笔记——搭建 LeNet(tensorflow)
本周搭建了 LeNet。
参考:《TensorFlow 实战 Google 深度学习框架》(郑泽宇)
LeNet paper
LeNet 模型如下
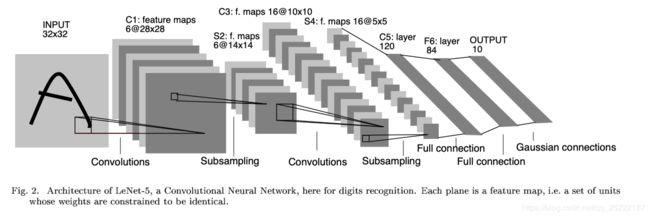
按照以下的LeNet 架构:


神经网络结构的代码 LeNet_forward.py,主要是完成前向通道的数值计算。
import tensorflow as tf
# layer size
CONV1_SIZE = 5
CONV1_DEEP =6
POOL1_SIZE = 2
POOL1_STRIDE = 2
CONV2_SIZE = 5
CONV2_DEEP =16
POOL2_SIZE = 2
POOL2_STRIDE = 2
FC1_SIZE = 120
FC2_SIZE = 84
# image input
NUM_CHANNAL = 1 #图片是32*32*1
IMAGE_SIZE = 28
INPUT_NODE = 784
NUM_LABEL = 10 #也是以后一层全连接层的输出节点数
BATCH_SIZE = 50
# tensor 的均值和方差可视化
def variable_summaries(name, var):
# 计算变量 var 的平均值、标准差。
with tf.name_scope(name):
tf.summary.histogram(name, var) # 计算 var 张量中元素的取值分布
mean = tf.reduce_mean(var)
tf.summary.scalar(name + "/mean", mean)
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
tf.summary.scalar(name + "/stddev", stddev)
# 前向通道
def LeNet_forward(INPUT_TENSOR):
with tf.variable_scope("layer1_CONV1"):
CONV1_Weights = tf.get_variable("Weight",[CONV1_SIZE, CONV1_SIZE, NUM_CHANNAL, CONV1_DEEP],
initializer = tf.truncated_normal_initializer(stddev=0.1))
variable_summaries("Weight", CONV1_Weights)
CONV1_bias = tf.get_variable("bias", [CONV1_DEEP], initializer = tf.constant_initializer(0.1))
variable_summaries("bias", CONV1_bias)
CONV1 = tf.nn.conv2d(INPUT_TENSOR, CONV1_Weights,strides=[1,1,1,1], padding='VALID')
with tf.name_scope("Weight_plus_bias"):
pre_activate = tf.nn.bias_add(CONV1, CONV1_bias)
tf.summary.histogram("pre_activate",pre_activate)
RELU1 = tf.nn.relu(pre_activate)
tf.summary.histogram("relu_activate",RELU1)
print(RELU1)
with tf.name_scope("layer2_POOL1"):
POOL1 = tf.nn.max_pool(RELU1, ksize=[1,2,2,1],strides=[1,2,2,1],padding='VALID')
tf.summary.histogram("relu_activate",POOL1)
print(POOL1)
with tf.variable_scope("layer3_CONV2"):
CONV2_Weights = tf.get_variable("Weight",[CONV2_SIZE, CONV2_SIZE, CONV1_DEEP, CONV2_DEEP],
initializer = tf.truncated_normal_initializer(stddev=0.1))
variable_summaries("Weight", CONV2_Weights)
CONV2_bias = tf.get_variable("bias", [CONV2_DEEP], initializer = tf.constant_initializer(0.1))
variable_summaries("bias", CONV2_bias)
CONV2 = tf.nn.conv2d(POOL1, CONV2_Weights,strides=[1,1,1,1], padding='VALID')
with tf.name_scope("Weight_plus_bias"):
pre_activate = tf.nn.bias_add(CONV2, CONV2_bias)
tf.summary.histogram("pre_activate",pre_activate)
RELU2 = tf.nn.relu(pre_activate)
tf.summary.histogram("relu_activate",RELU2)
print(RELU2)
with tf.name_scope("layer4_POOL2"):
POOL2 = tf.nn.max_pool(RELU2, ksize=[1,2,2,1],strides=[1,2,2,1],padding='VALID')
tf.summary.histogram("relu_activate",POOL2)
FLATTED1 = tf.contrib.layers.flatten(POOL2)
FLATTED1_NODES = FLATTED1.get_shape().as_list()[1]
tf.summary.histogram("FLATTED",FLATTED1)
print(FLATTED1)
with tf.variable_scope("layer5_FC1"):
FC1_Weights = tf.get_variable("Weight", [FLATTED1_NODES, FC1_SIZE],initializer = tf.truncated_normal_initializer(stddev=0.1))
variable_summaries("Weight", FC1_Weights)
FC1_bias = tf.get_variable("bias", [FC1_SIZE], initializer = tf.constant_initializer(0.1))
variable_summaries("bias", FC1_bias)
with tf.name_scope("Weight_plus_bias"):
pre_activate = tf.matmul(FLATTED1, FC1_Weights)+FC1_bias
tf.summary.histogram("pre_activate",pre_activate)
FC1 = tf.nn.relu(pre_activate)
tf.summary.histogram("relu_activate",FC1)
with tf.variable_scope("layer6_FC2"):
FC2_Weights = tf.get_variable("Weight", [FC1_SIZE, FC2_SIZE],initializer = tf.truncated_normal_initializer(stddev=0.1))
variable_summaries("Weight", FC2_Weights)
FC2_bias = tf.get_variable("bias", [FC2_SIZE], initializer = tf.constant_initializer(0.1))
variable_summaries("bias", FC1_bias)
with tf.name_scope("Weight_plus_bias"):
pre_activate = tf.matmul(FC1, FC2_Weights)+FC2_bias
tf.summary.histogram("pre_activate",pre_activate)
FC2 = tf.nn.relu(pre_activate)
tf.summary.histogram("relu_activate",FC2)
with tf.variable_scope("layer7_FC3"):
FC3_Weights = tf.get_variable("Weight", [FC2_SIZE, NUM_LABEL],initializer = tf.truncated_normal_initializer(stddev=0.1))
variable_summaries("Weight", FC3_Weights)
FC3_bias = tf.get_variable("bias", [NUM_LABEL], initializer = tf.constant_initializer(0.1))
variable_summaries("bias", FC3_bias)
with tf.name_scope("Weight_plus_bias"):
logits = tf.matmul(FC2, FC3_Weights)+FC3_bias
tf.summary.histogram("logits",logits)
return logits
总共搭建了七层网络,最后一层是输出层。
训练代码
def train(mnist):
with tf.name_scope("input"):
x = tf.placeholder(tf.float32, [BATCH_SIZE, LeNet_forward.IMAGE_SIZE, LeNet_forward.IMAGE_SIZE, LeNet_forward.NUM_CHANNAL],
name = "input-data")
y = tf.placeholder(tf.float32,[BATCH_SIZE, LeNet_forward.NUM_LABEL], name = "label")
y_pred = LeNet_forward.LeNet_forward(x)
with tf.name_scope("accuracy"):
correct_prediction = tf.cast(tf.equal(tf.argmax(y_pred,1), tf.argmax(y,1)), tf.float32)
accuracy = tf.reduce_mean(correct_prediction)
tf.summary.scalar("accuracy",accuracy)
with tf.name_scope("loss"):
cross_entropy = tf.nn.softmax_cross_entropy_with_logits_v2(labels = y, logits = y_pred)
cross_entropy_mean = tf.reduce_mean(cross_entropy)
tf.summary.scalar("cross_entropy_mean",cross_entropy_mean)
loss = cross_entropy_mean
tf.summary.scalar("loss",loss)
print(cross_entropy)
with tf.name_scope("train_step"):
LEARNING_RATE = 0.01
train_step = tf.train.AdamOptimizer(LEARNING_RATE).minimize(cross_entropy)
merged = tf.summary.merge_all()
saver = tf.train.Saver(max_to_keep = 3)
global_step = tf.Variable(0,trainable = False)
with tf.Session() as sess:
writer = tf.summary.FileWriter(EVENT_SAVE_PATH, sess.graph)
init_op = tf.global_variables_initializer()
sess.run(init_op)# 初始化
TRAIN_STEPS = 10000
for i in range(TRAIN_STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
xs_reshaped = np.reshape(xs, (BATCH_SIZE, LeNet_forward.IMAGE_SIZE, LeNet_forward.IMAGE_SIZE, LeNet_forward.NUM_CHANNAL))
summary, _, cross_entropy_value, loss_value, accuracy_value = sess.run([merged, train_step, cross_entropy, loss, accuracy],
feed_dict={x:xs_reshaped,y:ys})
writer.add_summary(summary,i)
if (i+1) % 1000 == 0:
saver.save(sess, MODEL_SAVE_PATH)
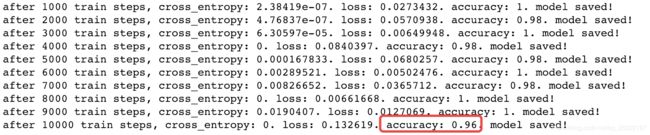
print("after %d train steps, cross_entropy: %g. loss: %g. accuracy: %g." \
% (i+1, cross_entropy_value[-1], loss_value, accuracy_value), "model saved!")
