1.注册中国大学MOOC
2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
3.学习完成第0周至第4周的课程内容,并完成各周作业
4.提供图片或网站显示的学习进度,证明学习的过程。
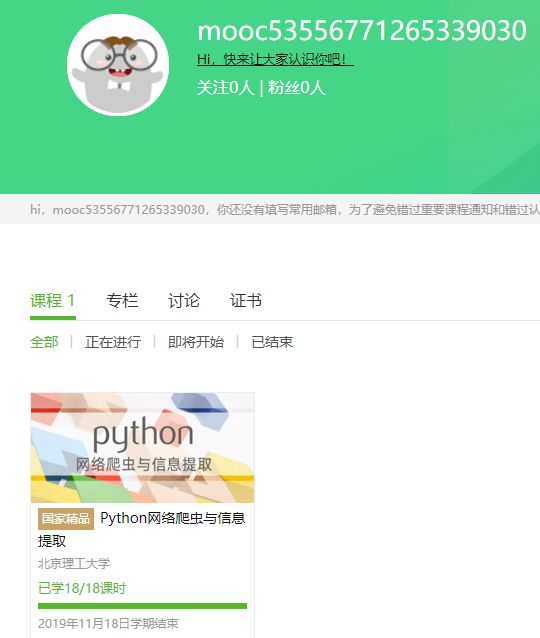
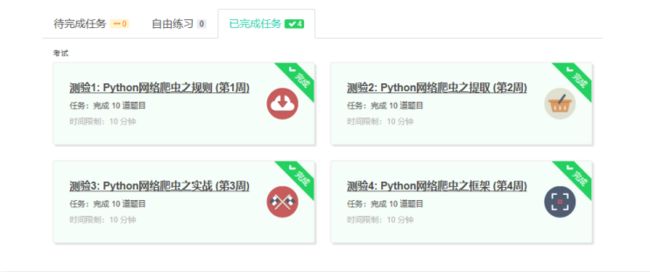
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
人生苦短,我用python
The Website is the API.通过学习,要掌握定向网络数据爬取和网页解析的基本能力。
嵩天老师的《Python网络爬虫与信息提取》MOOC课程循序渐进引导我们学习:首先使用Requests库自动爬取HTML页面,自动网络请求提交——robots.txt 网络爬虫排除标准——Beautiful Soup 解析HTML页面——正则表达式详解 提取页面关键信息——Scrapy库 网络爬虫原理介绍 专业爬虫框架介绍,并且每个例子实战都特别有趣。
IDLE 是自带、默认、常用、入门级的工具,适用于入门、功能简单直接、代码行少的要求。Sublime Text 是专为程序员开发的第三方专用编程工具,有多种编程风格。Wing 工具收费,调试功能丰富,适合多人共同开发。Visual Studio & PTVS 调试功能丰富,Win环境为主。Eclipse 是开源IDE开发工具,配置python需要有一定开发经验。PyCharm 简单、集成度高,适合较复杂工程。Canopy 收费,支持近500个第三方库,适合科学计算领域应用开发。Anaconda 开源免费,支持近800个第三方库。
第一周
1、掌握Requests的7个主要方法、Response对象的5个属性
2、理解Requests库的异常,爬取网页的通用代码框架可以有效处理爬取网页过程中可能出现的错误,变得更可靠稳定
3、了解HTTP协议、及其对资源的操作,理解PATCH和PUT的区别
4、主要掌握Request方法、其13个控制访问参数
5、网络爬虫的尺寸有小、中、大规模,有利也有弊,如骚扰问题、法律风险、隐私泄露,得遵守规则协议,任何一个网络爬虫,都应该遵守Robots协议
6、Robots协议 是网络爬虫排除标准,网站告知网络爬虫哪些页面可以抓取,哪些不行;类人行为可以不参考Robots协议
第二周
1、学习使用BeautifulSoup,它是解析、遍历、维护标签树的功能库,掌握其5种基本元素
2、掌握标签树上行、下行、平行遍历方法,是提取HTML信息的重要手段
3、信息标记一般有三种形式:XML、JSON、YAML
4、信息提取的一般方法:完整解析信息的标记形式、无视标记形式、结合形式解析与搜索方法
第三周
1、学习正则表达式,它是用来简洁表达一组字符串的表达式,最主要应用在字符串匹配中,其语法由字符和操作符构成
2、Re库是python的标准库,主要用于字符串匹配,学习其的主要功能函数
3、学习Re库的Match对象,它是一次匹配的结果,包含匹配的很多信息
第四周
1、Scrapy 是功能强大的网络爬虫框架,包含“5+2”结构
2、认识Scrapy与requests的不同,学习Scrapy命令行的使用
学习了这么多新知识,我们要在逐渐学习深入过程中,了解、理解、并掌握。总之要多动手、多练习、跟着老师要求敲一遍代码,再自己慢慢理解,然后根据自己的思路再多练习几遍,理解、熟练地掌握。学习完嵩天老师的《Python网络爬虫与信息提取》MOOC课程,使我受益匪浅,总之自己还需要努力学习,不断进步。