Spark Streaming实时流处理项目8——Spark Streaming与Flume的整合
Spark Streaming实时流处理项目1——分布式日志收集框架Flume的学习
Spark Streaming实时流处理项目2——分布式消息队列Kafka学习
Spark Streaming实时流处理项目3——整合Flume和Kafka完成实时数据采集
Spark Streaming实时流处理项目4——实战环境搭建
Spark Streaming实时流处理项目5——Spark Streaming入门
Spark Streaming实时流处理项目6——Spark Streaming实战1
Spark Streaming实时流处理项目7——Spark Streaming实战2
Spark Streaming实时流处理项目8——Spark Streaming与Flume的整合
Spark Streaming实时流处理项目9——Spark Streaming整合Kafka实战
Spark Streaming实时流处理项目10——日志产生器开发并结合log4j完成日志的输出
Spark Streaming实时流处理项目11——综合实战
源码
先添加依赖
org.apache.spark
spark-streaming-flume_2.11
${spark.version}
整合方式一:Push
Flume配置文件flume_push_streaming.conf :
simple-agent.sources = netcat-source
simple-agent.sinks = avro-sink
simple-agent.channels = memory-channel
simple-agent.sources.netcat-source.type = netcat
simple-agent.sources.netcat-source.bind= hadoop0
simple-agent.sources.netcat-source.port= 44444
simple-agent.sinks.avro-sink.type = avro
simple-agent.sinks.avro-sink.hostname= hadoop0
simple-agent.sinks.avro-sink.port= 41414
simple-agent.channels.memory-channel.type = memory
simple-agent.sources.netcat-source.channels = memory-channel
simple-agent.sinks.avro-sink.channel = memory-channel
代码:
import org.apache.spark.SparkConf
import org.apache.spark.streaming.flume.FlumeUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* @ author YuZhansheng
* @ desc Spark Streaming与Flume的整合-push方式
* @ create 2019-02-21 10:04
*/
object FlumePushWordCount {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("FlumePushWordCount")
val ssc = new StreamingContext(sparkConf,Seconds(5))
//TODO...如何使用SparkStreaming整合Flume
val flumeStream = FlumeUtils.createStream(ssc,"hadoop0",41414)
flumeStream.map(x => new String(x.event.getBody.array()).trim)
.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).print()
ssc.start()
ssc.awaitTermination()
}
}先运行SparkStreaming程序,再启动Flume
启动Flume命令: flume-ng agent --name simple-agent --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/flume_push_streaming.conf -Dflume.root.logger=INFO,console
测试验证:telnet hadoop0 44444
改进版:在程序中把主机名和端口号写死,不利于程序的扩展,故升级一下SparkStreaming的代码
import org.apache.spark.SparkConf
import org.apache.spark.streaming.flume.FlumeUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* @author YuZhansheng
* @desc Spark Streaming与Flume的整合-push方式
* @create 2019-02-21 10:04
*/
object FlumePushWordCount {
def main(args: Array[String]): Unit = {
//判断参数
if(args.length != 2){
System.err.println("Usage:FlumePushWordCount ")
System.exit(1)
}
//通过参数传递主机名和端口号
val Array(hostname,port) = args
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("FlumePushWordCount")
val ssc = new StreamingContext(sparkConf,Seconds(5))
//TODO...如何使用SparkStreaming整合Flume
val flumeStream = FlumeUtils.createStream(ssc,hostname,port.toInt)
flumeStream.map(x => new String(x.event.getBody.array()).trim)
.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).print()
ssc.start()
ssc.awaitTermination()
}
} 如何在IDEA中传递参数信息呢?
