Hive零基础从入门到实战 入门篇(一)环境搭建
目录
前言
1.Hive是什么
2.Hive学习环境搭建
前言
作为一个数据分析师,操作Hive提取数据已经成为了一个必备技能,但对数据分析师来说,查询才是做的最多的操作,毕竟使用工具是为了完成分析。所以我认为数据分析师是不需要掌握Hive具体的底层架构、安装运维、甚至是运行原理等知识的,毕竟我们不是运维也不是大数据开发工程师,实际工作中也确实用不到这些知识,所以我总结的知识点主要以数据分析从零基础入门操作到实战为主,同时我会提供安装好Hive的虚拟机供大家下载,避免大家从安装到放弃。
1.Hive是什么
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表。
Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。
在互联网公司实际生产中,Hive用于离线计算,因为Hive有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive并不能够在大规模数据集上实现低延迟快速的查询,例如,Hive 在几百MB 的数据集上执行查询一般有分钟级的时间延迟。
Hive的最佳使用场合是大数据集的批处理作业。在互联网公司,每个用户在其app、web网页上的所有行为都会上报到日志中,即便是一个日活跃用户数只有10万的APP,每日产生的日志行数也是千万级的,而类似微信这种日活就有10亿用户的APP,其每日产生的数据量更是天文数字。
如果想要对这些数据进行分析、挖掘,现阶段互联网行业内使用最广泛的就是Hive。
2.学习环境搭建
准备一台内存8G,单一磁盘剩余空间60G以上的电脑,下载以下百度网盘链接内容。
包括:
1.vmware安装包
2.安装好HIve的linux虚拟机配置文件
3.linux系统所用的ISO镜像
4.远程连接虚拟机的Xshell
5.编辑HQL的notepad安装包
链接:https://pan.baidu.com/s/15ZLhrX0Y20vCR6Bha6jtQg
提取码:ywpz
复制这段内容后打开百度网盘手机App,操作更方便哦
具体安装配置教程如下:
1.安装VMware虚拟机,一路next即可,安装运行后点击打开虚拟机:
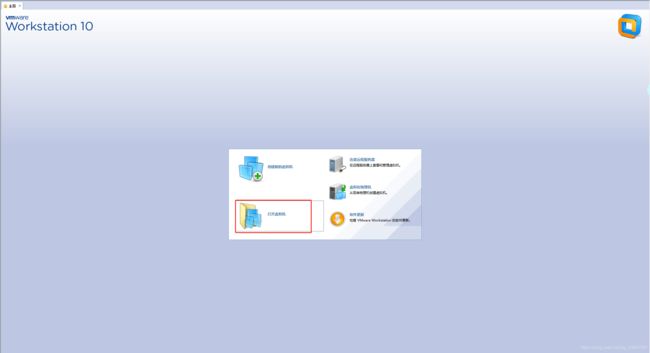
2.解压网盘中下载的Red Hat Enterprise 6.5 x86_64.rar,选择hadoop.vmx
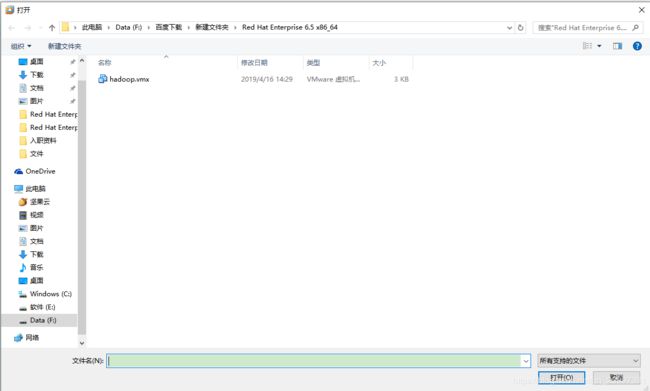
3.选择网盘中下载的镜像文件:Red Hat Enterprise 6.5 x86_64.iso



4.如图配置网卡,选择VMnet1进行配置,其余不用修改
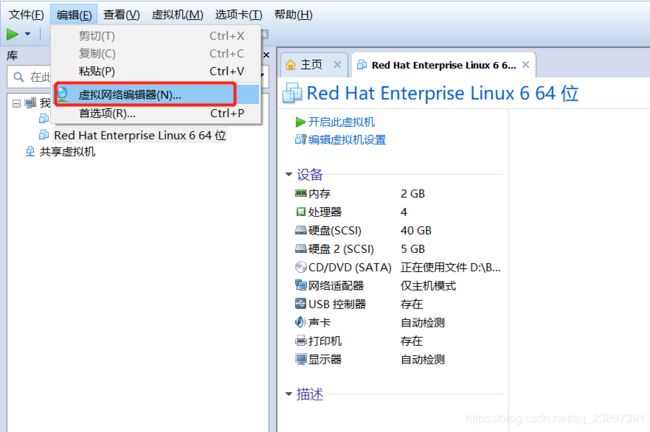
一定要将子网ip改为192.168.16.0

