of from all car imagescar_features = []forfileincar_filenames:# Read in each one by oneimage = mpimg.imread(file) features =self.extract_features(image, color_space=self.color_space, spatial_size=self.spatial_size, hist_bins=self.hist_bins, orient=self.orient, pix_per_cell=self.pix_per_cell, cell_per_block=self.cell_per_block, hog_channel=self.hog_channel, spatial_feat=self.spatial_feat, hist_feat=self.hist_feat, hog_feat=self.hog_feat) car_features.append(np.concatenate(features))# Extract features of from all not-car imagesnotcar_features = []forfileinnotcar_filenames:# Read in each one by oneimage = mpimg.imread(file) features =self.extract_features(image, color_space=self.color_space, spatial_size=self.spatial_size, hist_bins=self.hist_bins, orient=self.orient, pix_per_cell=self.pix_per_cell, cell_per_block=self.cell_per_block, hog_channel=self.hog_channel, spatial_feat=self.spatial_feat, hist_feat=self.hist_feat, hog_feat=self.hog_feat) notcar_features.append(np.concatenate(features))X= np.vstack((car_features, notcar_features)).astype(np.float64)# Fit a per-column scalerself.X_scaler=StandardScaler().fit(X)# Apply the scaler to Xscaled_X =self.X_scaler.transform(X)# Define the labels vectory = np.hstack((np.ones(len(car_features)), np.zeros(len(notcar_features))))# Split up data into randomized training and test setsrand_state = np.random.randint(0,100)X_train,X_test, y_train, y_test = train_test_split(scaled_X, y, test_size=0.2, random_state=rand_state) print('Using:',self.orient,'orientations',self.pix_per_cell,'pixels per cell and',self.cell_per_block,'cells per block') print('Feature vector length:', len(X_train[0]))# Use a linear SVCself.svc =LinearSVC()self.svc.fit(X_train, y_train)# Check the score of the SVCprint('Test Accuracy of SVC = ', round(self.svc.score(X_test, y_test),4))# Pickle to save time for subsequent runsbinary = {} binary["svc"] =self.svc binary["X_scaler"] =self.X_scalerpickle.dump(binary, open(self.__train_directory +'/'+self.__binary_filename,"wb"))def__load_binary(self):'''Load previously computed trained classifier'''with open(self.__train_directory +'/'+self.__binary_filename, mode='rb') asf:binary = pickle.load(f)self.svc = binary['svc']self.X_scaler= binary['X_scaler']defget_data(self):'''Getter for the trained data. At the first call it gerenates it.'''ifos.path.isfile(self.__train_directory +'/'+self.__binary_filename):self.__load_binary()else:self.__train()returnself.svc,self.X_scaler
整个数据集(列车+测试)在车辆和非车辆之间均匀分布有17.767个项目。训练完成后,train.p被保存在子文件夹列中的磁盘上,供以后重新使用。训练好的线性支持向量机分类器在测试数据集上的准确性相当高〜0.989
滑动窗口搜索
我决定使用重叠的滑动窗口搜索来搜索图像下部的车辆。只需要搜索下面的部分,以避免搜索天空中的车辆,并使算法更快。窗口大小为64像素,每个单元8个单元和8个像素。在每张幻灯片窗户移动2个单元向右或向下。为了避免每个窗口反复提取特征,搜索速度更快,特征提取只进行一次,滑动窗口只使用该部分图像。如果窗户在长短途容纳所有车辆时具有不同的比例尺,则检测也可以更加稳健。
该实现可以在vehicle_detection.py中找到:
# Define a single function that can extract features using hog sub-sampling and make predictionsdef find_cars(self, img, plot=False): bbox_list = [] draw_img = np.copy(img) img = img.astype(np.float32)/255img_tosearch = img[self.ystart:self.ystop,:,:] ctrans_tosearch =self.convert_color(img_tosearch, color_space='YCrCb')ifself.scale !