Hive学习笔记 (二)
一、Hive深入使用

1. Hive中数据库Database基本操作
创建数据库
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name [COMMENT database_comment] [LOCATION hdfs_path] [WITH DBPROPERTIES (property_name=property_value, ...)]; |
create database IF NOT EXISTS db_hive_01;
create database IF NOT EXISTS db_hive_02 LOCATION '/user/zhuyu/hive/warehouse/db_hive_02.db';(指定数据库存放位置) |


查看数据库:

删除数据库:
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
|

(注意:假如手动去HDFS上删除数据库或表的文件夹,在hive中依旧是可以查到的,但是数据是没有的。并且下次加载数据时,会自动创建)
2. Hive中表的创建及常见的三种创建表的方式及应用
方式一:创建原始表
create table IF NOT EXISTS default.bf_log_20180107 ( ip string COMMENT 'remote ip address', username string, req_url string COMMENT 'user request url' ) COMMENT 'BeiFeng Web Access Logs' ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/user/zhuyu/hive/warehouse/bf_log_20180107';(指定表的存储位置) |

加载数据:


方式二:根据原始表创建子表
原始数据表数据量教大,我们只需要其中某几个字段,那么我们可以把那些字段抽取到一个表里进行处理,这样数据量就小了,处理速度就快了。
create table IF NOT EXISTS default.bf_log_20180107_sa AS select ip,req_url from bf_log_20180107; |




方式三:克隆表结构
当数据量较大时,将每天的数据存储到一个新的结构相同的表。
create table IF NOT EXISTS default.bf_log_20180108 LIKE default.bf_log_20180107; |

3. Hive的数据类型讲解及实际项目中如何使用phthon脚本对数据进行ETL

4. 以【雇员表和部门表】为例创建讲解Hive中表的操作

create table IF NOT EXISTS default.emp( empno int, ename string, job string, mgr int, hireddate string, sal double, comm double, deptno int ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; load data local inpath '/root/emp.txt' overwrite into table default.emp; |
create table IF NOT EXISTS default.dept( deptno int, dname string, loc string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; load data local inpath '/root/dept.txt' overwrite into table default.dept; |


(注意:数据格式一定要是UTF-8否则会出错)


5. Hive中外部表的讲解(对比管理表)

企业中百分之80都是外部表。

删除外部表时,只会删除mysql中的元数据,而你location的文件夹和文件不会删除。
如何查看是内部表还是外部表

创建外部表:
create EXTERNAL table IF NOT EXISTS default.emp_ext(
empno int,
ename string,
job string,
mgr int,
hireddate string,
sal double,
comm double,
deptno int
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION '/user/zhuyu/hive/warehouse/emp_ext';
( 默认的都存储在/user/hive/warehouse/下;一般直接指定到日志文件所在的文件夹,不需要导入数据,例如:/hdfs/weblogs )
load data local inpath '/root/emp.txt' overwrite into table default.emp_ext;
( 把txt文件直接放到location指定的目录也可以 )

应用场景:
搞网站的,每天把网站日志放在指定目录,如下图:
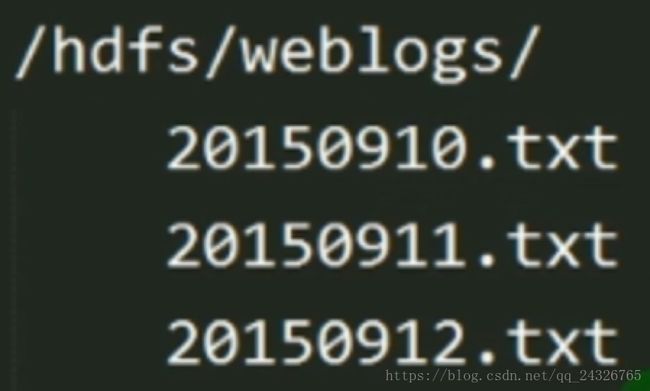
如果多个部门都需要使用,则需要复制到本部门的文件夹下,这样就造成日志份数有好几份,多余了如下图:

6. Hive中分区表讲解

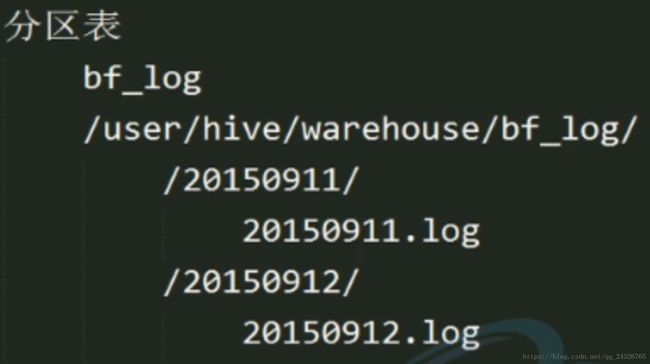
创建分区表:
create table IF NOT EXISTS default.emp_partition(
empno int,
ename string,
job string,
mgr int,
hireddate string,
sal double,
comm double,
deptno int
)
PARTITIONED BY(month string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';

