bidirectional_dynamic_rnn和static_bidirectional_rnn实现Bidirectional_RNN
本文作者: Yu Li, Algorithm Developer & Designer
本文链接: http://sthsf.github.io/2017/08/31/Tensorflow基础知识-bidirectional-rnn/
写在前面
最近在做一些自然语言处理demo的时候遇到了双向RNN,里面的bidirectional_dynamic_rnn和static_bidirectional_rnn还是值得理解下的,故记录下自己的学习心得。
双向RNNs
双向RNNs模型是RNN的扩展模型,RNN模型在处理序列模型的学习上主要是依靠上文的信息,双向RNNs模型认为模型的输出不仅仅依靠序列前面的元素,后面的元素对输出也有影响。比如说,想要预测序列中的一个缺失值,我们不仅仅要考虑该缺失值前面的元素,而且要考虑他后面的元素。
简单点来将两个RNN堆叠在一起,分别从两个方向计算序列的output和state,而最终的输出则根据两个RNNs的隐藏状态计算,如下图所示

这个网络有两层神经元,一层从左向右传播,另一层从右向左传播。为了保证任何时刻t都有两层隐层,这个网络需要消耗两倍的存储量来存储权重和偏置等参数。最终的分类结果是由两层RNN隐层组合来产生最终的结果。
公式1和2表示双向RNN隐层的数学含义。在这两个关系中唯一不同点是循环的方向不一样。公式3展示了通过总结过去和未来词的表示,使用类别的关系来预测下一个词预测。
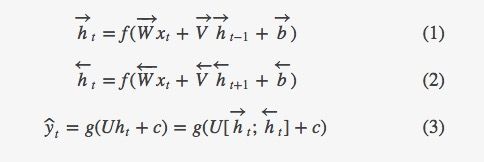
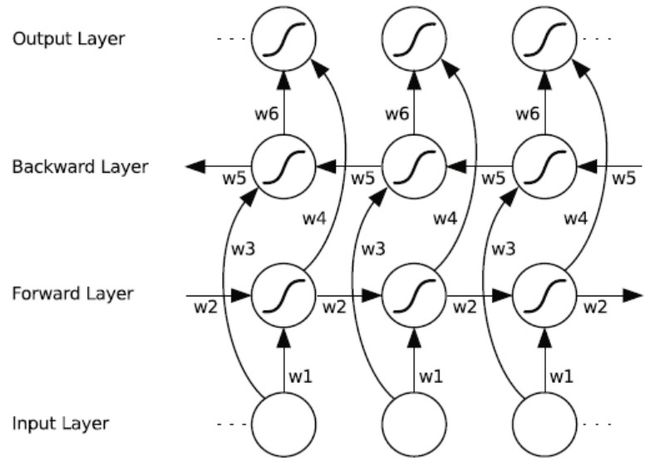
下图展示的是一个沿着时间展开的双向循环神经网络。六个独特的权值在每一时步被重复的利用,六个权值分别对应:输入到向前和向后隐含层(w1,w3),隐含层到隐含层自己(w2, w5),向前和向后隐含层到输出层(w4, w6)。
值得注意的是:向后和向前隐含层之间没有信息流,是独立计算的,只是最后输出的时候把二者的状态向量结合起来,这保证了展开图是非循环的。
Tensorflow中实现双向RNNs
tf.contrib.rnn.bidirectional_dynamic_rnn()
在tensorflow中已经提供了双向RNNs的接口,使用tf.contrib.rnn.bidirectional_dynamic_rnn()这个函数,就可以很方便的构建双向RNN网络。
首先看下接口的一些参数
bidirectional_dynamic_rnn(
cell_fw, # 前向 rnn cell
cell_bw, # 反向 rnn cell
inputs, # 输入序列.
sequence_length=None, # 输入序列的实际长度(可选,默认为输入序列的最大长度)
initial_state_fw=None, # 前向rnn_cell的初始状态(可选)
initial_state_bw=None, # 反向rnn_cell的初始状态(可选)
dtype=None, # 初始化和输出的数据类型(可选)
parallel_iterations=None,
swap_memory=False,
time_major=False, # 决定了输入输出tensor的格式:如果为true, 向量的形状必须为 `[max_time, batch_size, depth]`.
