ELK(Elasticsearch+Logstash+Kinaba)日志分析系统
1,简介
ELK由Elasticsearch、Logstash和Kibana三部分组件组成;
Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash是一个完全开源的工具,它可以对你的日志进行收集、分析,并将其存储供以后使用
kibana 是一个开源和免费的工具,它可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。
2,常用组件:
1),Elasticsearch是实时全文搜索和分析引擎,提供搜集、分析、存储数据三大功能;是一套REST和JAVA API开放且提供高效搜索功能,可扩展的分布式系统。它构建于Apache Lucene搜索引擎库之上。
2),Logstash用来采集(它支持几乎任何类型的日志,包括系统日志、错误日志和自定义应用程序日志)日志,把日志解析为json格式交给ElasticSearch
3),Kibana是一个基于Web图形界面,用于搜索、分析和可视化显示存储在 Elasticsearch指标中的日志数据。它利用Elasticsearch的REST接口来检索数据,不仅允许用户创建他们自己的数据的定制仪表板视图,还允许他们以特殊的方式查询和过滤数据
Filebeat、topbeat、packetbeat用于收集各应用、服务器等日志信息:
4),Filebeat:自定义需要收集的日志信息;
5),Topbeat:主要收集主机CPU、Mem、Disk、Process、Load等信息, 周期性的发送指标到elasticsearch。可以通过kibana创建自定义仪表盘如系统负载、服务器概述、内存或cpu使用情况、top进程、每个进程占用cpu或内存比例、磁盘使用情况等等。
6),Packetbeat:是分布式的,实时的嗅探每个事务的请求与响应,并将相关数据插入到elasticsearch中。packetbeat被动的嗅探网络流量,因此不会干扰应用程序。
ELK构架图:
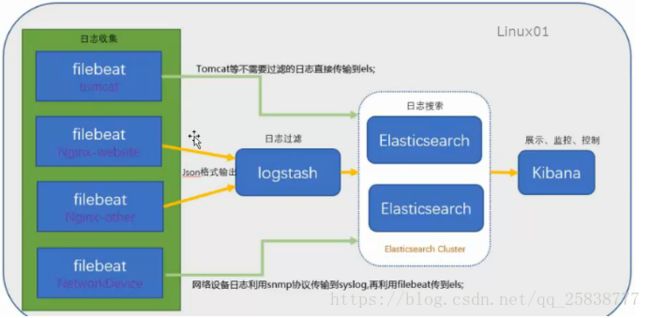
3、ELK工作流程
在需要收集日志的所有服务上部署logstash,作为logstash agent(logstash shipper)用于监控并过滤收集日志,将过滤后的内容发送到Redis,
然后logstash indexer将日志收集在一起交给全文搜索服务ElasticSearch,可以用ElasticSearch进行自定义搜索通过Kibana 来结合自定义搜索进行页面展示。

logstach 安装及简单使用
https://www.elastic.co/guide/en/logstash/current/index.html
logstash是用JRuby语言开发的,所以要安装JDK
tar -zxvf logstash-2.X.X.tar.gz -C /bigdata/
bin/logstash -e 'input { stdin {} } output { stdout{} }'
bin/logstash -e 'input { stdin {} } output { stdout{codec => rubydebug} }'
bin/logstash -e 'input { stdin {} } output { elasticsearch {hosts => ["172.16.0.14:9200"]} stdout{} }'
bin/logstash -e 'input { stdin {} } output { elasticsearch {hosts => ["172.16.0.15:9200", "172.16.0.16:9200"]} stdout{} }'
bin/logstash -e 'input { stdin {} } output { kafka { topic_id => "itcast" bootstrap_servers => "172.16.0.11:9092,172.16.0.12:9092,172.16.0.13:9092"} stdout{codec => rubydebug} }'--------------------------------------------------------------------
以配置的形式
vi logstash.conf
input {
file {
type => "gamelog"
path => "/log/*/*.log"
discover_interval => 10
start_position => "beginning"
}
}
output {
elasticsearch {
index => "gamelog-%{+YYYY.MM.dd}"
hosts => ["172.16.0.14:9200", "172.16.0.15:9200", "172.16.0.16:9200"]
}
}
#启动logstack
bin/logstash -f logstash.conf
bin/logstash -e '
input { stdin {} }
filter {
grok {
match => { "message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}" }
}
}
output { stdout{codec => rubydebug}
}'es安装及简单使用笔记:
###【在多台机器上执行下面的命令】###
#es启动时需要使用非root用户,所有创建一个bigdata用户:(如果使用root用户启动的话会出现一些问题)
useradd bigdata
#为hadoop用户添加密码:
echo 123456 | passwd --stdin bigdata
#将bigdata添加到sudoers
echo "bigdata ALL = (root) NOPASSWD:ALL" | tee /etc/sudoers.d/bigdata
chmod 0440 /etc/sudoers.d/bigdata
#解决sudo: sorry, you must have a tty to run sudo问题,在/etc/sudoer注释掉 Default requiretty 一行
sudo sed -i 's/Defaults requiretty/Defaults:bigdata !requiretty/' /etc/sudoers
#创建一个bigdata目录
mkdir /{bigdata,data}
#给相应的目录添加权限
chown -R bigdata:bigdata /{bigdata,data}
-------------------------------------------------------------------------------------------------
We recommend installing the Java 8 update 20 or later, or Java 7 update 55 or later.
