自然语言处理与词嵌入
词汇表特征
有一个词典,里面有10000个单词。使用one-hot的表示方法,每个单词的表示向量有10000个元素,单词对应的位置为1,其他位置为0。比如,单词”Man”在词典的5391位,那么”Man”的表示向量为 ⎡⎣⎢⎢⎢⎢⎢⎢⎢⎢0⋮1⋮0⎤⎦⎥⎥⎥⎥⎥⎥⎥⎥ [ 0 ⋮ 1 ⋮ 0 ] ,”1”在第5391位。
这样表示单词有一个缺点,就是去掉了单词之间的相关性。假设模型学会了”I want a glass of orange (juice)”,但是却不会填”I want a glass of apple (?)”,因为模型不知道”orange”和”apple”是同一类的单词。
词嵌入法使用特征化表示向量,称为嵌入向量,比如
| - | Man | Woman | King | Queen | Apple | Orange |
|---|---|---|---|---|---|---|
| Gender | -1 | 1 | -0.95 | 0.97 | 0.00 | 0.01 |
| Royal | 0.01 | 0.02 | 0.93 | 0.95 | -0.01 | 0.00 |
| Age | 0.03 | 0.02 | 0.7 | 0.69 | 0.03 | -0.02 |
| Food | 0.04 | 0.01 | 0.02 | 0.01 | 0.95 | 0.97 |
纵轴表示单词的某种特征性质。比如”Man”和”Woman”有性别特征,第一栏的数值的绝对值比较大。”King”和”Queen”有性别与高贵的特征和年龄,对应的数值的绝对值接近1。”Apple”和”Orange”是食物,食物一栏的数值绝对值接近1。其他与单词不相关的特征对应的数值都比较小,接近0。通过特征化,每个单词都使用特征向量来表示。
假设单词的特征向量高达3000维,使用映射算法把3000维的向量映射为2D的向量,把单词的特征向量可视化,如下图:
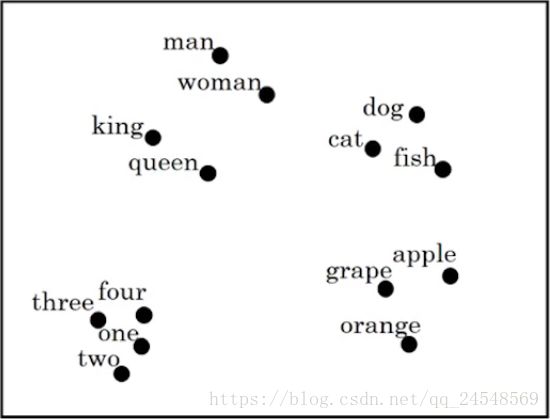
可以看到,词性相近的单词都靠得比较近,比如”man”和”woman”靠在一起,水果”apple”,”grape”和”orange”靠得比较近。
这种方法叫做词嵌入法,因为相当于把单词嵌入到n维的坐标系中(n是特征向量的长度)。
使用词嵌入
使用词嵌入模型需要非常大的数据集(1B-100B个单词)。可以使用迁移学习来训练得到词嵌入模型。第一步,从一个非常大的语料库中学习词嵌入模型,可以从网上找已经训练好的词嵌入模型,或者从网上下载免费的语料库,自己训练词嵌入模型。第二步,把词嵌入模型迁移到自己的任务中,比如词嵌入模型使用的特征向量长10000个单词,自己的训练数据使用的特征向量长300个单词,需要做一些转换。第三步,根据自己的训练集的大小决定是否对词嵌入模型进行微调。
词嵌入特性
| Man | Woman | King | Queen | Apple | Orange |
|---|---|---|---|---|---|
| Gender | -1 | 1 | -0.95 | 0.97 | 0.00 |
| Royal | 0.01 | 0.02 | 0.93 | 0.95 | -0.01 |
| Age | 0.03 | 0.02 | 0.7 | 0.69 | 0.03 |
| Food | 0.04 | 0.01 | 0.02 | 0.01 | 0.95 |
观察上面的单词特征,使用 eman e man 表示”Man”的特征向量,使用 ewoman e woman 表示”Woman”的特征向量,使用 eking e king 表示”King”的特征向量,使用 equeen e queen 表示”Queen”的特征向量。如果”Man”对应”Woman”,那么”King”对应什么呢?即 eman−ewoman≈eking−e? e man − e woman ≈ e king − e ? ?