=1: imshape = ctrans_tosearch.shape ctrans_tosearch = cv2.resize(ctrans_tosearch, (np.int(imshape[1]/self.scale), np.int(imshape[0]/self.scale))) ch1 = ctrans_tosearch[:,:,0] ch2 = ctrans_tosearch[:,:,1] ch3 = ctrans_tosearch[:,:,2]# Define blocks and steps as abovenxblocks = (ch1.shape[1]// self.pix_per_cell)-1nyblocks = (ch1.shape[0]// self.pix_per_cell)-1nfeat_per_block =self.orient*self.cell_per_block**2# 64 was the orginal sampling rate, with 8 cells and 8 pix per cellwindow =64nblocks_per_window = (window// self.pix_per_cell)-1cells_per_step =2# Instead of overlap, define how many cells to stepnxsteps = (nxblocks - nblocks_per_window)// cells_per_stepnysteps = (nyblocks - nblocks_per_window)// cells_per_step# Compute individual channel HOG features for the entire imagehog1 =self.get_hog_features(ch1,self.orient,self.pix_per_cell,self.cell_per_block, feature_vec=False) hog2 =self.get_hog_features(ch2,self.orient,self.pix_per_cell,self.cell_per_block, feature_vec=False) hog3 =self.get_hog_features(ch3,self.orient,self.pix_per_cell,self.cell_per_block, feature_vec=False) bbox_all_list = []forxb in range(nxsteps+1):foryb in range(nysteps): ypos = yb*cells_per_step xpos = xb*cells_per_step# Extract HOG for this patchhog_feat1 = hog1[ypos:ypos+nblocks_per_window, xpos:xpos+nblocks_per_window].ravel() hog_feat2 = hog2[ypos:ypos+nblocks_per_window, xpos:xpos+nblocks_per_window].ravel() hog_feat3 = hog3[ypos:ypos+nblocks_per_window, xpos:xpos+nblocks_per_window].ravel() hog_features = np.concatenate((hog_feat1, hog_feat2, hog_feat3)) xleft = xpos*self.pix_per_cell ytop = ypos*self.pix_per_cell# Extract the image patchsubimg = cv2.resize(ctrans_tosearch[ytop:ytop+window, xleft:xleft+window], (64,64))# Get color featuresspatial_features =self.bin_spatial(subimg, size=self.spatial_size) hist_features =self.color_hist(subimg, nbins=self.hist_bins)# Scale features and make a predictiontest_features =self.X_scaler.transform(np.hstack((spatial_features, hist_features, hog_features)).reshape(1, -1)) test_prediction =self.svc.predict(test_features)# compute current seize of the windowxbox_left = np.int(xleft*self.scale) ytop_draw = np.int(ytop*self.scale) win_draw = np.int(window*self.scale) bbox = ((xbox_left, ytop_draw+self.ystart),(xbox_left+win_draw,ytop_draw+win_draw+self.ystart))iftest_prediction ==1: bbox_list.append(bbox) bbox_all_list.append(bbox)if(plot==True): draw_img_detected = np.copy(draw_img)# draw all all searched windowsforbbox in bbox_all_list: cv2.rectangle(draw_img, bbox[0], bbox[1], (0,0,255),3)forbbox in bbox_list: cv2.rectangle(draw_img_detected, bbox[0], bbox[1], (0,0,255),3) fig = plt.figure() plt.subplot(121) plt.imshow(draw_img) plt.title('Searched sliding windows') plt.subplot(122) plt.imshow(draw_img_detected, cmap='hot') plt.title('Detected vechicle windows') fig.tight_layout() plt.show()returnbbox_list def draw_labeled_bboxes(self, img, labels):# Iterate through all detected carsforcar_number in range(1, labels[1]+1):# Find pixels with each car_number label valuenonzero = (labels[0] == car_number).nonzero()# Identify x and y values of those pixelsnonzeroy = np.array(nonzero[0]) nonzerox = np.array(nonzero[1])# Define a bounding box based on min/max x and ybbox = ((np.min(nonzerox), np.min(nonzeroy)), (np.max(nonzerox), np.max(nonzeroy)))# Draw the box on the imagecv2.rectangle(img, bbox[0], bbox[1], (0,0,255),6)# Return the imagereturnimg
从图中可以看出,2辆车正确检测到,但也有一些误报。
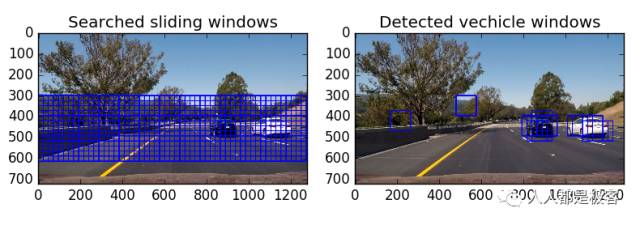