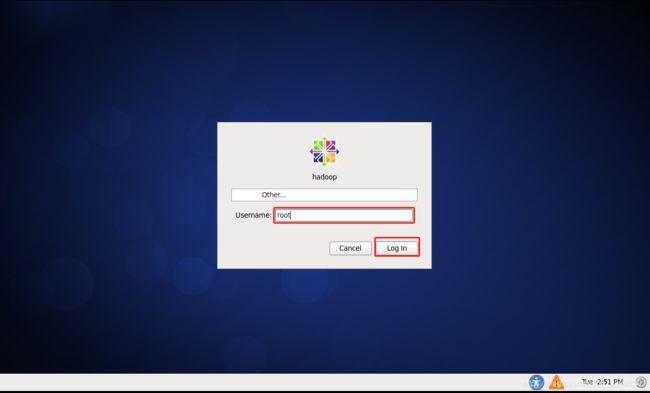
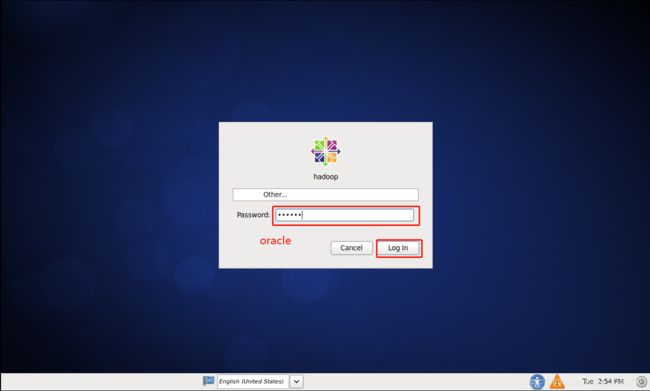
5.开启虚拟机,点击other,用户名:root,密码:oracle

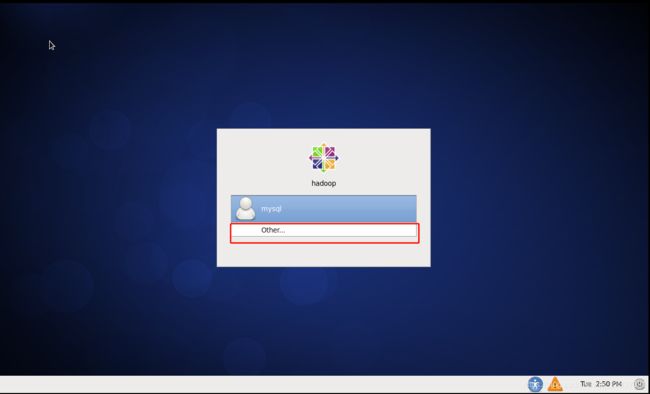
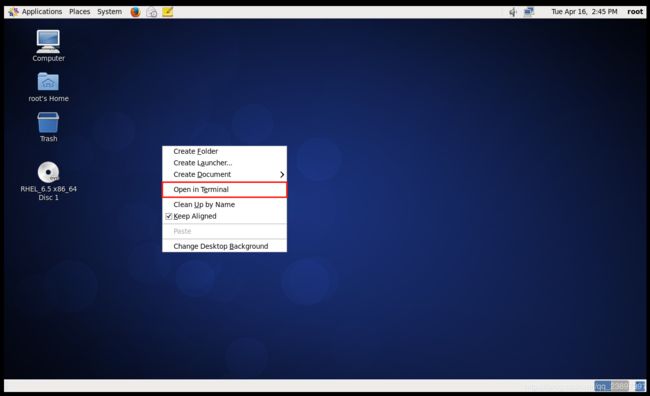
单击右键,选择Open in Terminal
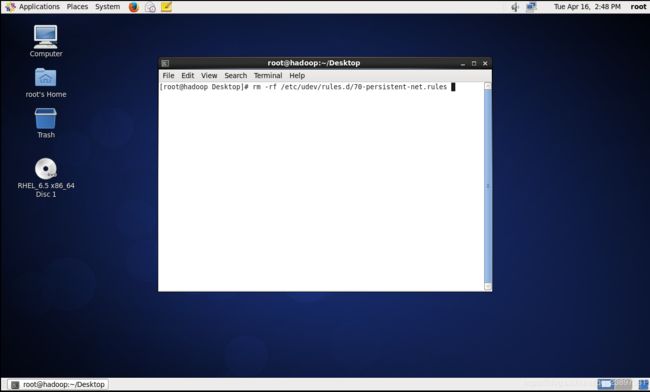
输入 rm -rf /etc/udev/rules.d/70-persistent-net.rules
回车
重启虚拟机