# 如果为false, tensor的形状必须为`[batch_size, max_time, depth]`. 与dynamic_rnn中的time_major类似。
scope=None
)
函数的返回值:
一个(outputs, outputs_state)的一个元祖。
其中,
- outputs=(outputs_fw, outputs_bw),是一个包含前向cell输出tensor和后向tensor输出tensor组成的元祖。
若time_major=false,则两个tensor的shape为[batch_size, max_time, depth],应用在文本中时,max_time可以为句子的长度(一般以最长的句子为准,短句需要做padding),depth为输入句子词向量的维度。
最终的outputs需要使用tf.concat(outputs, 2)将两者合并起来。
- outputs_state = (outputs_state_fw, output_state_bw),包含了前向和后向最后的隐藏状态的组成的元祖。outputs_state_fw和output_state_bw的类型都是LSTMStateTuple。LSTMStateTuple由(c, h)组成,分别代表memory cell和hidden state
cell_fw和cell_bw的定义是完全一样的,如果两个cell都定义成LSTM就变成说了双向LSTM了。
import tensorflow as tf
# 正向传播的rnn_cell单元,这里使用的是LSRTMCell
cell_fw_lstm = tf.nn.rnn_cell.LSTMCell('num_units')
# 反向传播的rnn_cell单元,与正向传播的rnn单元相同
cell_bw_lstm = tf.nn.rnn_cell.LSTMCell('num_units')
在实现的时候,我们只需要将定义好的两个cell作为参数传入就可以了:
(outputs, outputs_state) = tf.nn.bidirectional_dynamic_rnn(cell_fw_lstm, cell_bw_lstm, inputs_embedded)
# inputs_embedded为输入的tensor,[batch_szie, max_time, depth]。batch_size为模型当中batch的大小.
# 应用在文本中时,max_time可以为句子的长度(一般以最长的句子为准,短句需要做padding),depth为输入句子词向量的维度
最终的输出outputs = tf.concat((outputs_fw, outputs_bw), 2)或者直接是outputs = tf.concat(outputs, 2)
如果还需要用到最后的输出状态,则需要对(outputs_state_fw, output_state_bw)处理:
final_state_c = tf.concat((outputs_state_fw.c, outputs_state_bw.c), 1)
final_state_h = tf.concat((outputs_state_fw.h, outputs_state_bw.h), 1)
outputs_final_state = tf.contrib.rnn.LSTMStateTuple(c=final_state_c,
h=final_state_h)
双向LSRTM的实现过如下:
import tensorflow as tf
vocab_size = 1000
embedding_size = 50
batch_size =100
max_time = 10
hidden_units = 10
inputs = tf.placeholder(shape=(batch_size, max_time), dtype=tf.int32, name='inputs')
embedding = tf.Variable(tf.random_uniform([vocab_size, embedding_size], -1.0, 1.0), dtype=tf.float32)
inputs_embeded = tf.nn.embedding_lookup(embedding, inputs)
lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(hidden_units)
((outputs_fw, outputs_bw), (outputs_state_fw, outputs_state_bw)) = tf.nn.bidirectional_dynamic_rnn(lstm_cell, lstm_cell, inputs_embeded, sequence_length=max_time)
outputs = tf.concat((outputs_fw, outputs_bw), 2)
final_state_c = tf.concat((outputs_state_fw.c, outputs_state_bw.c), 1)
final_state_h = tf.concat((outputs_state_fw.h, outputs_state_bw.h), 1)
outputs_final_state = tf.contrib.rnn.LSTMStateTuple(c=final_state_c,
h=final_state_h)
tf.contrib.rnn.static_bidirectional_rnn()
多层双向RNNs
图三展示了一个从较低层传播到下层的多层双向RNN。如图所示,在网络结构中,第t个时间里每一个中间神经元接受到前一个时间(同样的RNN层)传递过来的一组参数,以及之前RNN层传递过来的两组参数。这两组参数一个是从左到右的RNN输入,另一个是从右到左的RNN输入。
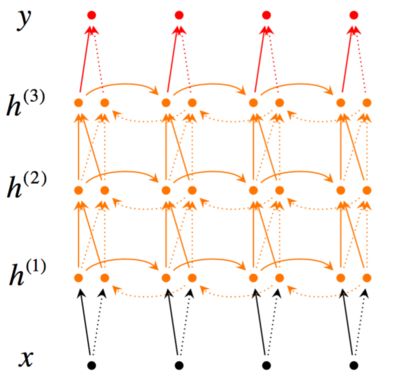
为了构建一个L层的RNN,上述的关系将会参照公式4和公式5所修改,其中每一个中间神经元(第i层)的输入是RNN网络中同样的t时刻第i-1层的输出。其中输出,在每一个时刻值为通过所有隐层的输入参数传播的结果(如公式6所示)。
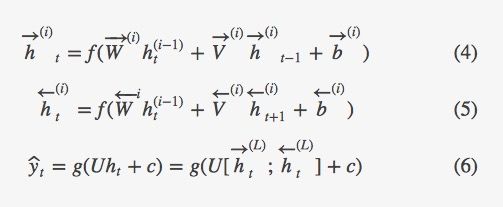
参考文献
tensorflow.nn.bidirectional_dynamic_rnn()函数的用法
深度学习与自然语言处理(7)_斯坦福cs224d 语言模型,RNN,LSTM与GRU
tensorflow学习笔记(三十九):双向rnn
看过的关于BiRNN实现更多的好文章:
https://blog.csdn.net/u012436149/article/details/71080601
https://blog.csdn.net/zgcr654321/article/details/84553740