目录
- 网络编程之线程
- 什么是线程?
- 进程的开销小
- 为何要用多线程
- 线程模型
- 开启线程的两种方式
- 线程对象及其他方法
- 守护线程
- 线程间的数据是共享的(都是享用同一进程下的数据)
- 线程互斥锁
网络编程之线程
什么是线程?
在传统操作系统中,每个进程有一个地址空间,而且默认就有一个控制线程
线程顾名思义,就是一条流水线工作的过程,一条流水线必须属于一个车间,一个车间的工作过程是一个进程
车间负责把资源整合到一起,是一个资源单位,而一个车间内至少有一个流水线
流水线的工作需要电源,电源就相当于cpu
**所以,进程只是用来把资源集中到一起(进程只是一个资源单位,或者说资源集合),而线程才是cpu上的执行单位。**
多线程(即多个控制线程)的概念是,在一个进程中存在多个控制线程,多个控制线程共享该进程的地址空间,相当于一个车间内有多条流水线,都共用一个车间的资源。
例如,北京地铁与上海地铁是不同的进程,而北京地铁里的13号线是一个线程,北京地铁所有的线路共享北京地铁所有的资源,比如所有的乘客可以被所有线路拉。进程的开销小
创建进程的开销要远大于线程?
如果我们的软件是一个工厂,该工厂有多条流水线,流水线工作需要电源,电源只有一个即cpu(单核cpu)
一个车间就是一个进程,一个车间至少一条流水线(一个进程至少一个线程)
创建一个进程,就是创建一个车间(申请空间,在该空间内建至少一条流水线)
而建线程,就只是在一个车间内造一条流水线,无需申请空间,所以创建开销小
进程之间是竞争关系,线程之间是协作关系?
车间直接是竞争/抢电源的关系,竞争(不同的进程直接是竞争关系,是不同的程序员写的程序运行的,迅雷抢占其他进程的网速,360把其他进程当做病毒干死)
一个车间的不同流水线式协同工作的关系(同一个进程的线程之间是合作关系,是同一个程序写的程序内开启动,迅雷内的线程是合作关系,不会自己干自己)为何要用多线程
多线程指的是,在一个进程中开启多个线程,简单的讲:如果多个任务共用一块地址空间,那么必须在一个进程内开启多个线程。详细的讲分为4点:
1. 多线程共享一个进程的地址空间
2. 线程比进程更轻量级,线程比进程更容易创建可撤销,在许多操作系统中,创建一个线程比创建一个进程要快10-100倍,在有大量线程需要动态和快速修改时,这一特性很有用
3. 若多个线程都是cpu密集型的,那么并不能获得性能上的增强,但是如果存在大量的计算和大量的I/O处理,拥有多个线程允许这些活动彼此重叠运行,从而会加快程序执行的速度。
4. 在多cpu系统中,为了最大限度的利用多核,可以开启多个线程,比开进程开销要小的多。(这一条并不适用于python)线程模型
多个线程共享同一个进程的地址空间中的资源,是对一台计算机上多个进程的模拟,有时也称线程为轻量级的进程
而对一台计算机上多个进程,则共享物理内存、磁盘、打印机等其他物理资源。
多线程的运行也多进程的运行类似,是cpu在多个线程之间的快速切换。

不同的进程之间是充满敌意的,彼此是抢占、竞争cpu的关系,如果迅雷会和QQ抢资源。而同一个进程是由一个程序员的程序创建,所以同一进程内的线程是合作关系,一个线程可以访问另外一个线程的内存地址,大家都是共享的,一个线程干死了另外一个线程的内存,那纯属程序员脑子有问题。
类似于进程,每个线程也有自己的堆栈
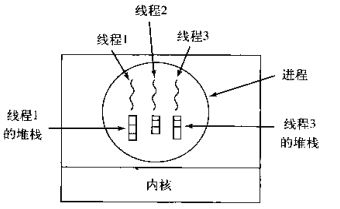
不同于进程,线程库无法利用时钟中断强制线程让出CPU,可以调用thread_yield运行线程自动放弃cpu,让另外一个线程运行。
线程通常是有益的,但是带来了不小程序设计难度,线程的问题是:
1. 父进程有多个线程,那么开启的子线程是否需要同样多的线程
如果是,那么附近中某个线程被阻塞,那么copy到子进程后,copy版的线程也要被阻塞吗,想一想nginx的多线程模式接收用户连接。
2. 在同一个进程中,如果一个线程关闭了问题,而另外一个线程正准备往该文件内写内容呢?
