SSD配置和训练以及遇到的坑
SSD配置
1、clone作者github下的caffe文件包
git clone https://github.com/weiliu89/caffe.git
cd caffe
git checkout ssd(出现“分支”则说明copy-check成功...作者caffe目录下有三个分支fcn/master/ssd, 利用git checkout来切换分支,否则只有master目录下的文件,这一步特别重要,一定不能省略)2.修改Makefile和Makefile.config 文件(和配置caffe过程中的修改一样,具体可参考caffe编译中的python问题)
3.编译,编译的时候有两种选择
1) 网上很多教程说需要cmake,其实不用cmake,直接make (亲测有效)
make all –j512
make runtest
make pycaffe2) 当然如果make后失败,可以采用这种第二种方法(如果已经make过了,首先记得make clean)
mkdir build
cd build
cmake ..
make all –j512
make install
make runtest #这一步不是必须的
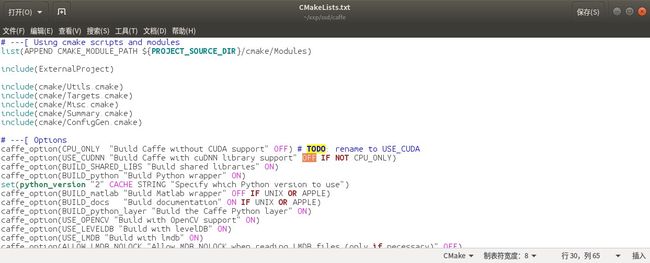
make pycaffetips:使用第二种方法时,这里由于博主使用的电脑没有安装cudnn,于是在make all 的时候出现了很多关于cudnn的错误,解决这个问题的方法是修改CMakeList.txt的下面这一句,将ON改成OFF。
caffe_option(USE_CUDNN"Build Caffe with cuDNN library support" OFF IFNOT CPU_ONLY)
训练
1. 下载预训练模型
http://cs.unc.edu/~wliu/projects/ParseNet/VGG_ILSVRC_16_layers_fc_reduced.caffemodel放到caffe/models/VGGNet/路径下
2. 准备数据集
1)下载数据集caffe/data/路径下
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar2)解压数据
tar -xvf VOCtrainval_11-May-2012.tar
tar –xvf VOCtrainval_06-Nov-2007.tar
tar -xvf VOCtest_06-Nov-2007.tar数据解压后会得到一个名为VOCdevkit的文件夹,里面存放了VOC2007和VOC2012两个数据集的数据。
3)接下来生成lmdb文件以及label文件。
./data/VOC0712/create_list.sh
./data/VOC0712/create_data.shtips:这里注意需要修改data/VOC0712/create_list.sh和 data/VOC0712/create_data.sh里面的路径,将root_dir改为自己路径

训练
执行
cd caffe
python examples/ssd/ssd_pascal.pytips:一定要在caffe路径下执行,否则会出现找不到caffe的错误。
遇到的问题
1) 配置SSD-caffe出现“ AttributeError: 'module' object has no attribute 'LabelMap'”
这是由于caffe的Python环境变量未配置好,可按照下面方法解决:
echo "exportPYTHONPATH=/home/huster/xxp/ssd/caffe/python" >> ~/.profile
source ~/.profile
echo $PYTHONPATH #检查环境变量的值2 配置SSD-caffe测试时出现“Check failed: error ==cudaSuccess (10 vs. 0) invalid device ordinal”
这是由于GPU数量不匹配造成的,如果训练自己的数据,那么我们只需要将solver.prototxt文件中的device_id 项改为自己的GPU块数,一块就是0,两块就是1,以此类推。
但是SSD配置时的例子是将训练语句整合成一个python文件ssd_pascal.py,所以需要改此代码。相关配置训练方法请参看转载博文:http://blog.csdn.net/xunan003/article/details/78427446
解决方法:将ssd_pascal.py文件中第332行gpus= "0,1,2,3"的GPU选择改为gpus = "0",后面的1,2,3都删掉即可。再次训练即可。
当然,由于博主只有一块GPU且电脑运行内存有限,还需要将ssd_pascal.py文件中的337行batch_size= 32和338行accum_batch_size= 32都改小一倍,即更改批量大小,不然会出现“Check failed: error == cudaSuccess(2 vs. 0) invalid ...”的错误。
终于能开始训练了。剩下的下次更新。
感谢以下博客:
【1】https://www.jianshu.com/p/4eaedaeafcb4
【2】https://blog.csdn.net/xunan003/article/details/78432943