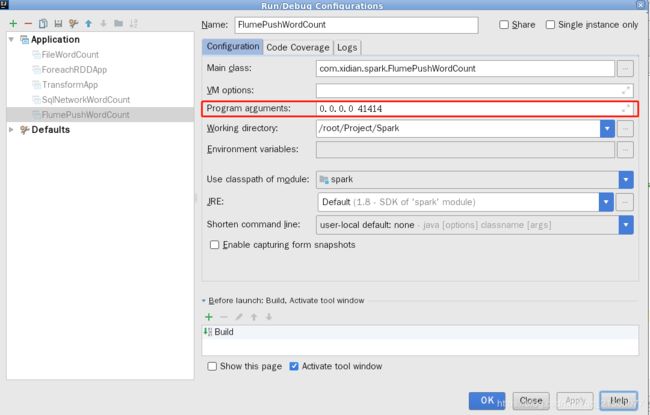
整合方式二:Pull
再加两个依赖:
org.apache.spark
spark-streaming-flume-sink_2.11
${spark.version}
org.apache.commons
commons-lang3
3.5
Flume配置文件flume_pull_streaming.conf :
simple-agent.sources = netcat-source
simple-agent.sinks = spark-sink
simple-agent.channels = memory-channel
simple-agent.sources.netcat-source.type = netcat
simple-agent.sources.netcat-source.bind= hadoop0
simple-agent.sources.netcat-source.port= 44444
simple-agent.sinks.spark-sink.type =org.apache.spark.streaming.flume.sink.SparkSink
simple-agent.sinks.spark-sink.hostname= hadoop0
simple-agent.sinks.spark-sink.port= 41414
simple-agent.channels.memory-channel.type = memory
simple-agent.sources.netcat-source.channels = memory-channel
simple-agent.sinks.spark-sink.channel = memory-channel
代码:
import org.apache.spark.SparkConf
import org.apache.spark.streaming.flume.FlumeUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* @author YuZhansheng
* @desc Spark Streaming与Flume的整合-pull方式
* @create 2019-02-21 10:04
*/
object FlumePullWordCount {
def main(args: Array[String]): Unit = {
//判断参数
if(args.length != 2){
System.err.println("Usage:FlumePushWordCount ")
System.exit(1)
}
//通过参数传递主机名和端口号
val Array(hostname,port) = args
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("FlumePullWordCount")
val ssc = new StreamingContext(sparkConf,Seconds(5))
//TODO...如何使用SparkStreaming整合Flume
val flumeStream = FlumeUtils.createPollingStream(ssc,hostname,port.toInt)
flumeStream.map(x => new String(x.event.getBody.array()).trim)
.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).print()
ssc.start()
ssc.awaitTermination()
}
} 先启动Flume,后启动SparkStreaming
flume-ng agent --name simple-agent --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/flume_pull_streaming.conf -Dflume.root.logger=INFO,console
异常:java.lang.IllegalStateException: begin() called when transaction is OPEN!
在flume文件夹下的 lib目录下jar包冲突 ,scala-library 版本问题导致jar包冲突,在maven仓库里找一个和本地安装Scala版本一致的jar,将原有的替换掉,例如我的本地环境是scala-library-2.11.8.jar
不知道什么原有,我在进行此案例测试的时候,使用netcat命令,一直出现如下问题:
[root@hadoop0 soft]# telnet localhost 44444
Trying ::1...
telnet: connect to address ::1: Connection refused
Trying 127.0.0.1...
telnet: connect to address 127.0.0.1: Connection refused
无奈,只能修改flume配置文件,将数据源source改为监控某一文件的增量,配置内容如下,
simple-agent.sources = netcat-source
simple-agent.sinks = spark-sink
simple-agent.channels = memory-channel
simple-agent.sources.netcat-source.type = exec
simple-agent.sources.netcat-source.command = tail -F /soft/flume1.6/data/data.log
simple-agent.sources.netcat-source.shell = /bin/sh -c
simple-agent.sinks.spark-sink.type = org.apache.spark.streaming.flume.sink.SparkSink
simple-agent.sinks.spark-sink.hostname = hadoop0
simple-agent.sinks.spark-sink.port = 41414
simple-agent.channels.memory-channel.type = memory
simple-agent.sources.netcat-source.channels = memory-channel
simple-agent.sinks.spark-sink.channel = memory-channel
SparkStreaming程序不变,先开启flume,再运行spark程序,向data.log文件中追加数据,看到控制台正确输出。