FCHD: A fast and accurate head detector,头部检测的理解与实现(tensorflow)
论文地址:
https://arxiv.org/abs/1809.08766v1
论文摘要:
Abstract—In this paper, we propose FCHD-Fully Convolutional Head Detector, which is an end-to-end trainable head detection model, which runs at 5 fps and with 0.70 average precision (AP), on a very modest GPU. Recent head detection techniques have avoided using anchors as a starting point for detection especially in the cases where the detection has to happen in the wild. The reason is poor performance of anchorbased techniques under scenarios where the object size is small. We argue that a good AP can be obtained with carefully designed anchors, where the anchor design choices are made based on the receptive field size of the hidden layers. Our contribution is two folds. 1) A simple fully convolutional anchor based model which is end-to-end trainable and has a very low inference time. 2) Carefully chosen anchor sizes which play a key role in getting good average precision. Our model achieves comparable results than many other baselines on challenging head detection dataset like BRAINWASH. Along with accuracy, our model has least runtime among all the baselines along with modest hardware requirements which makes it suitable for edge deployments in surveillance applications. The code is made open-source at https://github.com/aditya-vora/FCHDFully-Convolutional-Head-Detector. Index Terms—Head Detection, Crowd Counting, Object Detection, Faster-RCNN.
论文说明和理解
1、引言
论文引言部分说明了头部检测在计算机视觉领域是一个重要的问题。监控视频中的人群计数可被视为头部检测的最重要应用之一。然后论文说明了通常的做法是训练一个回归的模型,基于输入图片去预测密度图,然而,这些基于密度图的技术具有若干缺点:1)通过像素方式确定整个密度图,以确定最终的数量。 在执行此操作时,它不会考虑密度映射中计数贡献来自何处的位置。 因此,预测中出现的误报将导致最终的人群数量,从而导致错误的结果。 2)密度图的精度对输入图像分辨率敏感,当密度图分辨率较小时获得更好的结果 。
另一种方法可以解决人群计数检测方法的问题,我们可以将输入图像直接输入到预先训练的模型,如Faster-RCNN [5],并计算“人类”中的边界框数量,以获得最终的人群数量。然后作者又指出在高度遮挡的场景Faster-RCNN的效果是一个很显著的问题,因为在一个拥挤的场景,通常就会出现遮挡的现象。而且,像Faster-RCNN这样的模型通常有会有很高的计算量和内存占用。所以作者指出,部署这样的一种模型是不可行的。
然后作者引出本文,我们尝试通过头部检测方法结合人群计数方法的优点。论文提出的使用检测的方法而不是回归的方法,,可以解决前面两种方法的问题,即在遮挡场景下较少的误报和更好的表现(因为头部是场景中最可见的部分)。作者还提到,模型中使用的是全卷积而不是全连接,这是因为完全连接的层理想地消耗大部分内存,以及[7]中观察到的推理时间。这使得模型可以在嵌入式硬件中运行。
本文提出了一种基于锚点的完全卷积和端头可训练的头部检测模型,模型是基于Faster-RCNN,但是又不像Faster-RCNN这个模型有两级流水线,论文的模型是一个可以直接执行头部检测的单级流水线。并且,Faster-RCNN是随机的锚尺度,本文是根据网络的有效接受场仔细选择锚点。
论文的主要工作:
1) 基于锚定,完全卷积,端到端的可训练头部检测模型,其中基于接收场尺寸的锚定尺度在获得显着性能提升方面起着至关重要的作用。
2)提出了一种头部检测模型,其具有良好的推理时间以及较低的存储器要求。
3)我们获得了与某些基线技术相当的结果,并且在BRAINWASH数据集等挑战性数据集上优于其他一些先前的头部检测方法[8]。
2、相关工作
作者在这一部分主要是介绍和说明了在拥挤场景的头部检测的发展。大概介绍了以下的这些方法:
1) 提出了一种基于回归的技术,其中从视频中的运动分割区域提取边缘和纹理等手工制作的特征。为了将提取的特征映射到实际的人群计数,训练线性回归模型。然而这样的方法对区域的分割高度敏感,使用回归模型学习的映射将随着不同的相机位置而变化。由于这个原因,这种技术无法推广到看不见的场景。
2)使用深度学习方法来解决这个问题,他们训练CNN以预测密度图以及人群数量。他们通过数据驱动的方法消除了先前人群计数技术所面临的泛化的弊端。然而,该方法需要透视图以便标准化图像中的头部的比例。由于在大多数实际情况下,透视图不易获得,这限制了其适用性。这个问题是用多列架构解决的[2]。
3)提出了一种头部检测技术,其中两个CNN模型用于执行头部检测,第一个模型用于直接从图像预测头部的尺度和位置。而第二个模型用于建模对象之间的成对关系。
2、方法
接着作者开始介绍本片论文使用的方法,包括模型结构、锚尺的设计、训练的方法。
2.1、模型结构
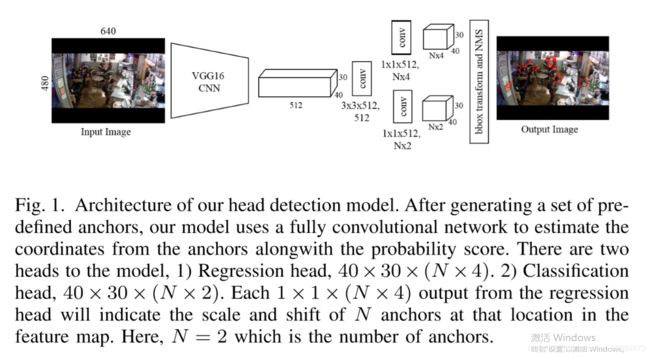
模型使用训练好的VGG16做为特征提取层,使用的是VGG16 conv5_3层的结果,输出的维度是(30,40,512),关于VGG 16可以下载使用Tensorflow实现的代码 链接:tensorflow-vgg。
然后是一层卷积核为(3, 3, 512,512)的卷积层,然后将输出的结果经过relu激活函数。
将卷积层得到的结果分为两步输入到卷积核为(1,1,512,n*4)和(1,1,512,n*2)的全卷积层,其中n为标记的人头数,这里(1,1,512,n*4)的全卷积层是回归头部,(1,1,512,n*2)的全卷积层是分类头部。
最后将得到的两步中的矩阵做检测框偏移(bbox transform)以及非极大值抑制(NMS),然后得到的是预测的头部框位置。
备注:这里的NMS就是要从多种尺度中找到一种最好的方式,文中使用的是 重叠率(重叠区域面积比例IOU)阈值 >= 0.7
将框的位置和原始图像进行合并就是最后的输出结果。
2.2 训练数据说明
输入图片数据为brainwash数据集:

标注数据为:brainwash_10_27_2014_images/00000000_640x480.png": (152.0, 115.0, 167.0, 135.0), (221.0, 127.0, 240.0, 152.0), (225.0, 147.0, 253.0, 176.0), (191.0, 155.0, 226.0, 201.0), (314.0, 97.0, 331.0, 114.0), (341.0, 96.0, 365.0, 116.0), (389.0, 101.0, 412.0, 122.0), (313.0, 156.0, 350.0, 195.0), (461.0, 136.0, 483.0, 159.0), (273.0, 93.0, 290.0, 112.0), (51.0, 212.0, 79.0, 243.0);
brainwash_10_27_2014_images/00000000_640x480.png 为对应一张图片
后面紧跟着11个单元的数据说明有11个人头
(152.0, 115.0, 167.0, 135.0) 这个是其中的一个人头数据,表示头部框的左上坐标和右下坐标,最后的结果是在图中这样的:
