破解 Kotlin 协程(3) - 协程调度篇
破解 Kotlin 协程(3) - 协程调度篇
关键词:Kotlin 异步编程 协程
上一篇我们知道了协程启动的几种模式,也通过示例认识了
launch启动协程的使用方法,本文将延续这些内容从调度的角度来进一步为大家揭示协程的奥义。
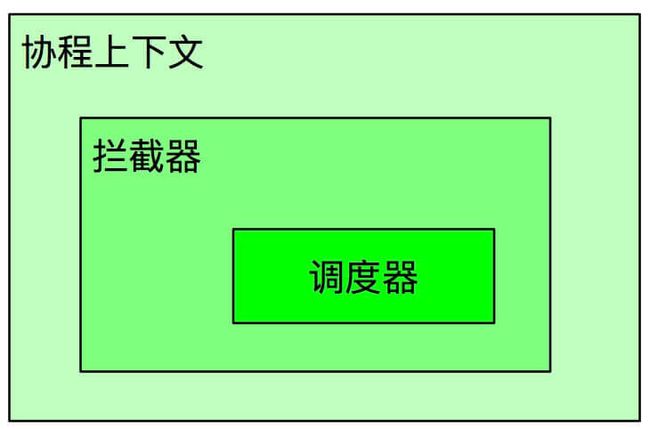
1. 协程上下文
调度器本质上就是一个协程上下文的实现,我们先来介绍下上下文。
前面我们提到 launch 函数有三个参数,第一个参数叫 上下文,它的接口类型是 CoroutineContext,通常我们见到的上下文的类型是 CombinedContext 或者 EmptyCoroutineContext,一个表示上下文的组合,另一个表示什么都没有。我们来看下 CoroutineContext 的接口方法:
@SinceKotlin("1.3")
public interface CoroutineContext {
public operator fun <E : Element> get(key: Key<E>): E?
public fun <R> fold(initial: R, operation: (R, Element) -> R): R
public operator fun plus(context: CoroutineContext): CoroutineContext = ...
public fun minusKey(key: Key<*>): CoroutineContext
public interface Key<E : Element>
public interface Element : CoroutineContext {
public val key: Key<*>
...
}
}
不知道大家有没有发现,它简直就是一个以 Key 为索引的 List:
| CoroutineContext | List |
|---|---|
| get(Key) | get(Int) |
| plus(CoroutineContext) | plus(List) |
| minusKey(Key) | removeAt(Int) |
表中的
List.plus(List)实际上指的是扩展方法Collection.plus(elements: Iterable ): List
CoroutineContext 作为一个集合,它的元素就是源码中看到的 Element,每一个 Element 都有一个 key,因此它可以作为元素出现,同时它也是 CoroutineContext 的子接口,因此也可以作为集合出现。
讲到这里,大家就会明白,CoroutineContext 原来是个数据结构啊。如果大家对于 List 的递归定义比较熟悉的话,那么对于 CombinedContext 和 EmptyCoroutineContext 也就很容易理解了,例如 scala 的 List是这么定义的:
sealed abstract class List[+A] extends ... {
...
def head: A
def tail: List[A]
...
}
在模式匹配的时候,List(1,2,3,4) 是可以匹配 x::y 的,x 就是 1,y 则是 List(2,3,4)。
CombinedContext 的定义也非常类似:
internal class CombinedContext(
private val left: CoroutineContext,
private val element: Element
) : CoroutineContext, Serializable {
...
}
只不过它是反过来的,前面是集合,后面是单独的一个元素。我们在协程体里面访问到的 coroutineContext 大多是这个 CombinedContext 类型,表示有很多具体的上下文实现的集合,我们如果想要找到某一个特别的上下文实现,就需要用对应的 Key 来查找,例如:
suspend fun main(){
GlobalScope.launch {
println(coroutineContext[Job]) // "coroutine#1":StandaloneCoroutine{Active}@1ff62014
}
println(coroutineContext[Job]) // null,suspend main 虽然也是协程体,但它是更底层的逻辑,因此没有 Job 实例
}
这里的 Job 实际上是对它的 companion object 的引用
public interface Job : CoroutineContext.Element {
/**
* Key for [Job] instance in the coroutine context.
*/
public companion object Key : CoroutineContext.Key<Job> { ... }
...
}
所以我们也可以仿照
Thread.currentThread()来一个获取当前Job的方法:suspend inline fun Job.Key.currentJob() = coroutineContext[Job] suspend fun coroutineJob(){ GlobalScope.launch { log(Job.currentJob()) } log(Job.currentJob()) }
我们可以通过指定上下文为协程添加一些特性,一个很好的例子就是为协程添加名称,方便调试:
GlobalScope.launch(CoroutineName("Hello")) {
...
}
如果有多个上下文需要添加,直接用 + 就可以了:
GlobalScope.launch(Dispatchers.Main + CoroutineName("Hello")) {
...
}
Dispatchers.Main是调度器的一个实现,不用担心,我们很快就会认识它了。
2. 协程拦截器
费了好大劲儿说完上下文,这里就要说一个比较特殊的存在了——拦截器。
public interface ContinuationInterceptor : CoroutineContext.Element {
companion object Key : CoroutineContext.Key<ContinuationInterceptor>
public fun <T> interceptContinuation(continuation: Continuation<T>): Continuation<T>
...
}
拦截器也是一个上下文的实现方向,拦截器可以左右你的协程的执行,同时为了保证它的功能的正确性,协程上下文集合永远将它放在最后面,这真可谓是天选之子了。
它拦截协程的方法也很简单,因为协程的本质就是回调 + “黑魔法”,而这个回调就是被拦截的 Continuation 了。用过 OkHttp 的小伙伴一下就兴奋了,拦截器我常用的啊,OkHttp 用拦截器做缓存,打日志,还可以模拟请求,协程拦截器也是一样的道理。调度器就是基于拦截器实现的,换句话说调度器就是拦截器的一种。
我们可以自己定义一个拦截器放到我们的协程上下文中,看看会发生什么。
class MyContinuationInterceptor: ContinuationInterceptor{
override val key = ContinuationInterceptor
override fun <T> interceptContinuation(continuation: Continuation<T>) = MyContinuation(continuation)
}
class MyContinuation<T>(val continuation: Continuation<T>): Continuation<T> {
override val context = continuation.context
override fun resumeWith(result: Result<T>) {
log(" $result" )
continuation.resumeWith(result)
}
}
我们只是在回调处打了一行日志。接下来我们把用例拿出来:
suspend fun main() {
GlobalScope.launch(MyContinuationInterceptor()) {
log(1)
val job = async {
log(2)
delay(1000)
log(3)
"Hello"
}
log(4)
val result = job.await()
log("5. $result")
}.join()
log(6)
}
这可能是迄今而止我们给出的最复杂的例子了,不过请大家不要被它吓到,它依然很简单。我们通过 launch 启动了一个协程,为它指定了我们自己的拦截器作为上下文,紧接着在其中用 async 启动了一个协程,async 与 launch 从功能上是同等类型的函数,它们都被称作协程的 Builder 函数,不同之处在于 async 启动的 Job 也就是实际上的 Deferred 可以有返回结果,可以通过 await 方法获取。
可想而知,result 的值就是 Hello。那么这段程序运行的结果如何呢?
15:31:55:989 [main] Success(kotlin.Unit) // ①
15:31:55:992 [main] 1
15:31:56:000 [main] Success(kotlin.Unit) // ②
15:31:56:000 [main] 2
15:31:56:031 [main] 4
15:31:57:029 [kotlinx.coroutines.DefaultExecutor] Success(kotlin.Unit) // ③
15:31:57:029 [kotlinx.coroutines.DefaultExecutor] 3
15:31:57:031 [kotlinx.coroutines.DefaultExecutor] Success(Hello) // ④
15:31:57:031 [kotlinx.coroutines.DefaultExecutor] 5. Hello
15:31:57:031 [kotlinx.coroutines.DefaultExecutor] 6
“// ①” 不是程序输出的内容,仅为后续讲解方便而做的标注。
大家可能就要奇怪了,你不是说 Continuation 是回调么,这里面回调调用也就一次啊(await 那里),怎么日志打印了四次呢?
别慌,我们按顺序给大家介绍。
首先,所有协程启动的时候,都会有一次 Continuation.resumeWith 的操作,这一次操作对于调度器来说就是一次调度的机会,我们的协程有机会调度到其他线程的关键之处就在于此。 ①、② 两处都是这种情况。
其次,delay 是挂起点,1000ms 之后需要继续调度执行该协程,因此就有了 ③ 处的日志。
最后,④ 处的日志就很容易理解了,正是我们的返回结果。
可能有朋友还会有疑问,我并没有在拦截器当中切换线程,为什么从 ③ 处开始有了线程切换的操作?这个切换线程的逻辑源自于 delay,在 JVM 上 delay 实际上是在一个 ScheduledExcecutor 里面添加了一个延时任务,因此会发生线程切换;而在 JavaScript 环境中则是基于 setTimeout,如果运行在 Nodejs 上,delay 就不会切线程了,毕竟人家是单线程的。
如果我们在拦截器当中自己处理了线程切换,那么就实现了自己的一个简单的调度器,大家有兴趣可以自己去尝试。
思考:拦截器可以有多个吗?
3. 调度器
3.1 概述
有了前面的基础,我们对于调度器的介绍就变得水到渠成了。
public abstract class CoroutineDispatcher :
AbstractCoroutineContextElement(ContinuationInterceptor), ContinuationInterceptor {
...
public abstract fun dispatch(context: CoroutineContext, block: Runnable)
...
}
它本身是协程上下文的子类,同时实现了拦截器的接口, dispatch 方法会在拦截器的方法 interceptContinuation 中调用,进而实现协程的调度。所以如果我们想要实现自己的调度器,继承这个类就可以了,不过通常我们都用现成的,它们定义在 Dispatchers 当中:
val Default: CoroutineDispatcher
val Main: MainCoroutineDispatcher
val Unconfined: CoroutineDispatcher
这个类的定义涉及到了 Kotlin MPP 的支持,因此你在 Jvm 版本当中还会看到 val IO: CoroutineDispatcher,在 js 和 native 当中就只有前面提到的这三个了(对 Jvm 好偏心呐)。
| Jvm | Js | Native | |
|---|---|---|---|
| Default | 线程池 | 主线程循环 | 主线程循环 |
| Main | UI 线程 | 与 Default 相同 | 与 Default 相同 |
| Unconfined | 直接执行 | 直接执行 | 直接执行 |
| IO | 线程池 | – | – |
- IO 仅在 Jvm 上有定义,它基于 Default 调度器背后的线程池,并实现了独立的队列和限制,因此协程调度器从 Default 切换到 IO 并不会触发线程切换。
- Main 主要用于 UI 相关程序,在 Jvm 上包括 Swing、JavaFx、Android,可将协程调度到各自的 UI 线程上。
- Js 本身就是单线程的事件循环,与 Jvm 上的 UI 程序比较类似。
3.2 编写 UI 相关程序
Kotlin 的用户绝大多数都是 Android 开发者,大家对 UI 的开发需求还是比较大的。我们举一个很常见的场景,点击一个按钮做点儿异步的操作再回调刷新 UI:
getUserBtn.setOnClickListener {
getUser { user ->
handler.post {
userNameView.text = user.name
}
}
}
我们简单得给出 getUser 函数的声明:
typealias Callback = (User) -> Unit
fun getUser(callback: Callback){
...
}
由于 getUser 函数需要切到其他线程执行,因此回调通常也会在这个非 UI 的线程中调用,所以为了确保 UI 正确被刷新,我们需要用 handler.post 切换到 UI 线程。上面的写法就是我们最古老的写法了。
后来又有了 RxJava,那么事情开始变得有趣了起来:
fun getUserObservable(): Observable<User> {
return Observable.create<User> { emitter ->
getUser {
emitter.onNext(it)
}
}
}
于是点击按钮的事件可以这么写:
getUserBtn.setOnClickListener {
getUserObservable()
.observeOn(AndroidSchedulers.mainThread())
.subscribe { user ->
userNameView.text = user.name
}
}
其实 RxJava 在线程切换上的表现是非常优秀的,也正是如此,很多人甚至用它只是为了切线程方便!
那么我们现在把这段代码过渡到协程的写法:
suspend fun getUserCoroutine() = suspendCoroutine<User> {
continuation ->
getUser {
continuation.resume(it)
}
}
按钮点击时,我们可以:
getUserBtn.setOnClickListener {
GlobalScope.launch(Dispatchers.Main) {
userNameView.text = getUserCoroutine().name
}
}
大家也可以用 anko-coroutines 当中的 View.onClick 扩展,这样我们就无需自己在这里用
launch启动协程了。有关 Anko 对协程的支持,我们后面专门安排一篇文章介绍。
这里又有大家没见过的内容啦,suspendCoroutine 这个方法并不是帮我们启动协程的,它运行在协程当中并且帮我们获取到当前协程的 Continuation 实例,也就是拿到回调,方便后面我们调用它的 resume 或者 resumeWithException 来返回结果或者抛出异常。
如果你重复调用
resume或者resumeWithException会收获一枚IllegalStateException,仔细想想这是为什么。
对比前面的 RxJava 的做法,你会发现这段代码其实很容易理解,你甚至会发现协程的使用场景与 RxJava 竟是如此的相似。这里我们用到了 Dispatchers.Main 来确保 launch 启动的协程在调度时始终调度到 UI 线程,那么下面我们来看看 Dispatchers.Main 的具体实现。
在 Jvm 上,Main 的实现也比较有意思:
internal object MainDispatcherLoader {
@JvmField
val dispatcher: MainCoroutineDispatcher = loadMainDispatcher()
private fun loadMainDispatcher(): MainCoroutineDispatcher {
return try {
val factories = MainDispatcherFactory::class.java.let { clz ->
ServiceLoader.load(clz, clz.classLoader).toList()
}
factories.maxBy { it.loadPriority }?.tryCreateDispatcher(factories)
?: MissingMainCoroutineDispatcher(null)
} catch (e: Throwable) {
MissingMainCoroutineDispatcher(e)
}
}
}
在 Android 当中,协程框架通过注册 AndroidDispatcherFactory 使得 Main 最终被赋值为 HandlerDispatcher 的实例,有兴趣的可以去看下 kotlinx-coroutines-android 的源码实现。
注意前面对于 RxJava 和协程的实现,我们都没有考虑异常和取消的问题。有关异常和取消的话题,我们会在后面的文章中详细介绍。
3.3 绑定到任意线程的调度器
调度器的目的就是切线程,你不要想着我在 dispatch 的时候根据自己的心情来随机调用,那你是在害你自己(不怕各位笑话,这样的代码我还真写过,仅供娱乐)。那么问题就简单了,我们只要提供线程,调度器就应该很方便的创建出来:
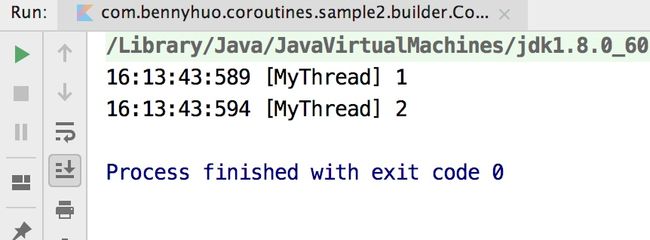
suspend fun main() {
val myDispatcher= Executors.newSingleThreadExecutor{ r -> Thread(r, "MyThread") }.asCoroutineDispatcher()
GlobalScope.launch(myDispatcher) {
log(1)
}.join()
log(2)
}
输出的信息就表明协程运行在我们自己的线程上。
16:10:57:130 [MyThread] 1
16:10:57:136 [MyThread] 2
不过请大家注意,由于这个线程池是我们自己创建的,因此我们需要在合适的时候关闭它,不然的话:

我们可以通过主动关闭线程池或者调用:
myDispatcher.close()
来结束它的生命周期,再次运行程序就会正常退出了。
当然有人会说你创建的线程池的线程不是 daemon 的,所以主线程结束时 Jvm 不会停止运行。说的没错,但该释放的还是要及时释放,如果你只是在程序的整个生命周期当中短暂的用了一下这个调度器,那么一直不关闭它对应的线程池岂不是会有线程泄露吗?这就很尴尬了。
Kotlin 协程设计者也特别害怕大家注意不到这一点,还特地废弃了两个 API 并且开了一个 issue 说我们要重做这套 API,这两个可怜的家伙是谁呢?
废弃的两个基于线程池创建调度器的 API
fun newSingleThreadContext(name: String): ExecutorCoroutineDispatcher
fun newFixedThreadPoolContext(nThreads: Int, name: String): ExecutorCoroutineDispatcher
这二者可以很方便的创建绑定到特定线程的调度器,但过于简洁的 API 似乎会让人忘记它的风险。Kotlin 一向不爱做这种不清不楚的事儿,所以您呢,还是像我们这一节例子当中那样自己去构造线程池吧,这样好歹自己忘了关闭也怨不着别人(哈哈哈)。
其实在多个线程上运行协程,线程总是这样切来切去其实并不会显得很轻量级,例如下面的例子就是比较可怕的了:
Executors.newFixedThreadPool(10)
.asCoroutineDispatcher().use { dispatcher ->
GlobalScope.launch(dispatcher) {
log(1)
val job = async {
log(2)
delay(1000)
log(3)
"Hello"
}
log(4)
val result = job.await()
log("5. $result")
}.join()
log(6)
}
这里面除了 delay 那里有一次不可避免的线程切换外,其他几处协程挂起点的继续操作(Continuation.resume)都会切线程:
16:28:04:771 [pool-1-thread-1] 1
16:28:04:779 [pool-1-thread-1] 4
16:28:04:779 [pool-1-thread-2] 2
16:28:05:790 [pool-1-thread-3] 3
16:28:05:793 [pool-1-thread-4] 5. Hello
16:28:05:794 [pool-1-thread-4] 6
如果我们的线程池只开 1 个线程,那么这里所有的输出都将在这唯一的线程中打印:
16:40:14:685 [pool-1-thread-1] 1
16:40:14:706 [pool-1-thread-1] 4
16:40:14:710 [pool-1-thread-1] 2
16:40:15:723 [pool-1-thread-1] 3
16:40:15:725 [pool-1-thread-1] 5. Hello
16:40:15:725 [pool-1-thread-1] 6
对比这二者,10个线程的情况线程切换次数最少 3次,而 1 个线程的情况则只要 delay 1000ms 之后恢复执行的时候那一次。只是多两次线程切换,到底会有多大影响呢?我在我自己的 2015 款 mbp 上对于两种不同的情况分别循环运行 100 次,得到的平均时间如下:
| 线程数 | 10 | 1 |
|---|---|---|
| 耗时ms | 1006.00 | 1004.97 |
注意,为了测试的公平性,在运行 100 次循环之前已经做好了预热,确保所有类都已经加载。测试结果仅供参考。
也就是说多两次线程切换平均能多出 1ms 的耗时。生产环境当中的代码当然会更复杂,如果这样用线程池去调度,结果可想而知。
实际上通常我们只需要在一个线程当中处理自己的业务逻辑,只有一些耗时的 IO 才需要切换到 IO 线程中处理,所以好的做法可以参考 UI 对应的调度器,自己通过线程池定义调度器的做法本身没什么问题,但最好只用一个线程,因为多线程除了前面说的线程切换的开销外,还有线程安全的问题。
3.4 线程安全问题
Js 和 Native 的并发模型与 Jvm 不同,Jvm 暴露了线程 API 给用户,这也使得协程的调度可以由用户更灵活的选择。越多的自由,意味着越多的代价,我们在 Jvm 上面编写协程代码时需要明白一点的是,线程安全问题在调度器不同的协程之间仍然存在。
好的做法,就像我们前面一节提到的,尽量把自己的逻辑控制在一个线程之内,这样一方面节省了线程切换的开销,另一方面还可以避免线程安全问题,两全其美。
如果大家在协程代码中使用锁之类的并发工具就反而增加了代码的复杂度,对此我的建议是大家在编写协程代码时尽量避免对外部作用域的可变变量进行引用,尽量使用参数传递而非对全局变量进行引用。
以下是一个错误的例子,大家很容易就能想明白:
suspend fun main(){
var i = 0
Executors.newFixedThreadPool(10)
.asCoroutineDispatcher().use { dispatcher ->
List(1000000) {
GlobalScope.launch(dispatcher) {
i++
}
}.forEach {
it.join()
}
}
log(i)
}
输出的结果:
16:59:28:080 [main] 999593
4. suspend main 函数如何调度?
上一篇文章我们提到了 suspend main 会启动一个协程,我们示例中的协程都是它的子协程,可是这个最外层的协程到底是怎么来的呢?
我们先给出一个例子:
suspend fun main() {
log(1)
GlobalScope.launch {
log(2)
}.join()
log(3)
}
它等价于下面的写法:
fun main() {
runSuspend {
log(1)
GlobalScope.launch {
log(2)
}.join()
log(3)
}
}
那你说这个 runSuspend 又是何妨神圣?它是 Kotlin 标准库的一个方法,注意它不是 kotlinx.coroutines 当中的,它实际上属于更底层的 API 了。
internal fun runSuspend(block: suspend () -> Unit) {
val run = RunSuspend()
block.startCoroutine(run)
run.await()
}
而这里面的 RunSuspend 则是 Continuation 的实现:
private class RunSuspend : Continuation<Unit> {
override val context: CoroutineContext
get() = EmptyCoroutineContext
var result: Result<Unit>? = null
override fun resumeWith(result: Result<Unit>) = synchronized(this) {
this.result = result
(this as Object).notifyAll()
}
fun await() = synchronized(this) {
while (true) {
when (val result = this.result) {
null -> (this as Object).wait()
else -> {
result.getOrThrow() // throw up failure
return
}
}
}
}
}
它的上下文是空的,因此 suspend main 启动的协程并不会有任何调度行为。
通过这个例子我们可以知道,实际上启动一个协程只需要有一个 lambda 表达式就可以了,想当年 Kotlin 1.1 刚发布的时候,我写了一系列的教程都是以标准库 API 为基础的,后来发现标准库的 API 也许真的不是给我们用的,所以看看就好。
上述代码在标准库当中被修饰为
internal,因此我们无法直接使用它们。不过你可以把 RunSuspend.kt 当中的内容复制到你的工程当中,这样你就可以直接使用啦,其中的var result: Result可能会报错,没关系,改成? = null private var result: Result就可以了。? = null
5. 小结
在这篇文章当中,我们介绍了协程上下文,介绍了拦截器,进而最终引出了我们的调度器,截止目前,我们还有异常处理、协程取消、Anko 对协程的支持等话题没有讲到,如果大家有协程相关想了解的话题,可以留言哈~
欢迎关注 Kotlin 中文社区!
中文官网:https://www.kotlincn.net/
中文官方博客:https://www.kotliner.cn/
公众号:Kotlin
知乎专栏:Kotlin
CSDN:Kotlin中文社区
掘金:Kotlin中文社区
简书:Kotlin中文社区
开发者头条:Kotlin中文社区