Previous versions of Java 7 are known to have bugs that can cause index corruption and data loss.
Elasticsearch will refuse to start if a known-bad version of Java is used.
###【切换到bigdata用户安装】###
1.安装jdk(jdk要求1.8.20或1.7.55以上)
2.上传es安装包
3.解压es
tar -zxvf elasticsearch-2.3.1.tar.gz -C /bigdata/
4.修改配置
vi /bigdata/elasticsearch-2.3.1/config/elasticsearch.yml
#集群名称,通过组播的方式通信,通过名称判断属于哪个集群
cluster.name: bigdata
#节点名称,要唯一
node.name: es-1
#数据存放位置
path.data: /data/es/data
#日志存放位置
path.logs: /data/es/logs
#es绑定的ip地址
network.host: 172.16.0.14
#初始化时可进行选举的节点
discovery.zen.ping.unicast.hosts: ["node-4.itcast.cn", "node-5.itcast.cn", "node-6.itcast.cn"]
5.使用scp拷贝到其他节点
scp -r elasticsearch-2.3.1/ node-5.itcast.cn:$PWD
scp -r elasticsearch-2.3.1/ node-6.itcast.cn:$PWD
6.在其他节点上修改es配置,需要修改的有node.name和network.host
7.启动es(/bigdata/elasticsearch-2.3.1/bin/elasticsearch -h查看帮助文档)
/bigdata/elasticsearch-2.3.1/bin/elasticsearch -d
8.用浏览器访问es所在机器的9200端口
http://172.16.0.14:9200/
{
"name" : "es-1",
"cluster_name" : "bigdata",
"version" : {
"number" : "2.3.1",
"build_hash" : "bd980929010aef404e7cb0843e61d0665269fc39",
"build_timestamp" : "2016-04-04T12:25:05Z",
"build_snapshot" : false,
"lucene_version" : "5.5.0"
},
"tagline" : "You Know, for Search"
}
kill `ps -ef | grep Elasticsearch | grep -v grep | awk '{print $2}'`
-----------------------------------------------------------------------------------------------------------------
#es安装插件下载es插件
/bigdata/elasticsearch-2.3.1/bin/plugin install mobz/elasticsearch-head
[hadoop@master es]$ bin/plugin install mobz/elasticsearch-head
-> Installing mobz/elasticsearch-head...
Trying https://github.com/mobz/elasticsearch-head/archive/master.zip ...
Downloading ....................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................DONE
Verifying https://github.com/mobz/elasticsearch-head/archive/master.zip checksums if available ...
NOTE: Unable to verify checksum for downloaded plugin (unable to find .sha1 or .md5 file to verify)
Installed head into /export/servers/es/plugins/head
#本地方式安装head插件
./plugin install file:///home/bigdata/elasticsearch-head-master.zip
#访问head管理页面
http://172.16.0.14:9200/_plugin/head
RESTful接口URL的格式:
http://localhost:9200///[]
其中index、type是必须提供的。
id是可选的,不提供es会自动生成。
index、type将信息进行分层,利于管理。
index可以理解为数据库;type理解为数据表;id相当于数据库表中记录的主键,是唯一的。
#向store索引中添加一些书籍
curl -XPUT 'http://172.16.0.14:9200/store/books/1' -d '{
"title": "Elasticsearch: The Definitive Guide",
"name" : {
"first" : "Zachary",
"last" : "Tong"
},
"publish_date":"2015-02-06",
"price":"49.99"
}'
#通过浏览器查询
http://172.16.0.14:9200/store/books/1
#在linux中通过curl的方式查询
curl -XGET 'http://172.16.0.14:9200/store/books/1'
#在添加一个书的信息
curl -XPUT 'http://172.16.0.14:9200/store/books/2' -d '{
"title": "Elasticsearch Blueprints",
"name" : {
"first" : "Vineeth",
"last" : "Mohan"
},
"publish_date":"2015-06-06",
"price":"35.99"
}'
# 通过ID获得文档信息
curl -XGET 'http://172.16.0.14:9200/bookstore/books/1'
#在浏览器中查看
http://172.16.0.14:9200/bookstore/books/1
# 通过_source获取指定的字段
curl -XGET 'http://172.16.0.14:9200/store/books/1?_source=title'