eman−ewoman≈⎡⎣⎢⎢⎢−2000⎤⎦⎥⎥⎥ e man − e woman ≈ [ − 2 0 0 0 ] 。 eking−equeen≈⎡⎣⎢⎢⎢−2000⎤⎦⎥⎥⎥ e king − e queen ≈ [ − 2 0 0 0 ] 。 eman−ewoman≈eking−equeen e man − e woman ≈ e king − e queen 。从这些公式可以看出”Man”和”Woman”,”King”和”Queen”的主要差别在于性别不同。根据上面的公式,我们可以确定地说”King”对应”Queen”。这种推理方式可以使用上述的公式来实现,这就是词嵌入的特性。
上述的问题使用另外一种描述方式。找到一个单词w,使得 argmaxw sim(ew,eking−eman+ewoman) a r g m a x w sim ( e w , e king − e man + e woman ) 。sim表示相似度。
最常用的相似度函数是余弦相似度函数。余弦相似度函数公式如下:
余弦相似度求u和v夹角的余弦值,相似度越高,夹角越小,余弦值越靠近1;反之,相似度越低,夹角越大,余弦值越靠近-1。
相似度函数还可以使用平方距离或者说欧式距离, ∥u−v∥2 ‖ u − v ‖ 2 。
词嵌入可以学习类比推理,这是词嵌入的一个显著的成果。
嵌入矩阵
词典中的单词和特征组成一个矩阵
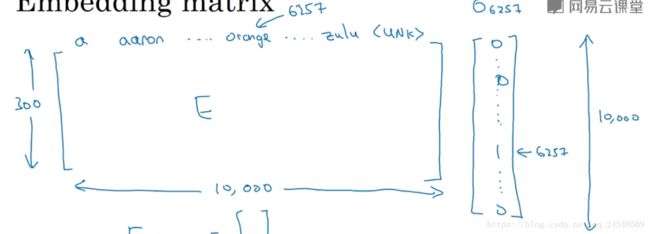
使用E表示,E就是嵌入矩阵。单词”orange”在词典中的第6257位,它的one-hot向量是 o6257 o 6257 。 Eo6257 E o 6257 的结果是”orange”的特征向量 e6257 e 6257 。
定义 oj o j 是词典的第j个单词的one-hot向量, Eoj E o j 表示第j个单词的特征向量。one-hot向量是一个非常大的向量, Eoj E o j 运行很慢,因为 oj o j 几乎全为0,所以在实际实现时直接从E中找到 ej e j 。
学习词嵌入矩阵
学习嵌入矩阵的算法刚开始提出来时比较复杂,经过不断地发展,算法越来越简单。首先来学习比较复杂的算法。
首先我们看看一个神经语音模型是如何预测句子的
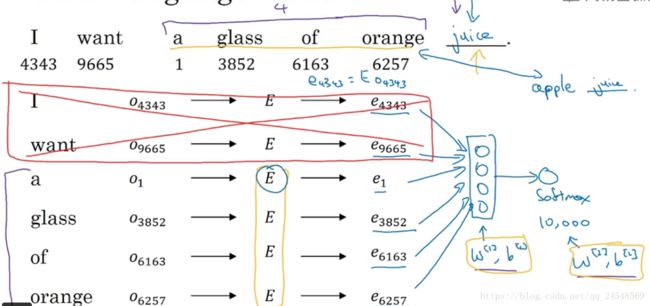
