MTCNN:Multi-task Cascaded Convolutional Networks
目录
论文
背景简介
MTCNN算法简介
模型训练
实验
NMS
IOU
结论
原文
论文
Zhang K, Zhang Z, Li Z, et al. Joint face detection and alignment using multitask cascaded convolutional networks[J]. IEEE Signal Processing Letters, 2016, 23(10): 1499-1503.
原文链接:https://arxiv.org/ftp/arxiv/papers/1604/1604.02878.pdf
一种实现:https://github.com/cpuimage/MTCNN
该论文提出了一种Multi-task的人脸检测框架,将人脸检测和人脸特征点检测同时进行。
论文使用3个CNN级联的方式。
背景简介
人脸检测几种常用的方法:
- 早期的人脸检测方法是利用人工提取特征,训练分类器,进行人脸检测。例如opencv源码中自带的人脸检测器就是利用haar特征进行的人脸检测。这类方法的缺点就是在环境变化强烈的时候检测效果不理想,例如弱光条件,人脸不全。
- 从通用的目标检测算法中继承过来的人脸检测算法。例如利用faster-RCNN来检测人脸。效果不错,可以适应环境变化和人脸不全等问题,但是时间消耗很高。
- 鉴于以上两种方法的优劣势,就有人专门研究了人脸检测的算法,同时规避了以上两种的劣势,兼具时间和性能两个优势。级联结构的卷积神经网络,例如,cascadeCNN,MTCNN。MTCNN效果要比cascadeCNN要好。
目前人脸检测任务主要是有两个方面的挑战:
- 召回率:复杂背景下的人脸的尺度变化和光照等外部因素变化导致的人脸分类困难。
(在CNN方法下解决此类问题一般都是通过加入此类样本进行训练解决问题。)
- 耗时:人脸多尺度位置定位导致的时间消耗。
MTCNN算法简介
MTCNN(多任务级联卷积神经网络)由三个部分组成,P-Net(proposal Network),R-Net(refine Net),O-Net(outputNet)。
这三个部分是相互独立的三个网络结构,相互串联的关系。每个阶段的网络都是一个多任务网络,处理的任务有三个:人脸/非人脸的判断、人脸框回归、特征点定位。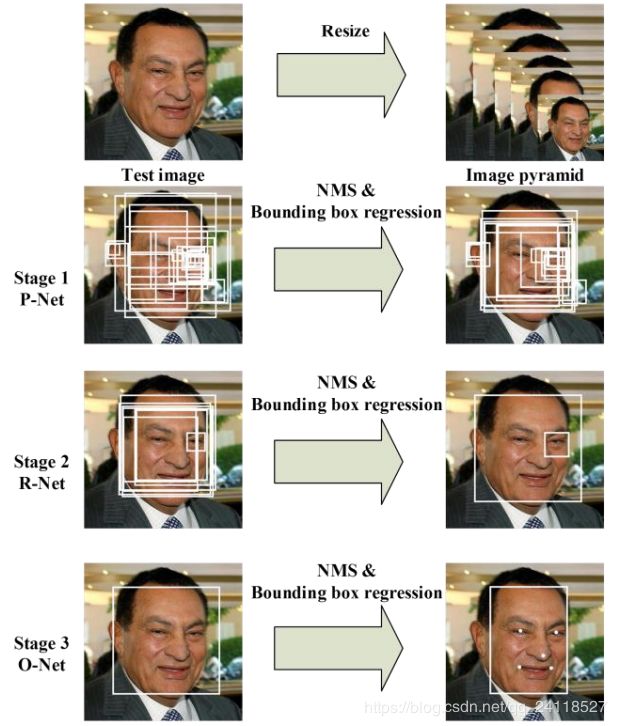
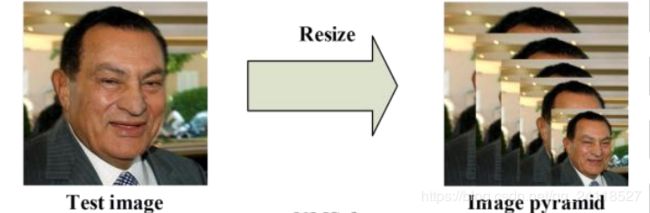
原始待检测图像经过resize,生成不同尺寸的图像构建图像金字塔作为网络的输入。
构建的图像金字塔,其层数由两个因素决定,第一个是设置的最小人脸minSize,第二个是缩放因子factor,最小人脸表示min(w,h),论文中说明最小人脸不能小于12,给出的缩放因子0.709可以根据公式计算图像金字塔的层数
minL=org_L*(12/minsize)*factor^(n),n={0,1,2,3,...,N}
其中n就是金字塔的层数,org_L是输入原始图像的最小边min(W,H),minisize是人为根据应用场景设定。在保证minL大于12的情况下,所有的n就构成金字塔的层。此时看上面那个公式,左边是常数,右边的minsize的值越小,n的取值范围就越大,计算量就相应地增加,能够检测到的人脸越小。
这一步如下图所示。
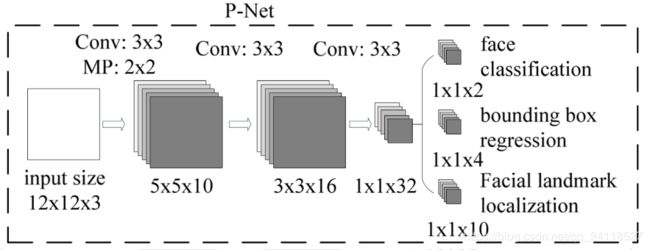