writer.close()主程序
def main(argv=None):
mnist = input_data.read_data_sets("../../../datasets/MNIST_data", one_hot=True)
train(mnist)
if __name__ == '__main__':
tf.app.run()这里仅进行了交叉熵+Adam做训练,效果还不错,后续将继续做优化。
tensorboard 可视化如下:
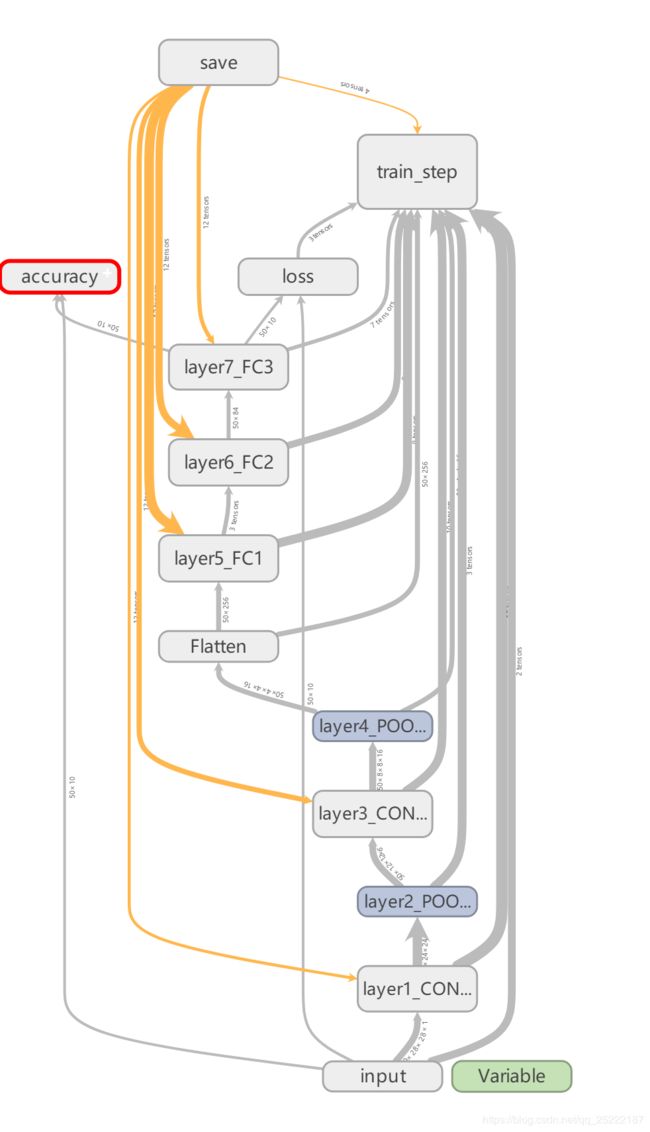
可以通过 GRAPHS看到,通过 tensorboard 查看构建的神经网络非常直观。
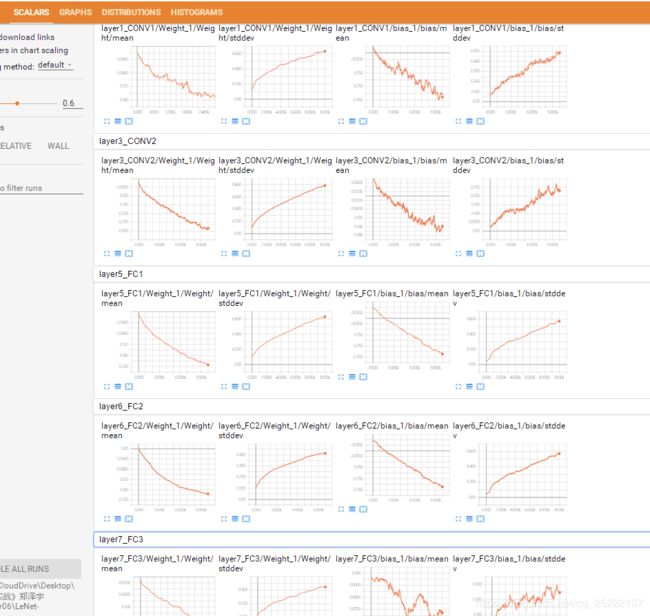
通过 SCALAS 可以看到某个变量的变化,这里观察的是 weight 和bias 的 mean 和stddev。可以观察到有参数的层(卷积层、全连接层)的参数 weight、bias 的均值mean都呈下降趋势, 标准差 stddev 都呈上升趋势。这是比较直觉的,因为随着训练的迭代次数,weight 、bias 都应该尽量不一样,标准差自然上升。
通过 DISTRIBUTIONS 可以看到具体 tensor 的分布。下图layer1的 wx+b 本身的分布主要为负数部分,在 经过relu 激活函数后,仅保留了整数部分。
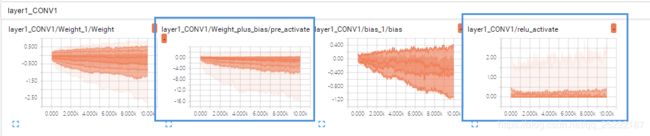