6.安装Xmanager,安装完成后打开Xshell

8.连接虚拟机,点击new
输入Host:192.168.16.100
点击OK

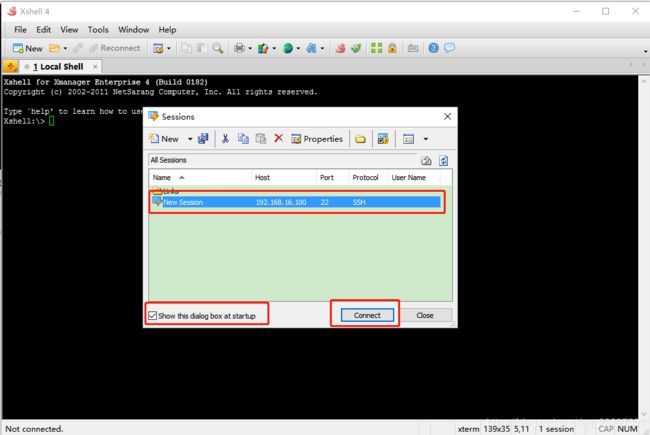
用户名:root ,勾选记住用户名
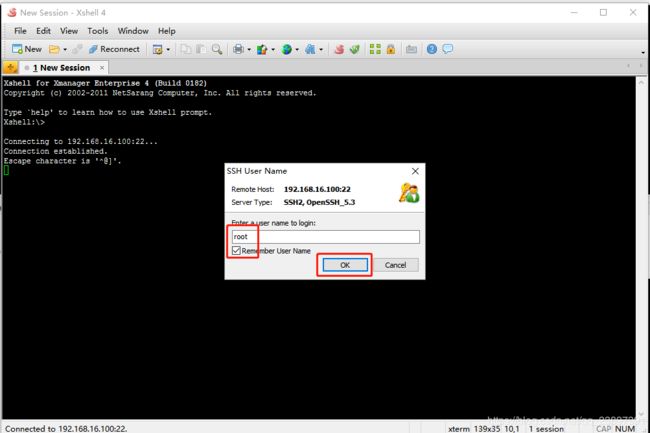
密码:oracle,勾选记住密码