要预测句子”I want a glass of orange (?)”,首先把前面的单词都转成嵌入向量,接着传入神经网络中,使用softmax求出词典单词是目标单词的概率。可能神经网络只能输入4个嵌入向量,句子的开头两个单词不是很重要,那么可以去掉这两个单词的嵌入向量。
skip-gram算法使用目标单词和上下文来学习嵌入矩阵。假设预料库有这样一句”I want a glass of orange juice to go along with my cereal.”。假设语言模型要预测”juice”,”juice”就是目标单词,我们需要选择上下文来预测目标单词。上下文有许多选择,比如离目标单词最近的4个单词,或者说是最近的1个单词,又或者是附近的1个单词。

学习词嵌入的算法越简单,选择的上下文就越简单。
skip-gram算法在句子中随机选择一个单词作为上下文,然后在前后的一定间距随机选择目标单词,比如上下文是”orange”,目标单词可以是”juice”、”glass”、”my”等。
skip-gram模型的目标是学习一个从上下文到目标单词的映射函数。假设词典有10000个单词,选择的上下文和目标单词如下
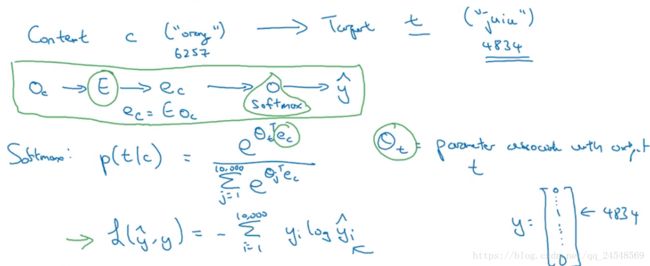
计算上下文的嵌入向量 ec e c ,带入softmax的神经网络,求出各个单词是目标单词的概率, θt θ t 表示目标t的参数。
skip-gram的一个缺点是运算慢,特别softmax计算。当词典非常大时,求概率的操作中,分母是一个求和的操作,10000个数求和操作非常慢。
在对上下文和目标单词采样时,要注意不要随机采样,避免选择太多辅助单词,比如”the”,”a”等。应该有选择地选择名词或动词等有意义的词汇。
负采样
定义一个新的学习问题。从预料库中选择一个上下文,然后随机选择一个单词,如果这个单词和上下文有联系,则监督学习的y设为1,没有联系的设为0,例如
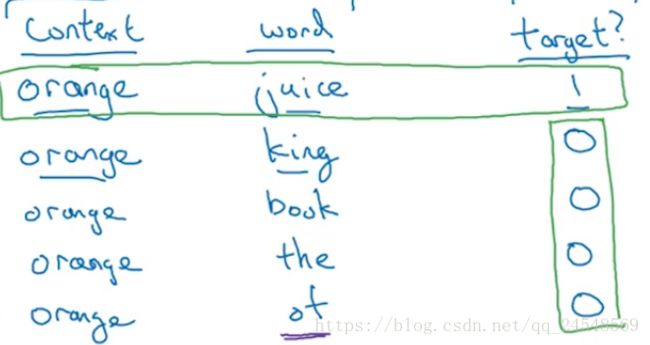
定义context为c,word为t,target为y。 y=1 y = 1 的一行为正样本, y=0 y = 0 的为负样本。定义负样本的数量为k。如果训练集少,k设计为5-20,如果训练集多,k设计为2-5。
这样把多分类问题变为二元分类问题,
这样,每次迭代只需要学习k+1个分类,不像softmax那样学习所有的分类,加快了训练时间。
