HBase学习笔记 (一)
一、HBase初窥使用

1. HBase能做什么及企业海量数据实时查询的需求

该车牌号码1千多条数据的时候、2万条数据的时候的查询速度。HBase表中的数据可以快速查询,关键在于rowkey的设计。
热数据:
经常使用的数据,或近期使用的数据,存储在mysql中。
冷数据:
不经常使用的数据,或近期不使用的数据,存储在hbase中。

HBase依赖于zookeeper进行协作服务。
2. HBase架构设计及表的存储设计
HBase架构:
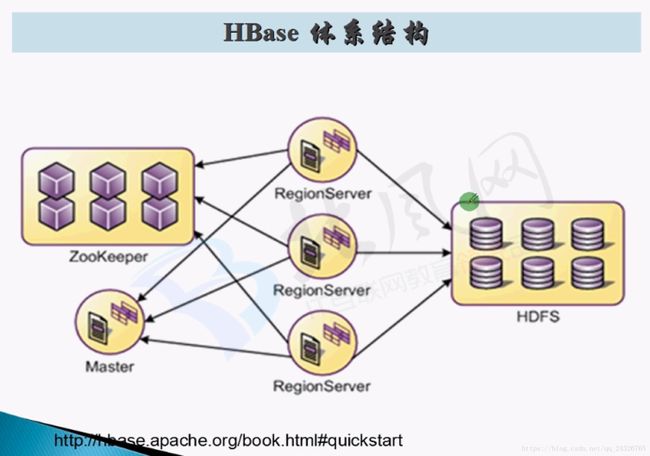
一个reginserver管理一个区域的数据。
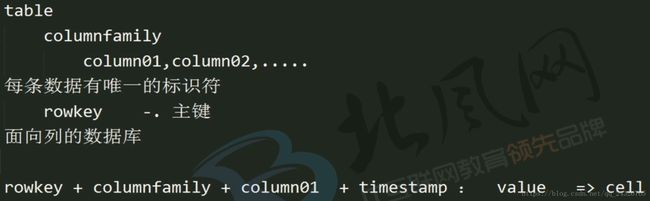
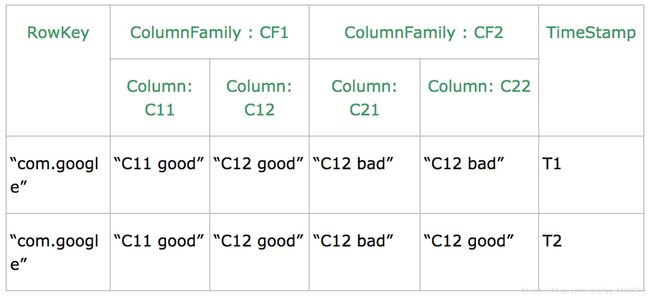
HBase表设计:
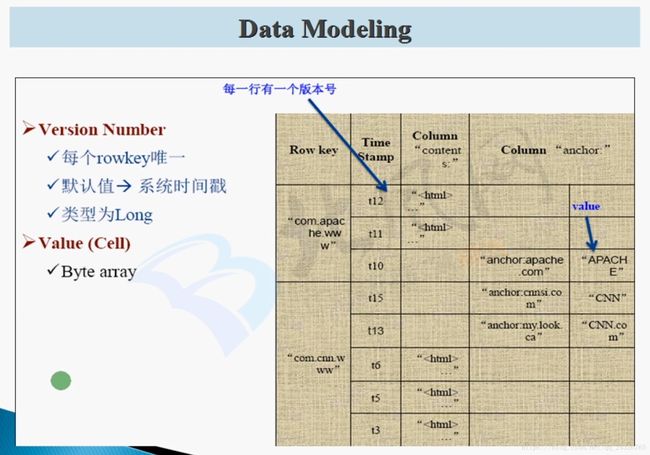
3.HBase版本及数据存储模型讲解
版本介绍:
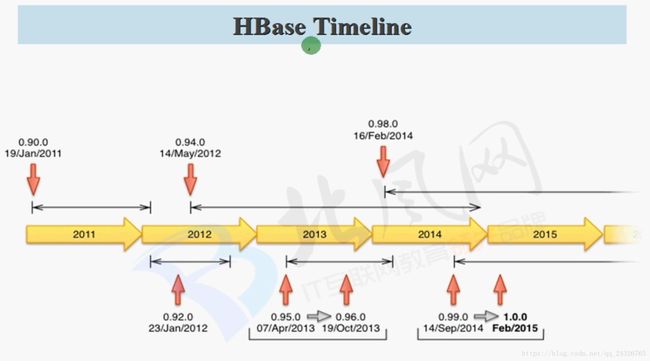
0.98这个版本特别稳定。
数据存储模型:

以字节进行存储,这就用到Bytes工具类进行相互转换。
有的列没有值是不占空间的,因为是以列的形式存储。而rdbms有的字段没有值,为null,是占用空间的。

4.HBase部署架构及安装部署启动
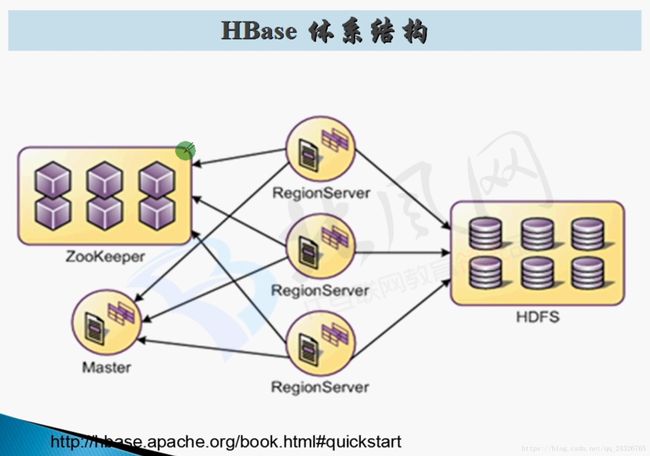
对表进行操作的过程:
客户端先连接zookeeper,查找要操作的表的信息,即被哪个regionserver管理,然后客户端再连接该regionserver进行处理。
Master:
Master只是管理regionserver,哪个regionserver出现异常,进行处理。客户端不经过Master,而是直接与regionserver进行交互。
Hbase的安装:
① 解压
[root@hadoop-senior software]# tar-xzvf hbase-1.2.0-cdh5.13.0.tar.gz -C ../cdh5.13.0/
② 修改hbase-env.xml
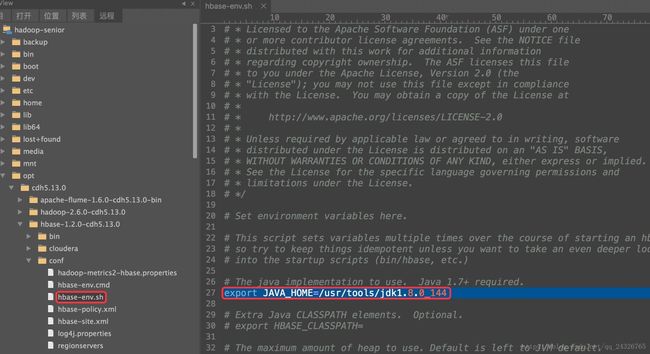
这里先让hbase使用自己的zookeeper,如果要使用我们安装的zookeeper要修改如下配置:
![]()