如果一个线程注意到没有内存了,并开始分配更多的内存,在工作一半时,发生线程切换,新的线程也发现内存不够用了,又开始分配更多的内存,这样内存就被分配了多次,这些问题都是多线程编程的典型问题,需要仔细思考和设计。
开启线程的两种方式
from threading import Thread
import time
def task(name):
print('%s is running'%name)
time.sleep(3)
print('%s is over'%name)
# 开线程不需要在__main__代码块内 但是习惯性的还是写在__main__代码块内
t = Thread(target=task,args=('egon',))
t.start() # 告诉操作系统开辟一个线程 线程的开销远远小于进程
# 小的代码执行完 线程就已经开启了
print('主')from threading import Thread
import time
class MyThread(Thread):
def __init__(self,name):
super().__init__()
self.name = name
def run(self): # 自定义线程必须是run
print('%s is running'%self.name)
time.sleep(3)
print('%s is over'%self.name)
t = MyThread('机车')
t.start()
print('主')
线程对象及其他方法
# 线程是没有主子之分的,只是人为定义的。子线程的线程号(子进程号)都等于主线程(主进程号)的线程号,或者说线程本来就没有线程号。
from threading import Thread,current_thread,active_count,enumerate
import time
import os
def task(name,i):
# print('%s is running'%name)
print('子current_thread:',current_thread().name) # 查看线程的名字
print('子',os.getpid())
# time.sleep(i)
print('%s is over'%name)
# 开线程不需要在__main__代码块内 但是习惯性的还是写在__main__代码块内
t = Thread(target=task,args=('egon',1))
t1 = Thread(target=task,args=('jason',2))
t.start() # 告诉操作系统开辟一个线程 线程的开销远远小于进程
t1.start() # 告诉操作系统开辟一个线程 线程的开销远远小于进程
print(enumerate()) # 以列表的形式返回活着的线程的名字 [<_MainThread(MainThread, started 1524)>, ]
t1.join() # 主线程等待子线程运行完毕 ,具有阻断主进程内其下步代码的运行,直到使用join方法的线程运行结束,才运行其下面 的代码
print('当前正在活跃的线程数',active_count())
print(enumerate()) # [<_MainThread(MainThread, started 5744)>]
# print('主current_thread:',current_thread().name) # mainthread
print('主',os.getpid())
'''
子current_thread: Thread-1
子 5556
egon is over
子current_thread: Thread-2
[<_MainThread(MainThread, started 5744)>, ]
子 5556
jason is over
当前正在活跃的线程数 1
[<_MainThread(MainThread, started 5744)>]
主 5556
''' 守护线程
无论是进程还是线程,都遵循:守护xxx会等待主xxx运行完毕后被销毁
需要强调的是:运行完毕并非终止运行;
#1.对主进程来说,运行完毕指的是主进程代码运行完毕。
#2.对主线程来说,运行完毕指的是主线程所在的进程内所有非守护线程统统运行完毕,主线程才算运行完毕。详细解释
#1.主进程在其代码结束后就已经算运行完毕了(守护进程在此时就被回收),然后主进程会一直等非守护的子进程都运行完毕后回收子进程的资源(否则会产生僵尸进程),才会结束;
#2.主线程在其他非守护线程运行完毕后才算运行完毕(守护线程在此时就被回收)。因为主线程的结束意味着进程的结束,进程整体的资源都将被回收,而进程必须保证非守护线程都运行完毕后才能结束。from threading import Thread,current_thread
import time
def task(i):
print(current_thread().name)
time.sleep(i)
print('GG')
# for i in range(3):
# t = Thread(target=task,args=(i,))
# t.start()
t = Thread(target=task,args=(1,))
t.daemon = True
t.start()
print('主')