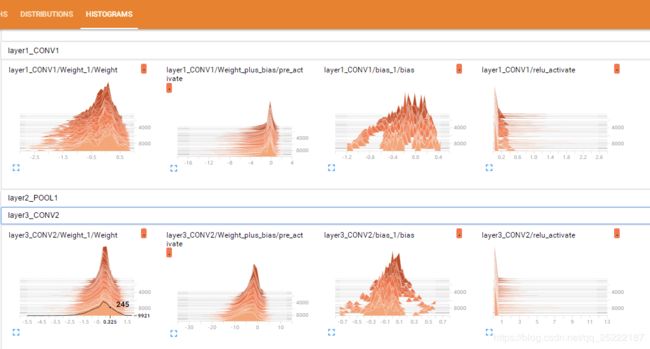
在 HISTOGRAMS 中可以看到随着迭代次数的增加,tensor 的分布变化。下图可以看到 layer1的 weight 的分布在负轴上越来越远,但整体上在0附近的越来越少。bias 的分布越来越分散,主要在[-1.2,0.4]范围内。relu激活函数对 wx+b 的截断在这里更加直观。
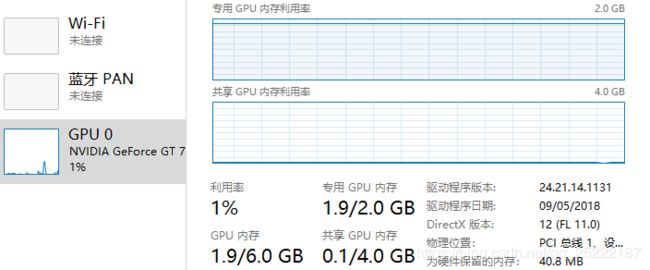
对于2G 的 GPU (本机 GetForce GT 730)来说,还是可以满足的,BATCH_SIZE = 50,训练10000次的情况下。大概半分钟的样子。
Note:每次train 时都会生成新的 event s 文件,而 tensorboard 展示的是所有的保存过的信息,下图可以看到,当给 layer 改名字后(由 layer1_CONV1/Weight_1/Weight 改为 layer1_CONV1/name/Weight )重新 train 时,虽然会生成新的 event s文件,但原先layer1_CONV1/Weight_1/Weight 对应的layer 的信息还是显示的,所有我自己的做法是每次只保留最新的 events。


同时可以观察到,tensorboard 显示的信息会随着 tensorflow 的训练而实时更新

下周继续更新:继续做优化。