登录成功

调大字体
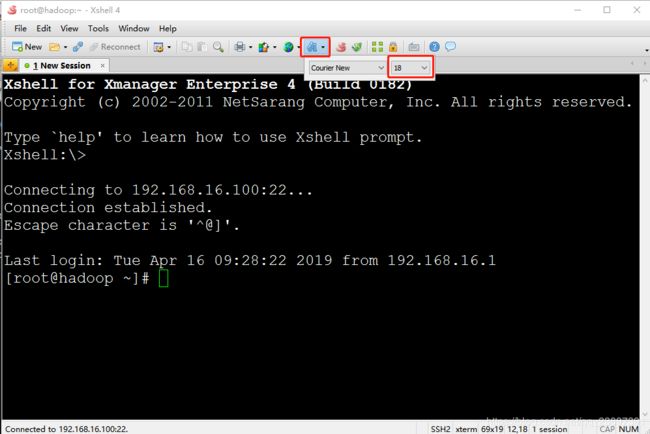
选择UTF-8编码
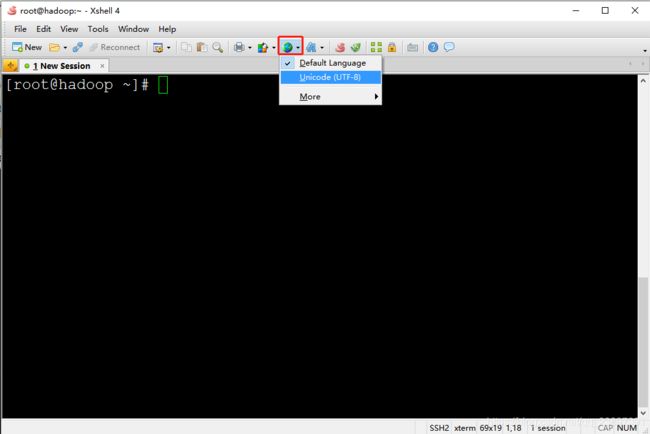
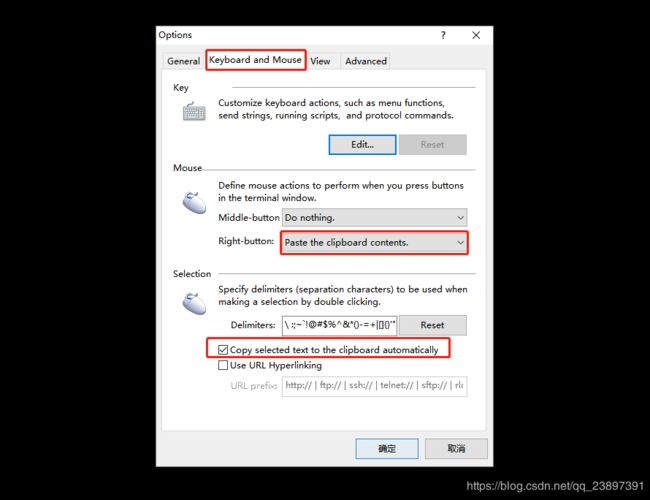
配置鼠标选中即可复制,右键为粘贴
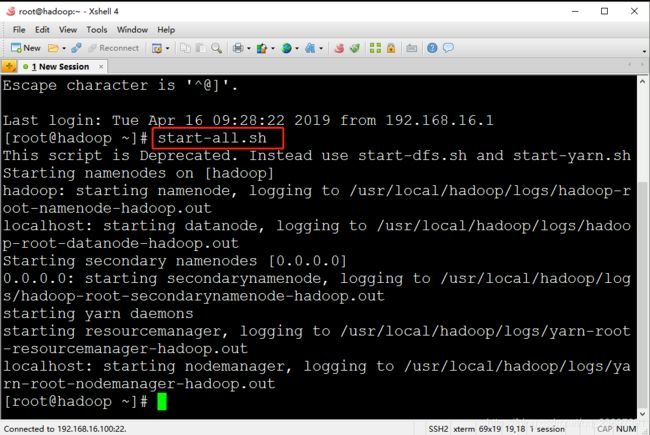
9.输入start-all.sh 回车。也可以复制该命令,进入xshell直接右键粘贴,回车
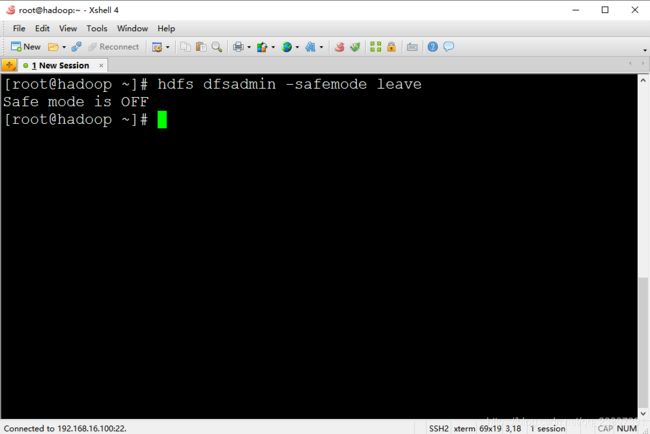
10.等待Hadoop伪分布式集群启动后,输入hdfs dfsadmin -safemode leave,回车
也可以复制该命令,进入xshell直接右键粘贴,回车
本步骤是为了关闭Hadoop安全模式
11.输入 hive,回车
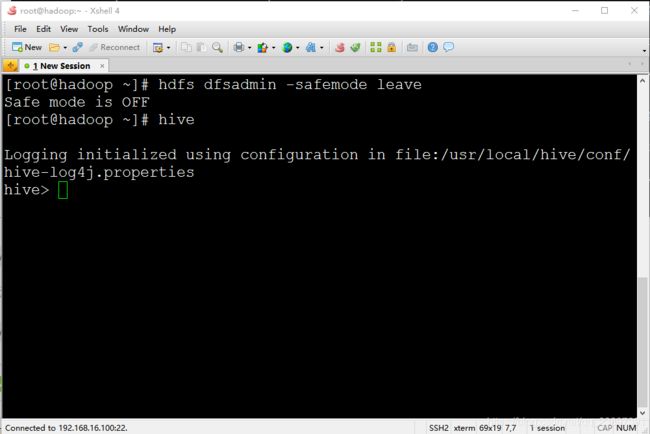
12.环境准备工作至此全部结束,关闭虚拟机时选择挂起,不要选择关机,这样下次连接时启动虚拟机后界面会仍然保持上次关机时的样子。

13.后续使用时直接启动虚拟机,然后打开Xshell,连接后直接输入hive即可。如果第12步选择了关闭客户机则需要重复第9-11步操作才能重新启动Hive。
能看到这里的同学,就右上角点个赞顺便关注我吧,3Q~