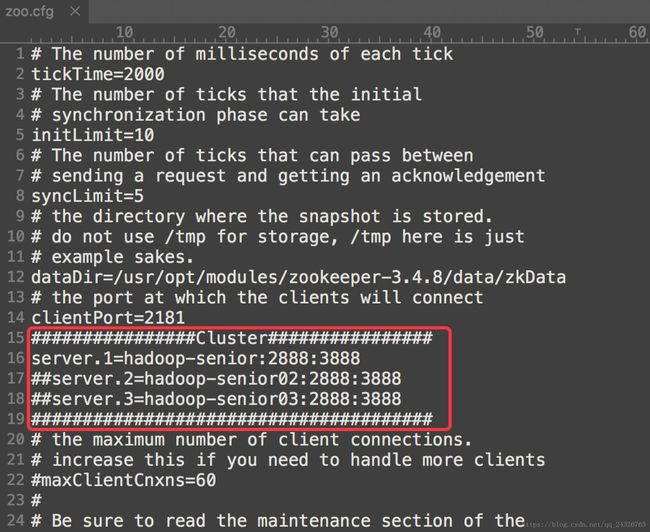
修改为false,并修改zookeeper配置文件zoo.cfg:
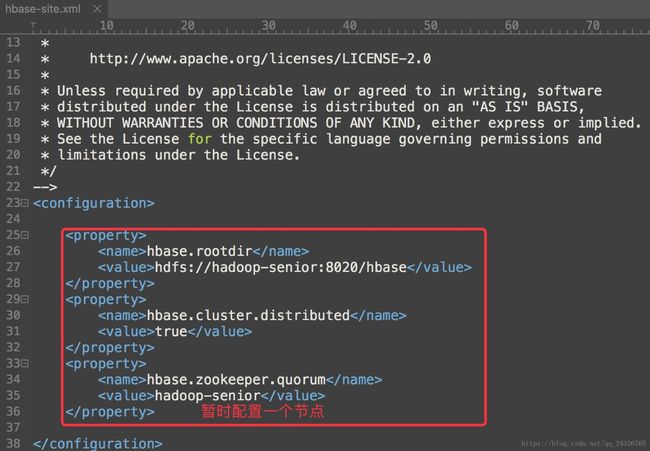
③ 修改hbase-site.xml
|
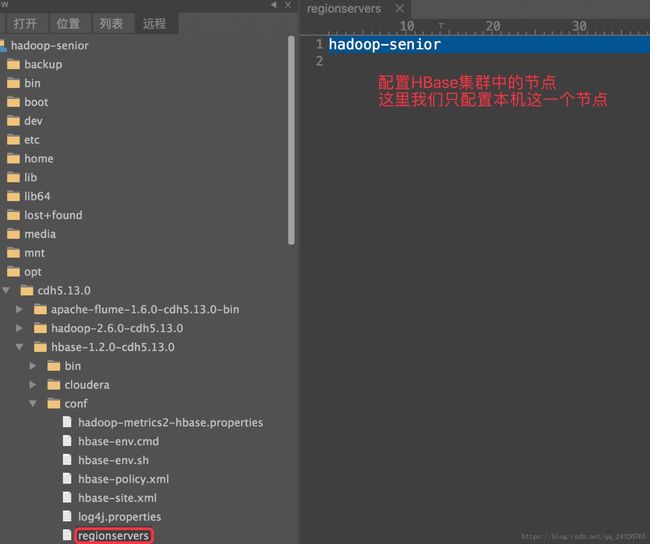
④ 修改regionservers
⑤ 启动HBase
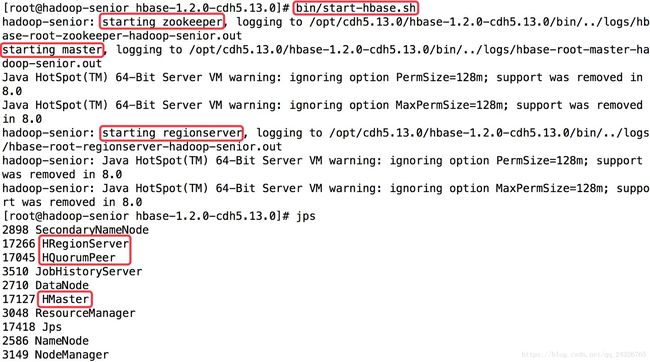
⑥ 查看
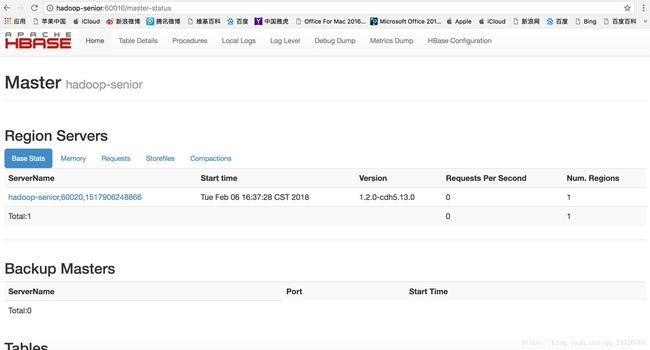
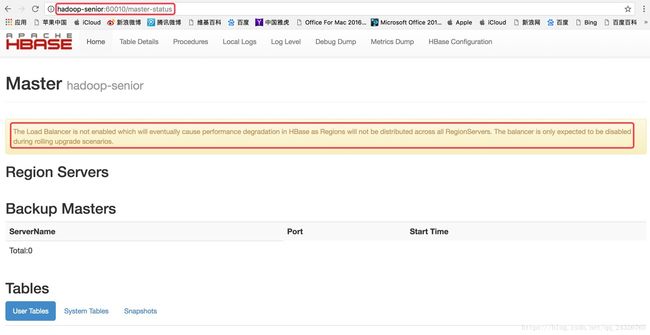
可能出现的异常:
查看日志:
[root@hadoop-senior hbase-1.2.0-cdh5.13.0]#tail -200 logs/hbase-root-master-hadoop-senior.log
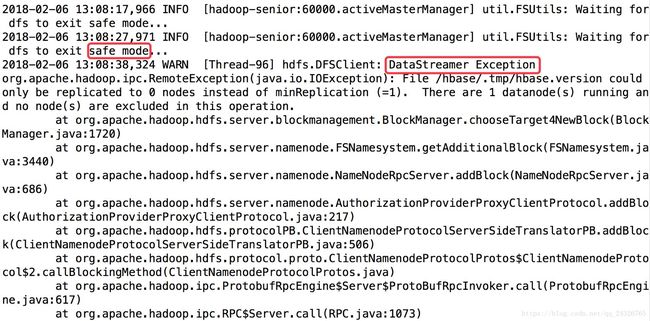
发现没有退出安全模式
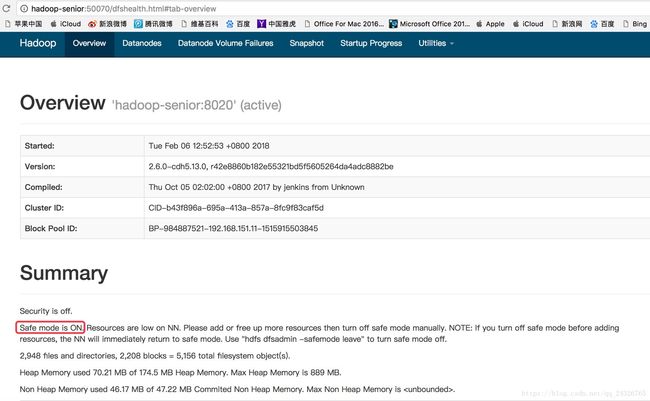
发现磁盘容量已用完