curl -XGET 'http://172.16.0.14:9200/store/books/1?_source=title,price'
curl -XGET 'http://172.16.0.14:9200/store/books/1?_source'
#可以通过覆盖的方式更新
curl -XPUT 'http://172.16.0.14:9200/store/books/1' -d '{
"title": "Elasticsearch: The Definitive Guide",
"name" : {
"first" : "Zachary",
"last" : "Tong"
},
"publish_date":"2016-02-06",
"price":"99.99"
}'
# 或者通过 _update API的方式单独更新你想要更新的
curl -XPOST 'http://172.16.0.14:9200/store/books/1/_update' -d '{
"doc": {
"price" : 88.88
}
}'
curl -XGET 'http://172.16.0.14:9200/store/books/1'
#删除一个文档
curl -XDELETE 'http://172.16.0.14:9200/store/books/1'
# 最简单filter查询
# SELECT * FROM books WHERE price = 35.99
# filtered 查询价格是35.99的
curl -XGET 'http://172.16.0.14:9200/store/books/_search' -d '{
"query" : {
"filtered" : {
"query" : {
"match_all" : {}
},
"filter" : {
"term" : {
"price" : 35.99
}
}
}
}
}'
#指定多个值
curl -XGET 'http://172.16.0.14:9200/store/books/_search' -d '{
"query" : {
"filtered" : {
"filter" : {
"terms" : {
"price" : [35.99, 99.99]
}
}
}
}
}'
# SELECT * FROM books WHERE publish_date = "2015-02-06"
curl -XGET 'http://172.16.0.14:9200/bookstore/books/_search' -d '{
"query" : {
"filtered" : {
"filter" : {
"term" : {
"publish_date" : "2015-02-06"
}
}
}
}
}'
# bool过滤查询,可以做组合过滤查询
# SELECT * FROM books WHERE (price = 35.99 OR price = 99.99) AND (publish_date != "2016-02-06")
# 类似的,Elasticsearch也有 and, or, not这样的组合条件的查询方式
# 格式如下:
# {
# "bool" : {
# "must" : [],
# "should" : [],
# "must_not" : [],
# }
# }
#
# must: 条件必须满足,相当于 and
# should: 条件可以满足也可以不满足,相当于 or
# must_not: 条件不需要满足,相当于 not
curl -XGET 'http://172.16.0.14:9200/bookstore/books/_search' -d '{
"query" : {
"filtered" : {
"filter" : {
"bool" : {
"should" : [
{ "term" : {"price" : 35.99}},
{ "term" : {"price" : 99.99}}
],
"must_not" : {
"term" : {"publish_date" : "2016-02-06"}
}
}
}
}
}
}'
# 嵌套查询
# SELECT * FROM books WHERE price = 35.99 OR ( publish_date = "2016-02-06" AND price = 99.99 )
curl -XGET 'http://172.16.0.14:9200/bookstore/books/_search' -d '{
"query" : {
"filtered" : {
"filter" : {
"bool" : {
"should" : [
{ "term" : {"price" : 35.99}},
{ "bool" : {
"must" : [
{"term" : {"publish_date" : "2016-02-06"}},
{"term" : {"price" : 99.99}}
]
}}
]
}
}
}
}
}'
# range范围过滤
# SELECT * FROM books WHERE price >= 20 AND price < 100
# gt : > 大于
# lt : < 小于
# gte : >= 大于等于
# lte : <= 小于等于
curl -XGET 'http://172.16.0.14:9200/store/books/_search' -d '{
"query" : {
"filtered" : {
"filter" : {
"range" : {
"price" : {
"gt" : 20.0,
"lt" : 100
}
}
}
}
}
}'
# 另外一种 and, or, not查询
# 没有bool, 直接使用and , or , not
# 注意: 不带bool的这种查询不能利用缓存
# 查询价格既是35.99,publish_date又为"2015-02-06"的结果
curl -XGET 'http://172.16.0.14:9200/bookstore/books/_search' -d '{
"query": {
"filtered": {
"filter": {
"and": [
{
"term": {
"price":59.99
}
},
{
"term": {
"publish_date":"2015-02-06"
}
}
]
},
"query": {
"match_all": {}
}
}
}
}'
http://172.16.0.14:9200/bookstore/books/_search
#es安装插件下载es插件
/bigdata/elasticsearch-2.3.1/bin/plugin install elasticsearch/marvel/latest
#访问head管理页面
http://172.16.0.14:9200/_plugin/marvel