加载数据到分区表:
load data local inpath '/root/emp.txt' overwrite into table emp_partition partition(month='201801'); |
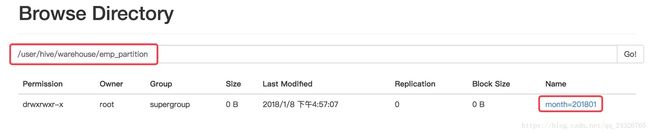
查看某个表的所有分区:

查询某个分区的数据:

实例:
统计日志文件中某几个月的ip个数:
select count(DISTINCT ip) from log_partition where month='201711' UNION select count(DISTINCT ip) from log_partition where month='201712' UNION select count(DISTINCT ip) from log_partition where month='201801'; |
总共5个mapreduce:三个查询+两个union
一般都放在hive脚本中执行:

二级分区:

注意:
非分区表,把数据直接放到表下,select能查出来数据。而分区表,在表目录下创建分区字段文件夹(例:month=201801文件夹),将数据放到该文件夹中,select查不出来数据。


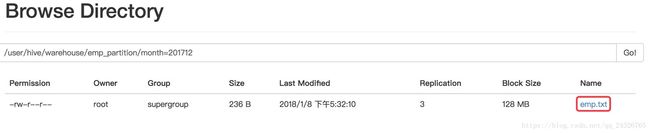
为什么?
因为分区是要保存到元数据中的,而你手动创建分区文件夹,手动将数据放进去,并没有生产分区的元数据。
在mysql中的hive数据库中的partition表中:

解决方法:
方式一:修复表(不常用)
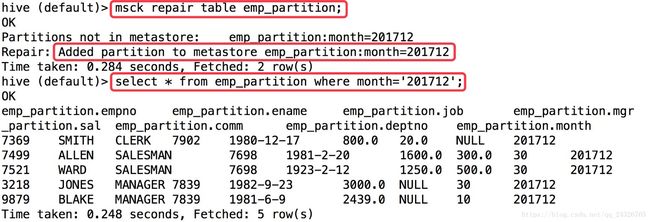

方式二:添加分区
alter table emp_partition add partition(month=201712)
而且这种方式经常在脚本中使用:

每天的日志都会像这样:1.创建分区目录2.将当天的日志文件添加到所创建分区目录中3.添加分区
查看一个表的分区数:

7. 导入数据进入Hive表的六大方式



8. 导出Hive表数据的几种方式
方式一:不指定格式
insert overwrite local directory '/root/hive_exp_emp' |

方式二:指定格式
insert overwrite local directory '/root/hive_exp_emp' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' select * from emp; |

方式三:hive命令导出
bin/hive -e "select * from emp;" > /root/exp_res.txt |

方式四:将数据导入HDFS上,再从HDFS上get
insert overwrite directory '/user/zhuyu/hive/hive_exp_emp' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' select * from emp; |
![]()

引出:

9. Hive中常见的查询







(全连接=左连接+右连接)
10. Hive中数据导入导出Import和Export的使用
和mysql数据库中的导入导出类似

导出:
export table default.emp to '/user/zhuyu/hive/export/emp_exp';




导入:
create table db_hive.emp like default.emp; import table db_hive.emp from '/user/zhuyu/hive/export/emp_exp/emp.txt' |
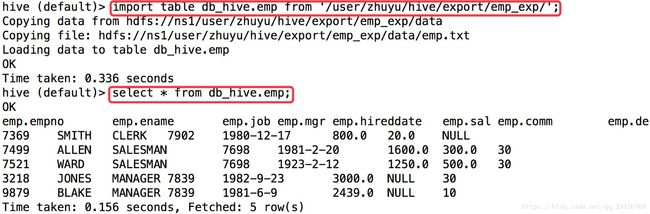
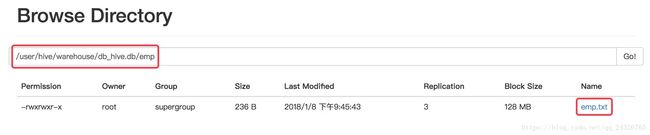
所有导入、导出实例:

11. Hive中order by、sortby、distribute by和cluster by

order by:


![]()
sort by:


![]()


distribute by:

cluster by:


12. Hive中自带Function使用及自定义UDF编程及使用
一个公司的自定义函数达到上百个,上千个。
自带函数的查看及使用:

自定义函数:



① 创建maven项目并添加依赖
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>2.7.4version>
dependency>
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-jdbcartifactId>
<version>2.2.0version>
dependency>
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-execartifactId>
<version>2.2.0version>
dependency>
② 写定义一个类继承UDF并实现evaluate方法


main方式只是测试用,最终调用的是evaluate方法。
可添加描述信息,以供desc查看:

③ 打成jar包

④ 使用FileZilla放到linux系统下

⑤ 进入hive CLI创建UDF
方法一:
hive > add jar jar包路径 hive > create function 函数名 as “包中类的全名” |


方法二:
首先将jar包上传到hdfs上
![]()
create function self_lower AS 'com.zhuyu.senior.hive.udf.LowerUDF' using jar 'hdfs://hadoop-senior:8020/user/zhuyu/hive/jars/hiveudf.jar'; |