在负样本采样中,要注意如何采集负样本,一种极端是根据词频来选择,这会导致高频词”the”,”a”经常出现在负样本中。另外一种极端是均匀采样,设词典的大小为 |v| | v | ,单词被采集到的概率为 1|v| 1 | v | 。发明负样本技巧的作者发现单词被采集的概率在 f(wi)3/4∑10000j=1f(wi)3/4 f ( w i ) 3 / 4 ∑ j = 1 10000 f ( w i ) 3 / 4 和 1|v| 1 | v | 之间最合适,其中 f(wi) f ( w i ) 表示单词i的词频。
GloVe
GloVe(global vectors for word representation)是另外一种词嵌入学习算法。
定义 Xij X i j 是i出现在上下文j的次数。这里的上下文指的是单词前后方向最近的几个单词,所以有 Xij=Xji X i j = X j i
GloVe模型要实现下面的目标
其中 f(Xij) f ( X i j ) 是加权项,当 Xij=0 X i j = 0 时, f(Xij)=0 f ( X i j ) = 0 ,确保当 −logXij − l o g X i j 为无穷大时, f(Xij)(∗)=0 f ( X i j ) ( ∗ ) = 0 ,保证上下文j和目标i有联系,至少 Xij=1 X i j = 1 。 f(Xij) f ( X i j ) 函数可以减少”the”、”a”之类的高频词的权重,增加有意义的词的权重。
这个公式有趣的地方是 θi θ i 和 ej e j 的作用完全一样,它们的位置可以互换,在训练时一致地初始化 θi θ i 和 ej e j ,最后 efinalw=θw+ew2 e w final = θ w + e w 2 。
在线性代数中, (Aθi)T(A−Tej)=θTiATA−Tej=θTiej ( A θ i ) T ( A − T e j ) = θ i T A T A − T e j = θ i T e j , θi θ i 和 ej e j 可以有多个值,在GloVe中要考虑这点影响。
情绪分类
目前,情绪分类的标记的数据集数量不多,有了词嵌入,即使中等的标记的数据集也能得到很好的分类结果。
情绪分类,需要把语气词或语气句子,映射成特定的评价标准。比如在一家餐厅,把客人的评论映射成客人对餐厅的好评度,好评度分为5个等级