解决:清理磁盘或者扩容。
5. HBase Shell基本使用(创建表,对数据的CRUD操作)
进入Hbash Shell:
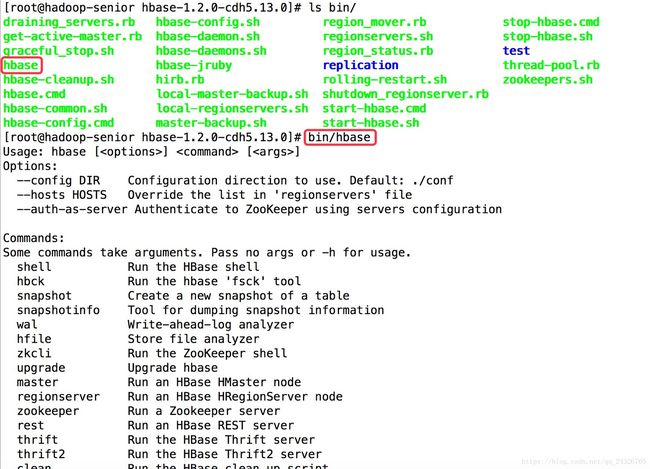
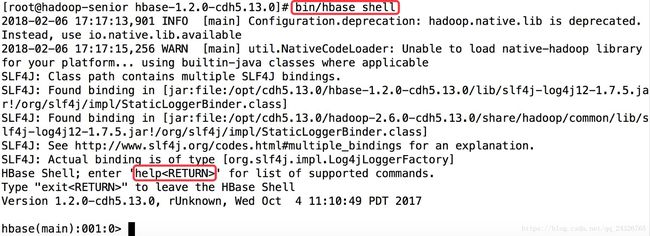
查看所有命令:

查看某个命令的用法:

创建表:
create 表名,列簇
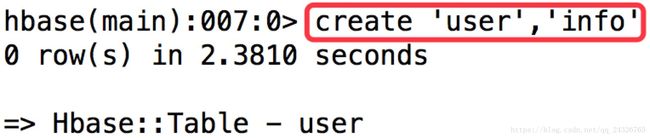
查看表结构:

插入数据:
put 表名,rowkey,列簇:列名,列值
put 'user','10001','info:name','zhangsan' put 'user','10001','info:age','25' put 'user','10001','info:sex','male' put 'user','10001','info:address','Shanghai'
put 'user','10002','info:name','lisi' put 'user','10002','info:age','18' put 'user','10002','info:sex','female' put 'user','10002','info:address','Beijing'
put 'user','10003','info:name','zhuyu' put 'user','10003','info:age','22' put 'user','10003','info:sex','male' put 'user','10003','info:address','Zhengzhou' put 'user','10003','info:email','[email protected]' put 'user','10003','info:QQ','362973941' |
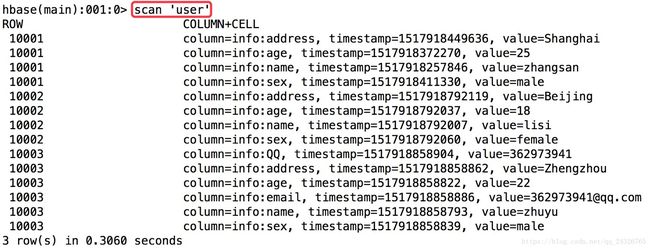
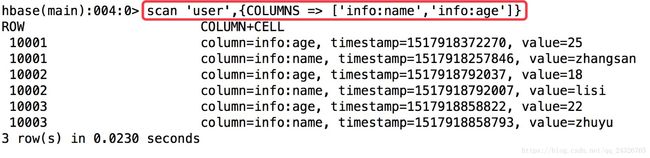
数据查询的三种方式:

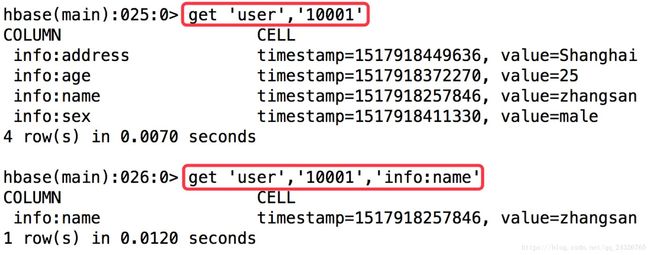
(按照列排序)

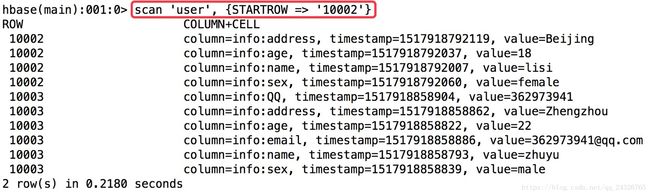
删除数据:
不是立即就删除,而是先打上标签(在进行查询的时候就过滤掉),在storeFile进行合并的时候再进行删除。
删除某个列:
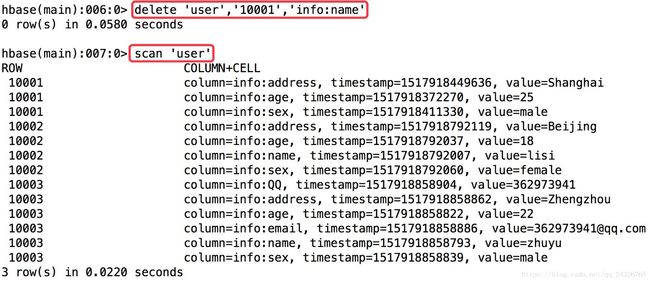
删除某个rowkey的所有数据:

数据的更新:
没有更新,列有多个版本(timestamp),只要添加新版本(timestamp)就行。
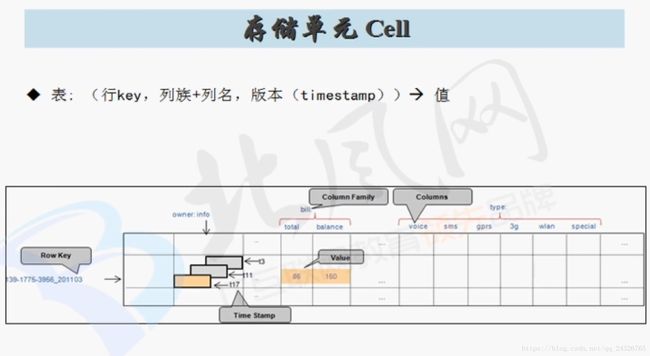
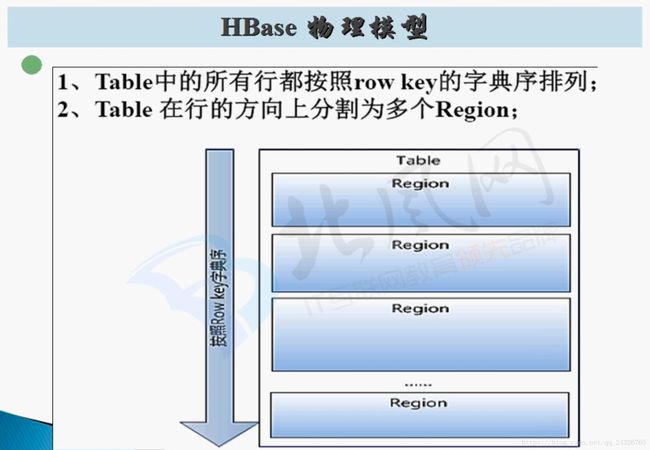
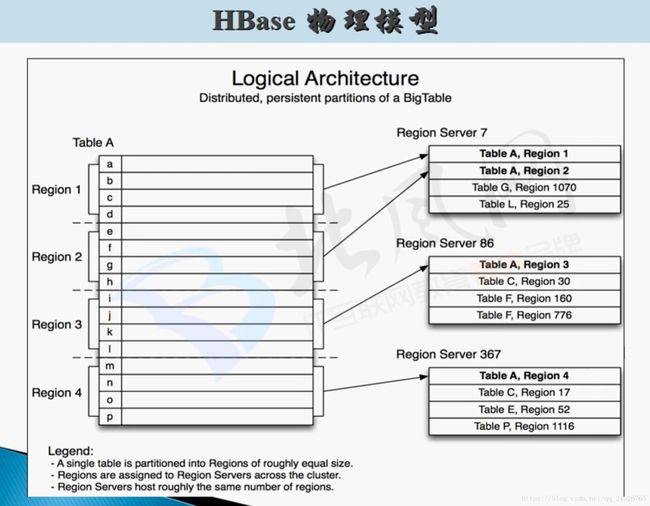
6. HBase 表的物理模型讲解
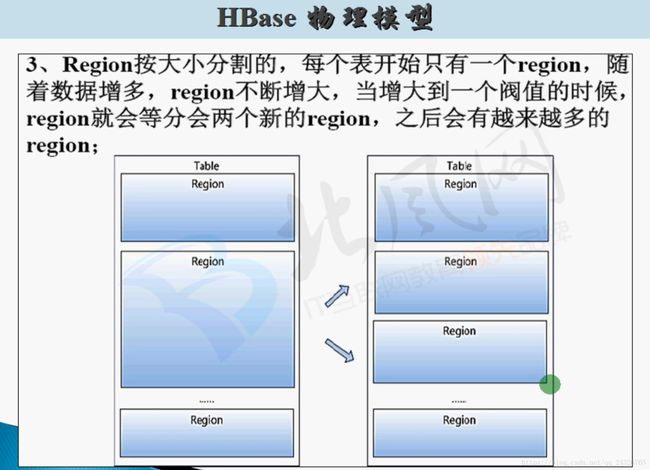
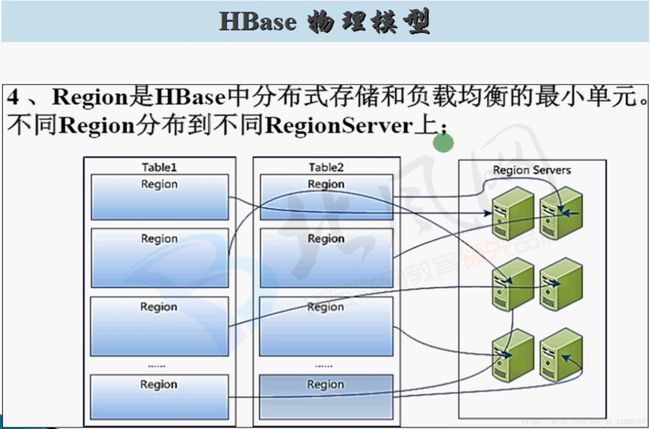
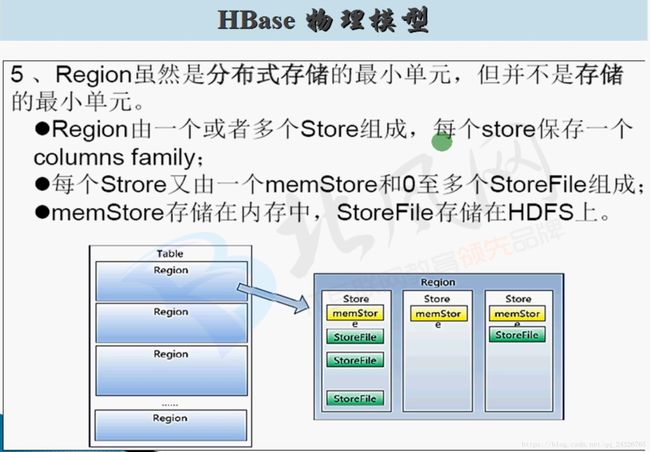
HBase数据写入流程:

预写日志(格式:sequencefile)是为了防止数据还未写到storeFile中,memstore就挂掉了导致数据丢失。
HBase数据读流程:
客户端通过zookeeper找到要读取的数据所在regionserver,通过regionserver找到数据所在的region,然后先读取store中的memstore的数据(防止部分数据还未溢写到storeFile中),再读取storeFile中的数据,最后将多个region中读到的数据合并。
7. 回顾HBase功能、架构和设计
HBase功能:

数据安全性:副本。
HBase需要开启的服务:

HBase表的设计:

NoSQL用于超大规模数据的存储。(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据)。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
HBase表的物理模型:
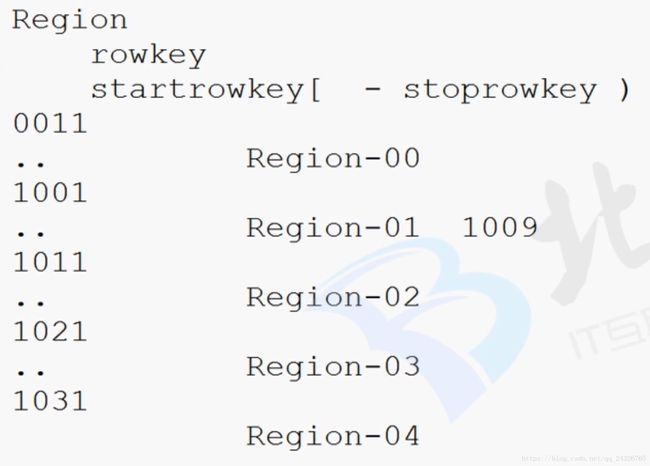
[ startrowkey,stoprowkey ]包头不包尾。
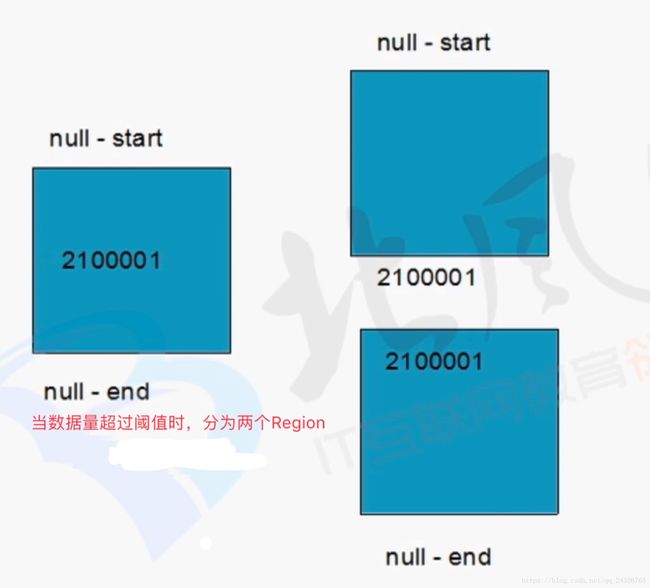
8. HBase中表的Region深入讲解

因为表在刚创建时,不知道rowkey是什么样的形式,startkey和endkey是未知的,所以为null。当来数据的时候,就插入到该region中,当数据量到达阈值的时候,取一个rowkey作为中间值,进行划分,再产生一个新的region。所以除了第一个region和最后一个region,中间的region的startkey和endkey都是确定的。