第一阶段,通过浅层的CNN(P-Net)快速生成候选窗口,该网络全部由卷积层实现,获取到候选人脸窗和人脸窗的回归向量,基于人脸窗的回归向量对人脸窗进行校正,然后对所有人脸窗进行NMS(非极大值抑制),合并高度重叠的人脸窗。其具体过程就是通过图像金字塔生成的各种尺寸大小的图片,每一张图都进行一次前向传播,在每个图上得到的结果之后利用设置的阈值去掉一部分,剩下的根据缩放尺度还原到原图上的坐标,将所有的坐标信息汇总,然后NMS去除一部分冗余。
第二阶段,通过一个更复杂的CNN来处理第一阶段中被误认为人脸的“人脸窗”从而精细化人脸窗,第一阶段的输出作为第二阶段的输入,第一阶段最后产生了大量的bbox,将这些bbox根据缩放因子回推到原图上之后,将他们全部resize到24x24大小,作为第二阶段的输入。第二阶段经过网络之后同样产生大量的bbox,同样的根据阈值去掉一部分,再利用nms去掉一部分。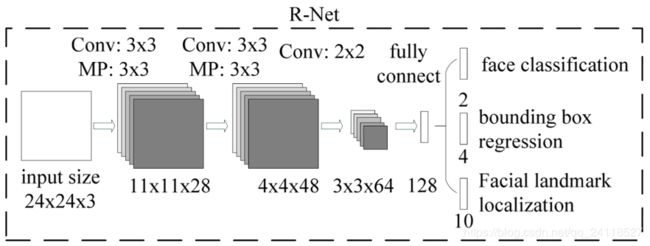
第三阶段,使用第二阶段中最后留下来的bbox,还原到原来的图片上之后,全部resize到48x48大小,然后输入到第三阶段,使用更为复杂的CNN进一步精细化结果并输出人脸上的5个特征点。


通过三阶的级联卷积神经网络对任务进行从粗到细的处理,并提出一种新的在线困难样本生成策略提升性能,最终输出人脸框位置和五个特征点位置。整个过程中会用到三次人脸窗回归和NMS,三个网络独立工作。
模型训练
这个算法需要实现三个任务的学习:人脸非人脸的分类,bounding box regression和人脸特征点定位。
- 人脸检测
这就是一个分类任务,使用交叉熵损失函数即可:
![]()
- Bounding box regression
这是一个回归问题,使用平方和损失函数:
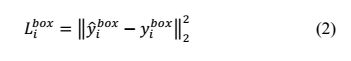
- 人脸特征点定位
这也是一个回归问题,目标是5个特征点与标定好的数据的平方和损失:
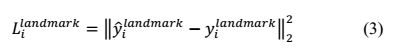
- 多任务训练
不是每个sample都要使用这三种损失函数的,比如对于背景只需要计算交叉熵损失,不需要计算别的损失,这样就需要引入一个指示值指示样本是否需要计算某一项损失。最终的训练目标函数是:
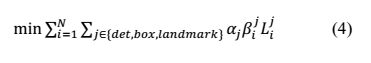

- online hard sample mining
传统的难例处理方法是检测过一次以后,手动检测哪些困难的样本无法被分类,本文采用online hard sample mining的方法。具体就是在每个mini-batch中,取loss最大的70%进行反向传播,忽略那些简单的样本。
实验
本文主要使用三个数据集进行训练:FDDB,Wider Face,AFLW。
本文将数据分成4种:
Negative:非人脸
Positive:人脸
Part faces:部分人脸
Landmark face:标记好特征点的人脸
分别用于训练三种不同的任务。Negative和Positive用于人脸分类,positive和part faces用于bounding box regression,landmark face用于特征点定位。
NMS
简单来说,输入一个图片,分类器会产生多个候选框,每个候选框会有一个得分,分数就是此框是人脸的概率。
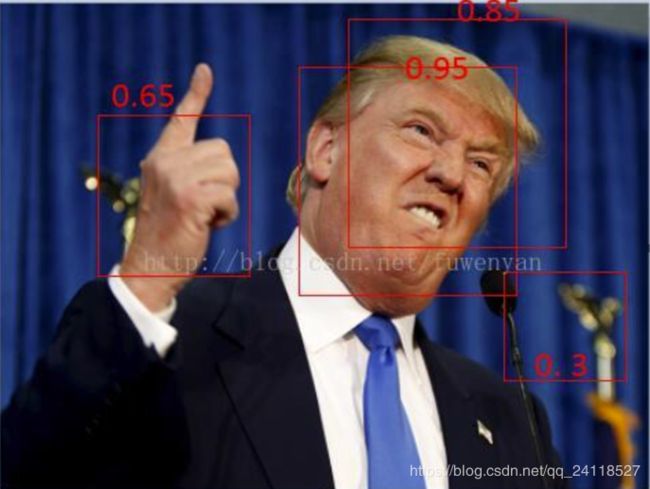