来看一个分类例子,计算所有单词的嵌入向量,然后求平均值,把嵌入向量的评价值作为输入,传入到一个简单的神经网络中,最后通过softmax算出好评度。
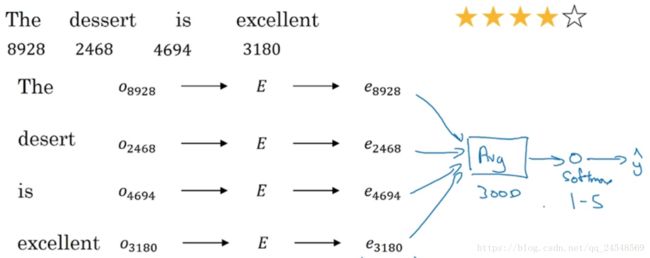
有一种特殊情况,假如评论是”Completely lacking in good taste, good service, and good ambience.”,这是一个差评,应该只有1颗星。但是句子中有3个”good”,分类器可能把它当成5星好评。所以我们需要一个更复杂的分类器。
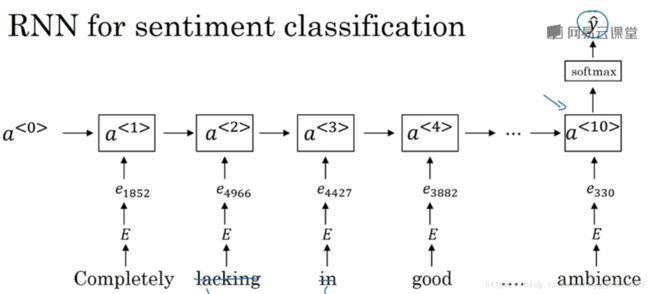
更复杂的分类器使用RNN
词嵌入消除偏见
在语料库中,可能会存在一些偏见,比如种族偏见,性别歧视等,这些偏见会对语言模型造成不良影响。
为了消除偏见,第一步,要找到词嵌入的偏见趋势,比如性别偏见
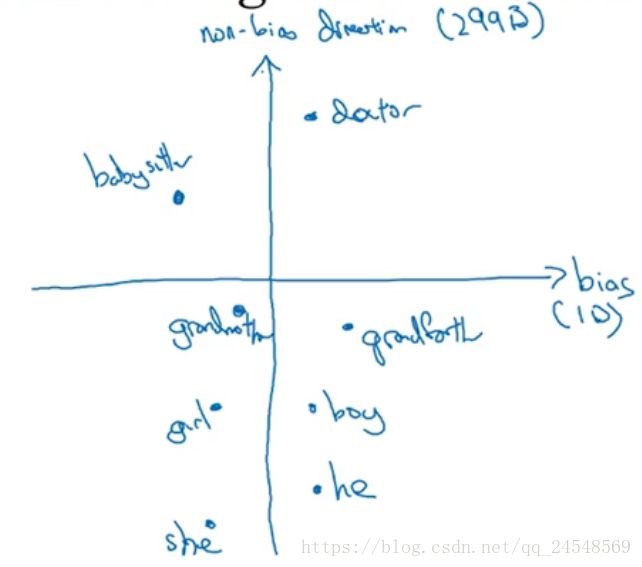
这里性别偏见是在1维,一个简单的消除偏见方法是对 ehe−eshe e he − e she 和 emale−efemale e male − e female 取平均值。
但是偏见也可能在多个维度,取平均值的方法行不通,需要更加复杂的方法SVU,即奇值分解。
第二步,中和步,对于定义不明确的中性单词,比如”babysister”、”doctor”,消除它的偏差。把中性词嵌入向量映射到非偏见维上
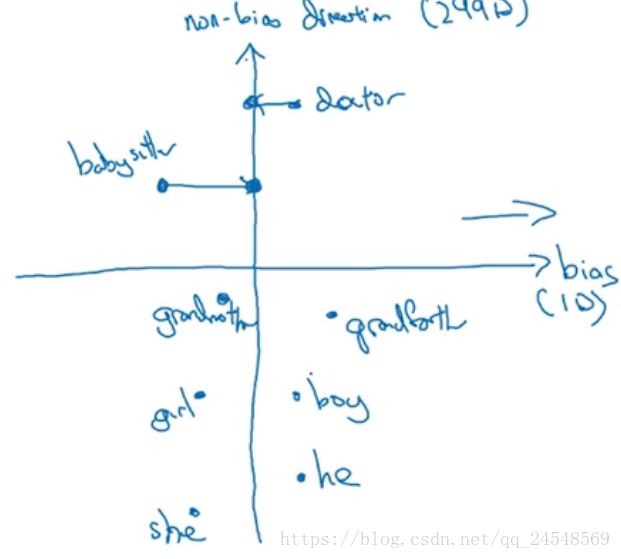
另外一张图表现更清晰
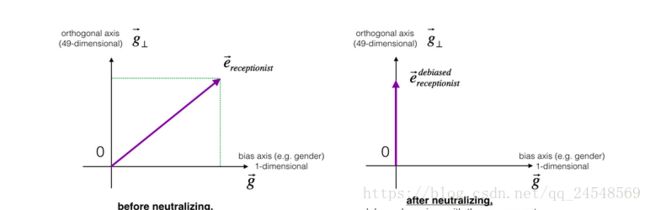
计算公式是:
第三步,均衡步。对于”girl”和”boy”,”grandmother”和”grandfather”,我们希望保留它们的性别偏差。在图中”grandmother”更加靠近中和之后的”babysister”,这加重了偏差,为了修正偏差,把”grandmother”和”grandfather”下移到对称的位置
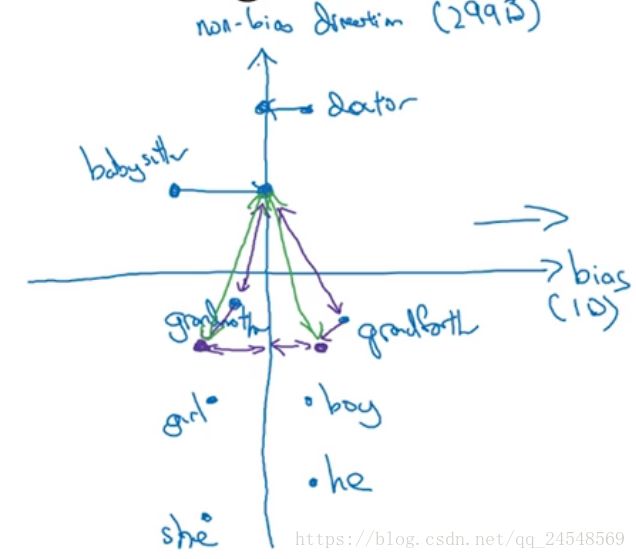
现在”grandmother”和”grandfather”离”babysister”的距离相等,保留了”grandmother”和”grandfather”的性别偏差。
另外一张图表现更清晰
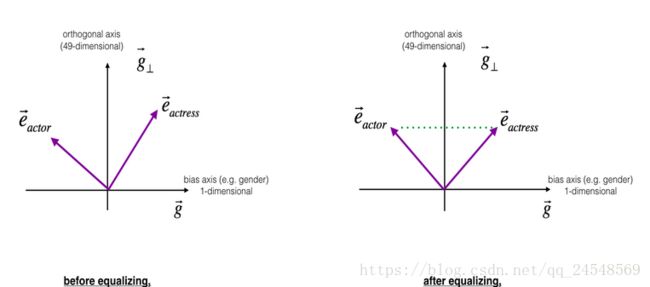
计算公式是