# 主线程运行结束之后需要等待子线程结束才能结束呢?
"""
主线程的结束也就意味着进程的结束
主线程必须等待其他非守护线程的结束才能结束
(意味子线程在运行的时候需要使用进程中的资源,而主线程一旦结束了资源也就销毁了)线程间的数据是共享的(都是享用同一进程下的数据)
from threading import Thread,current_thread
import time
import os
x=100
def task(i):
global x
x-=1
print(f'这是第{i}次减值,x={x},线程名是{current_thread().name},线程号是{os.getpid()}')
time.sleep(0.1)
for i in range(1,101):
t = Thread(target=task,args=(i,))
t.start()
print(x)
print(f'主:线程名是{current_thread().name},线程号是{os.getpid()}')
'''
这是第1次减值,x=99,线程名是Thread-1,线程号是5332
这是第2次减值,x=98,线程名是Thread-2,线程号是5332
这是第3次减值,x=97,线程名是Thread-3,线程号是5332
这是第4次减值,x=96,线程名是Thread-4,线程号是5332
.
.
.
0
主:线程名是MainThread,线程号是5332
'''
线程互斥锁
from threading import Thread,Lock
import time
import os
from threading import Thread,Lock
import time
import os
# 不加锁的状态
x=100
def task():
global x
temp = x
time.sleep(0.1) # 不加锁所有进程在这里睡眠0.1s之后,同时(并发)去修改x=100,都把100做减1的操作,造成数据错乱。
x = temp-1
start = time.time()
l=[]
mutex = Lock()
for i in range(100):
t = Thread(target=task)
l.append(t)
t.start()
for t in l:
t.join()
print('zhu')
print(x)
print('总运行时间为:',time.time()-start)
'''
zhu
99
总运行时间为: 0.11800670623779297
'''
# 加锁之后
x=100
def task():
mutex.acquire() # 加锁之后使者一百个线程由并发(切换+保存状态)变成了串行取修改x的值,
global x
temp = x
time.sleep(0.1)
x = temp-1
mutex.release()
start = time.time()
l=[]
mutex = Lock()
for i in range(100):
t = Thread(target=task)
l.append(t)
t.start()
for t in l:
t.join()
print('zhu')
print(x)
print('总运行时间为:',time.time()-start)
'''
zhu
0
总运行时间为: 10.003572225570679
'''
'''
分析:
#1.100个线程去抢GIL锁,即抢执行权限
#2. 肯定有一个线程先抢到GIL(暂且称为线程1),然后开始执行,一旦执行就会拿到lock.acquire()
#3. 极有可能线程1还未运行完毕,就有另外一个线程2抢到GIL,然后开始运行,但线程2发现互斥锁lock还未被线程1释放,于是阻塞,被迫交出执行权限,即释放GIL
#4.直到线程1重新抢到GIL,开始从上次暂停的位置继续执行,直到正常释放互斥锁lock,然后其他的线程再重复2 3 4的过程
'''from threading import Thread
from multiprocessing import Process
import time
def foo():
print(123)
time.sleep(1)
print("end123")
def bar():
print(456)
time.sleep(3)
print("end456")
if __name__ == '__main__':
t1=Thread(target=foo)
t2=Thread(target=bar)
t1.daemon=True
t1.start()
t2.start()
print("main-------")
# 主线程会等待非守护的子线程结束才会结束,这里线程t2运行结束,t1早都已经运行结束,所以。。。。。。。
'''
123
456
main-------
end123
end456
'''