TensorFlow Mobilenet SSD模型压缩并移植安卓上以达到实时检测效果
之前使用TensorFlow object detect API实现了目标检测(14个手势的识别),使用的是轻量级模型Mobilenet-ssd,Mobilenet-ssd本身检测速率相较于其他模型会更快。使用模型配置文件未对参数修改时,训练后的模型通过TensorFlow lite移植安卓上检测发现,速率达到了200-300ms(用的红米5A手机性能较差),模型大小5M(有点忘了)。200-300ms一帧的检测速率在安卓机上还是能感觉到明显的卡顿,因而想对模型进行优化,目标将模型大小压缩到1M以下,一帧检测速率优化至20ms左右。在模型优化的过程中尝试了很多方法,如下:
- 查了很多方法,有对模型进行剪枝的,大致思路是将模型中不重要的权值置零以减少非零权值的数量,官方的实现方法说明是在tensorflow/contrib/model_pruning/目录下。但实际根据此方法进行模型剪枝后通过TensorFlow lite转换后的tflite模型并未有明显的提升,似乎没有提升(可能是姿势不对,望大神能够指点)。
- 决定使用粗暴的方法直接修改模型结构。因而我查看了源码找到了mobilenet-ssd模型设置的文件,我将mobilenet中第三层直接删除(因为mobilenet-ssd提取特征的层级运算耗时会大些,想删除一层看看会不会提升效率),模型训练完成后移植安卓中发现目标检测会不准,速率也没明显提升。此时有点失落。
- 查看源码时无意间看到mobilenet_v1.py时,
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet_v1.py
发现结果如下:
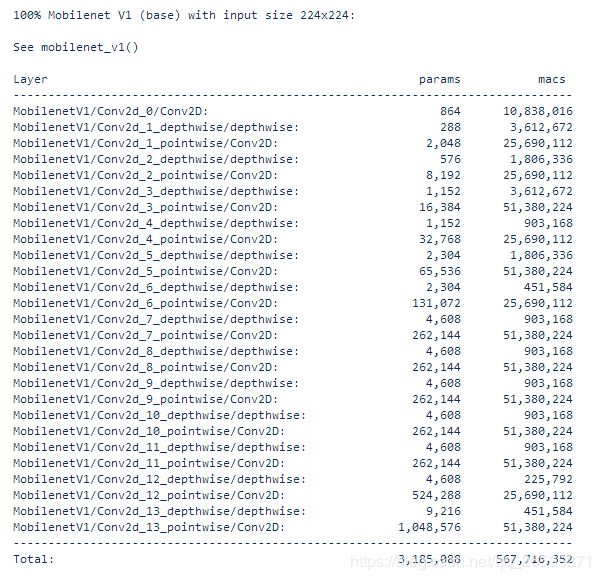
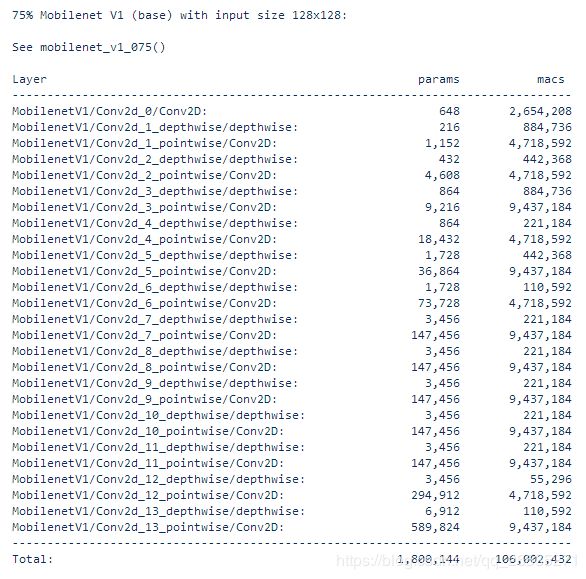
100% Mobilenet V1 (base) with input size 224x224:mobilenet_v1模型未对模型压缩,输入大小为224x224此时模型参数总个数为3,185,088。
75% Mobilenet V1 (base) with input size 128x128:mobilenet_v1模型压缩至原来的模型75%,输入大小不变,此时模型参数总个数为1,800,144。
从模型参数总个数发现75% Mobilenet V1 (base)减少了很多,进而速率也得到了提升。在该源码文件中发现下图代码,进而可以确定设置模型参数压缩的值是depth_multiplier这个参数。

此压缩方法原理即通过设置depth_multiplier,模型每层深度depth与depth_multiplier相乘进而减少原有的深度(个人理解,如果有误望指出)。Mobilenet_v1模型结构如下:

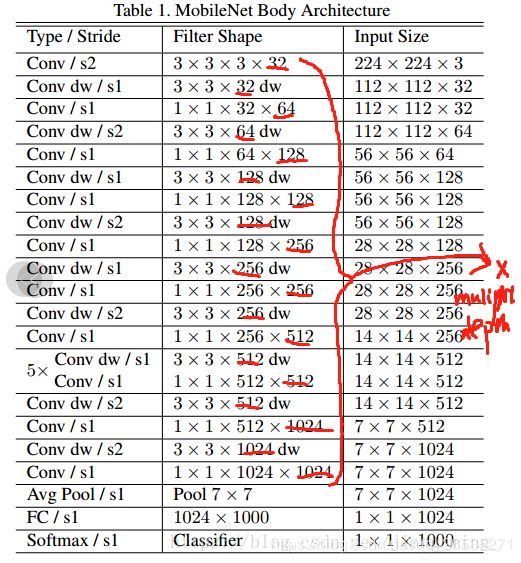
下面开始介绍如何修改配置文件进行模型压缩。
此处省略TensorFlow下载步骤,直接从配置文件参数修改开始。
1、首先拷贝配置文件
ssd_mobilenet_v1_0.75_depth_300x300_coco14_sync.config至自己的目录中;配置文件位置:
https://github.com/tensorflow/models/tree/master/research/object_detection/samples/configs(根据下载的TensorFlow工程位置查找)
打开配置文件,找到depth_multiplier修改参数值(这里我将模型压缩至30%)

配置文件中可修改输入模型训练的图像大小如下(降低图像输入的模型中的分辨率同样可提高模型推理效率):

2、下载预训练模型(若不使用预训练模型可将该两行注释
#fine_tune_checkpoint: "PATH_TO_BE_CONFIGURED/model.ckpt"
#from_detection_checkpoint: true)
网址:
https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md
可以看到

可以下载第一个红框的模型,第二个红框用于需要对模型进行量化处理的(后面再详细介绍)。
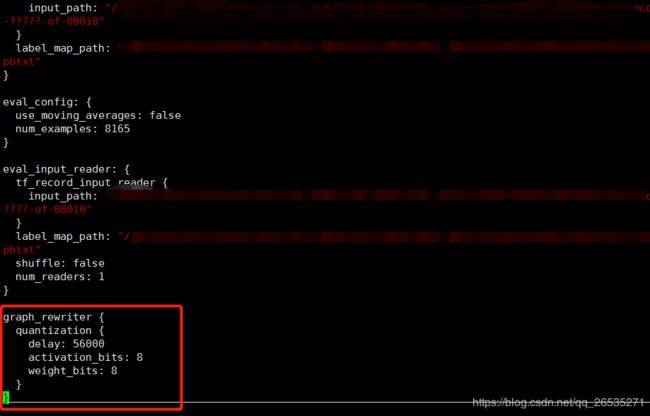
若需要训练后模型可量化处理,在配置文件最后加上红框部分代码如下图。
3、第三步假设配置文件参数都设置完(模型地址、训练图像地址、训练标签,测试图像地址、测试标签),该配置的环境变量都配置完成(export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim)不再描述。开始运行程序进行训练。
python object_detection/model_main.py \
--logtostderr \
--pipeline_config_path=xxxxxxx/ssd_mobilenet_v1_030_14_1119.config \
--model_dir=xxxxxxxx \
--num_train_steps=50000 \
--num_eval_steps=20004、模型训练完则开始使用TensorFlow lite将模型进行转换成安卓可用的模型。具体步骤可见我上一个博客
https://blog.csdn.net/qq_26535271/article/details/83031412
此时以上步骤是使用的非量化模型,将depth_multiplier设置成0.25时,最终模型通过TensorFlow lite转成tflite文件,文件大小为1.5M,在安卓上速率达到了25-40ms(红米5A手机跳动较大只能粗略一个范围),这样的速率还是达到了实时。
下面介绍使用量化模型,量化模型的大小仅为非量化模型的1/4,速率也能得到较大提升并且不影响精度(官方说不影响精度,但在我手机上测试时没有非量化模型精准,不懂为何)
1、拷贝配置文件并修改其内容,配置文件使用的地址如上,可使用文件:
ssd_mobilenet_v1_0.75_depth_quantized_300x300_pets_sync.config
2、下载量化模型,见上面步骤2,可下载第二个红框的模型。
3、步骤3如上步骤3;
4、在第四步时见上面的第四步,需要将命令中inference_type设置为QUANTIZED_UINT8;
如下:
bazel run --config=opt tensorflow/contrib/lite/toco:toco -- \
--input_file=$OUTPUT_DIR/tflite_graph.pb \
--output_file=$OUTPUT_DIR/detect.tflite \
--input_shapes=1,192,192,3 \ (根据实际训练的模型大小修改)
--input_arrays=normalized_input_image_tensor \
--output_arrays='TFLite_Detection_PostProcess','TFLite_Detection_PostProcess:1','TFLite_Detection_PostProcess:2','TFLite_Detection_PostProcess:3' \
--inference_type=QUANTIZED_UINT8 \
--mean_values=128 \
--std_values=128 \
--change_concat_input_ranges=false \
--allow_custom_ops以上步骤完成则从完成了通过TensorFlow API进行目标检测并通过修改配置文件以达到模型压缩的目的。上面步骤中省略了一些使用TensorFlow API进行目标检测的步骤方法,网上资料较多可自行查找,这里重点介绍如何进行模型压缩。下面将列举一些模型压缩后在安卓上测试的效率(具体值我没记录,只记得大概,下次认真点记录)。
| 手机型号 |
是否量化 |
Depth_multiplier |
Size(模型大小) |
速率(一帧/ms) |
| 红米5A |
否 |
1.0 |
5M |
200-300ms |
| 红米5A |
否 |
0.25 |
1.5M |
25-40ms |
| 红米5A |
是 |
0.25 |
433K |
15-30ms |
| 华为P9 |
是 |
0.25 |
433K |
8-20ms |
| 华为P9 |
是 |
0.35 |
700+K |
12-25ms |