例如这张图,一共产生了4个候选框,每个候选框都有一个得分。右下角的框得分最低,如果我们这是NMS阈值为0.6,那么这个框直接被干掉。
然后川普脸上还有两个框,有一定重叠,要想去掉一个框那就得用上NMS了。
一般有两种种计算方式:IOU交/并,IOM交/max。如果比值大于阈值,那么直接干掉得分低的那个框。这里手上的框没有与其他框有交集,所以它不会被NMS干掉
其实这样传统的NMS直接干掉分数低的有点简单粗暴了,有一篇论文专门针对NMS进行了改进优化,称之为soft-nms。如果某一个框的分数较低,那么不直接将这个框干掉而是降低其置信度,通过高斯加权的方式再进行排除。
文章中指出在常规算法(faster-RCNN, MTCNN)中MAP值上升一个百分点。
soft-nms论文链接:http://cn.arxiv.org/abs/1704.04503
soft-nms算法源码:https://github.com/bharatsingh430/soft-nms
另一种说法:
非极大值抑制的方法是:先假设有6个矩形框,根据分类器的类别分类概率做排序,假设从小到大属于车辆的概率分别为A、B、C、D、E、F。
(1)从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
(2)假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
(3)从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
就这样一直重复,找到所有被保留下来的矩形框。
非极大值抑制(NMS)顾名思义就是抑制不是极大值的元素,搜索局部的极大值。这个局部代表的是一个邻域,邻域有两个参数可变,一是邻域的维数,二是邻域的大小。
这里不讨论通用的NMS算法,而是用于在目标检测中用于提取分数最高的窗口的。例如在行人检测中,滑动窗口经提取特征,经分类器分类识别后,每个窗口都会得到一个分数。但是滑动窗口会导致很多窗口与其他窗口存在包含或者大部分交叉的情况。这时就需要用到NMS来选取那些邻域里分数最高(是行人的概率最大),并且抑制那些分数低的窗口。
IOU

IoU=(A∩B)/A∪B
结论
MTCNN方法在FDDB数据库上测试的结果是0.95。(在1000次误检情况下的准确率)
- MTCNN的检测速度跟待检测人脸的数量有很大关系,当人脸数量变多之后,检测耗时上升会非常明显。
- 在CPU上时间消耗比较严重
- 侧脸进行人脸对齐的时候,特征点位置不准确。
针对MTCNN的优化版本已经有很多了,例如原文作者用过两种:
- MTCNN-light,作者将caffemodel文件转成了txt,不再依赖caffe框架,只依赖openmp,在cpu平台下运行,多线程处理速度不错,但是检测效果略有下降。
- MTCNN-AccelerateONet,专门针对最后的ONet网络进行了加速,在GPU上加速很明显。但是速度依然会受人脸数量的影响。
dropout层在神经网络中的应用目的就是防止网络层数过多出现过拟合,根据设置的dropout_ratio参数随机停止部分神经元工作,然后输出多种情况下的平均值,这样防止出现训练过拟合。这里的改动直接将卷积层输出参数去掉一半,然后不要dropout,重新训练就可以得到和原网络差不多的效果。这种方法可以值得我们借鉴。
这种方法也是一种由粗到细的方法,和Viola-Jones的级联AdaBoost思路相似。
类似于Viola-Jones:1、如何选择待检测区域:图像金字塔+P-Net;2、如何提取目标特征:CNN;3、如何判断是不是指定目标:级联判断。