为了避免误报,使用热图。点击地图加窗,重叠的窗口有更高的价值。超过一定的阈值的值保持为真正的正值。
defadd_heat(self, heatmap, bbox_list):# Iterate through list of bboxesforboxinbbox_list:# Add += 1 for all pixels inside each bbox# Assuming each "box" takes the form ((x1, y1), (x2, y2))heatmap[box[0][1]:box[1][1], box[0][0]:box[1][0]] +=1# Return updated heatmapreturnheatmap# Iterate through list of bboxesdefapply_threshold(self, heatmap, threshold):# Zero out pixels below the thresholdheatmap[heatmap <= threshold] =0# Return thresholded mapreturnheatmap
box_list =vehicle_detector.find_cars(image, plot=plot)heat =np.zeros_like(image[:,:,0]).astype(np.float)# Add heat to each box in box listheat =vehicle_detector.add_heat(heat, box_list)# Apply threshold to help remove false positivesheat =vehicle_detector.apply_threshold(heat,1)# Visualize the heatmap when displayingheatmap =np.clip(heat,0,255)
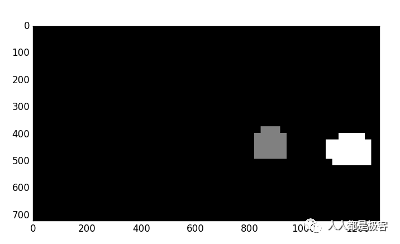
要从热图找到最终的框,使用标签功能。
fromscipy.ndimage.measurements import label# Findfinalboxesfromheatmapusinglabelfunctionlabels=label(heatmap)if(plot==True):#print(labels[1],'cars found') plt.imshow(labels[0], cmap='gray') plt.show()
管道处理一个图像
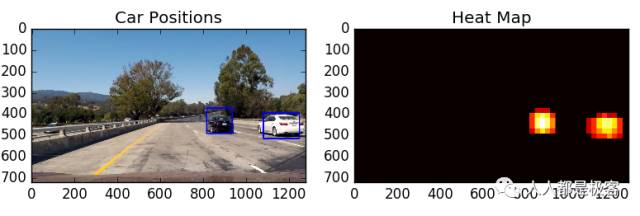
如下面的代码所示,首先我们提取边界框,包括真和假的正面。然后使用热图我们丢弃误报。在使用该scipy.ndimage.measurements.label()方法计算最终的框之后。最后,这些框被渲染。
defprocess_image(image, plot=False):box_list = vehicle_detector.find_cars(image, plot=plot) heat = np.zeros_like(image[:,:,0]).astype(np.float)# Add heat to each box in box listheat = vehicle_detector.add_heat(heat, box_list)# Apply threshold to help remove false positivesheat = vehicle_detector.apply_threshold(heat,1)# Visualize the heatmap when displayingheatmap = np.clip(heat,0,255)# Find final boxes from heatmap using label functionlabels = label(heatmap)if(plot==True):#print(labels[1], 'cars found')plt.imshow(labels[0], cmap='gray') plt.show() new_image = vehicle_detector.draw_labeled_bboxes(image, labels)if(plot==True): fig = plt.figure() plt.subplot(121) plt.imshow(new_image) plt.title('Car Positions') plt.subplot(122) plt.imshow(heatmap, cmap='hot') plt.title('Heat Map') fig.tight_layout() plt.show()returnnew_imagedefprocess_test_images(vehicle_detector, plot=False):test_filenames = glob.glob(TEST_DIRECTORY+'/'+TEST_FILENAME)# Process each test imageforimage_filenameintest_filenames:# Read in each imageimage = cv2.imread(image_filename) image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)# RGB is standard in matlibplotimage = process_image(image, plot) image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)# RGB is standard in matlibplotcv2.imwrite(OUTPUT_DIRECTORY+'/'+image_filename.split('/')[-1], image)
这是测试图像之一的流水线的结果:

管道处理一个视频
process_image(image, plot=False)在视频处理中使用了用于处理一个图像的相同流水线。每个帧都从视频中提取,由图像管道处理,并使用VideoFileClip和ffmpeg合并到最终的视频中
from moviepy.editorimport VideoFileClipdefprocess_video(video_filename, vehicle_detector, plot=False): video_input =VideoFileClip(video_filename +".mp4")video_output = video_input.fl_image(process_image)video_output.write_videofile(video_filename +"_output.mp4", audio=False)process_test_images(vehicle_detector, plot=False)
后台留言回复可以查看视频结果及所有源代码。
结论
当前使用SVM分类器的实现对于测试的图像和视频来说工作良好,这主要是因为图像和视频被记录在类似的环境中。用一个非常不同的环境测试这个分类器不会有类似的好结果。使用深度学习和卷积神经网络的更健壮的分类器将更好地推广到未知数据。
当前实现的另一个问题是在视频处理流水线中不考虑后续帧。保持连续帧之间的热图将更好地丢弃误报。
目前的实施还有一个更大的改进是多尺寸滑动窗口,这将更好地概括查找短距离和长距离的车辆。