YOLO目标检测
文章目录
- 使用VOC数据训练模型
- 下载数据集
- 创建标签
- 修改配置文件
- 模型训练
- 参数解释
使用VOC数据训练模型
下载数据集
我们将使用Pascal VOC数据集训练我们的模型,该数据集可以用来做图像分类、目标检测、图像分割。
下载地址:
将下载的三个VOC数据集压缩文件放在darknet/scripts/中,使用以下命令解压:
tar xf voc.tar && tar xf VOCtrainval_11-May-2012.tar
tar xf VOCtrainval_06-Nov-2007.tar && tar xf VOCtest_06-Nov-2007.tar
-
Annotations文件夹:用于存放图片描述,文件格式为.xml,文件保存了图片文件名,尺寸,标注,坐标,是否分割等信息。 -
ImageSets文件夹:保存了不同用途的图片名字列表,文件格式是.txt。其中包括,
layout文件夹:保存具有人体部位的图片名字列表。
main文件夹:保存用于图像物体识别的图片名字列表。
segmenttions文件夹:保存用于图像分割的图片名字列表。 -
JPEGImages文件夹:保存全部图片源文件。 -
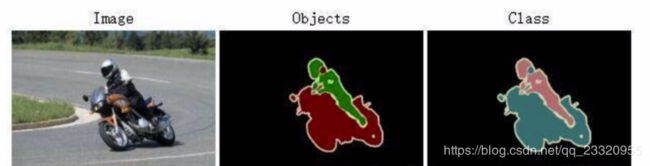
SegmentationClass,SegmentationObject保存用于图像分割的源图片,两者区别如图所示:
创建标签
标签结构:("类别",“中心点x坐标”,“中心点y”坐标,“图片宽度”,“图片高度”)
# 在scripts文件夹内
python voc_label.py
执行成功后会生成一个label文件夹和三个txt文件,分别是2007_train.txt,2007_test.txt,2007_val.txt,2012_train.txt
修改配置文件
打开darknet/cfg/voc.data,修改train,valid文件路径
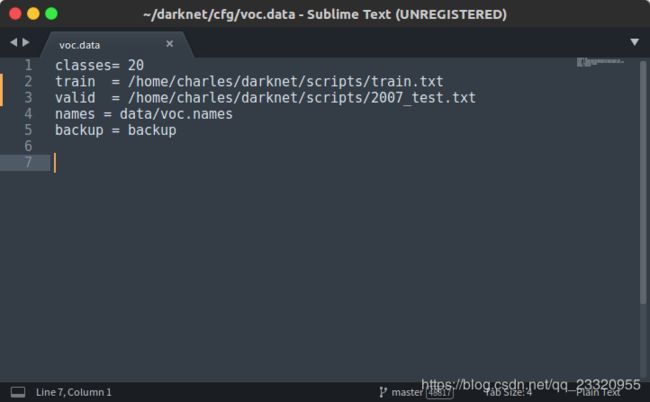
classes:数据集中图片分类数量。
train:用于训练的图片数据集绝对路径。
valid:用于验证的图片数据集绝对路径。
names:数据集中图片分类名字,如:“dog”,“person”等。
backup:模型训练完成后,权重文件保存路径。
模型训练
wget https://pjreddie.com/media/files/darknet53.conv.74
备用下载:
修改cfg/yolov3-voc.cfg
[net]
# 模型测试模式
# Testing
# batch=1
# subdivisions=1
# 模型训练模式
#Training
# batch_size
batch=64
subdivisions=16
#用于进一步分割batch_size,分割后的batch_size大小为:batch_size/subdivisions
# 模型输入图像宽
width=416
# 模型输入图像高
height=416
# 图像通道数
channels=3
# 使用带动量优化函数的动量参数
momentum=0.9
# 权重衰减率,用于防止过拟合
decay=0.0005
# 以下4项是通过改变图像角度,饱和度,曝光量,色调来生成更多样本,可用于防止过拟合
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
# 初始学习率
learning_rate=0.001
burn_in=1000
# 迭代次数
max_batches = 50200
# 当迭代到40000,45000时更改学习率
policy=steps
steps=40000,45000
scales=.1,.1
[convolutional]
# BN标准化处理,可以通过改变数据分布,处理梯度过小问题,加快模型收敛
batch_normalize=1
# 输出特征大小
filters=32
# 卷积核大小3x3
size=3
# 卷积步长为1
stride=1
# pad为0,padding由 padding参数指定。如果pad为1,padding大小为size/2
pad=1
# 激活函数,和relu的区别是当输入值小于0时,输出不为0
activation=leaky
**。。。。。省略。。。。。。**
[yolo]
mask = 0,1,2
# 预选框,可手动指定也可通过聚类学习得到
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
# 识别种类
classes=20
# 每个cell预测box数量,yolov1时只有一个
num=9
# 增加噪声
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=1
执行训练:
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74
停止继续训练:
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg backup/yolov3-voc.backup
训练完成后,权重文件保存在backup文件夹内。
参数解释
- cfg文件参数含义
batch: 每一次迭代送到网络的图片数量,也叫批数量。增大这个可以让网络在较少的迭代次数内完成一个epoch。在固定最大迭代次数的前提下,增加batch会延长训练时间,但会更好的寻找到梯度下降的方向。如果你显存够大,可以适当增大这个值来提高内存利用率。这个值是需要大家不断尝试选取的,过小的话会让训练不够收敛,过大会陷入局部最优。
subdivision:这个参数很有意思的,它会让你的每一个batch不是一下子都丢到网络里。而是分成subdivision对应数字的份数,一份一份的跑完后,在一起打包算作完成一次iteration。这样会降低对显存的占用情况。如果设置这个参数为1的话就是一次性把所有batch的图片都丢到网络里,如果为2的话就是一次丢一半。
angle:图片旋转角度,这个用来增强训练效果的。从本质上来说,就是通过旋转图片来变相的增加训练样本集。
saturation,exposure,hue:饱和度,曝光度,色调,这些都是为了增强训练效果用的。
learning_rate:学习率,训练发散的话可以降低学习率。学习遇到瓶颈,loss不变的话也减低学习率。
max_batches: 最大迭代次数。
policy:学习策略,一般都是step这种步进式。
step,scales:这两个是组合一起的,举个例子:learn_rate: 0.001, step:100,25000,35000 scales: 10, .1, .1 这组数据的意思就是在0-100次iteration期间learning rate为原始0.001,在100-25000次iteration期间learning rate为原始的10倍0.01,在25000-35000次iteration期间learning rate为当前值的0.1倍,就是0.001, 在35000到最大iteration期间使用learning rate为当前值的0.1倍,就是0.0001。随着iteration增加,降低学习率可以是模型更有效的学习,也就是更好的降低train loss。
最后一层卷积层中filters数值是 3 * (classes + 5)(YOLOv3)。
region里需要把classes改成你的类别数。
最后一行的random,是一个开关。如果设置为1的话,就是在训练的时候每一batch图片会随便改成320-640(32整倍数)大小的图片。目的和上面的色度,曝光度等一样。如果设置为0的话,所有图片就只修改成默认的大小 416*416。
- 训练log中各参数的意义
Region Avg IOU:平均的IOU,代表预测的bounding box和ground truth的交集与并集之比,期望该值趋近于1。
Class:是标注物体的概率,期望该值趋近于1.
Obj:期望该值趋近于1.
No Obj:期望该值越来越小但不为零.
Avg Recall:期望该值趋近1
avg:平均损失,期望该值趋近于0
rate:当前学习率
推荐博客:
YOLO训练自己的数据集的一些心得