Sqoop是什么
Sqoop是什么
更多干货
- 分布式实战(干货)
- spring cloud 实战(干货)
- mybatis 实战(干货)
- spring boot 实战(干货)
- React 入门实战(干货)
- 构建中小型互联网企业架构(干货)
- python 学习持续更新
- ElasticSearch 笔记
- kafka storm 实战 (干货)
概述
- Flume官网:http://flume.apache.org/
- Sqoop官网:http://sqoop.apache.org/
- Sqoop书籍:Apache Sqoop Cookbook
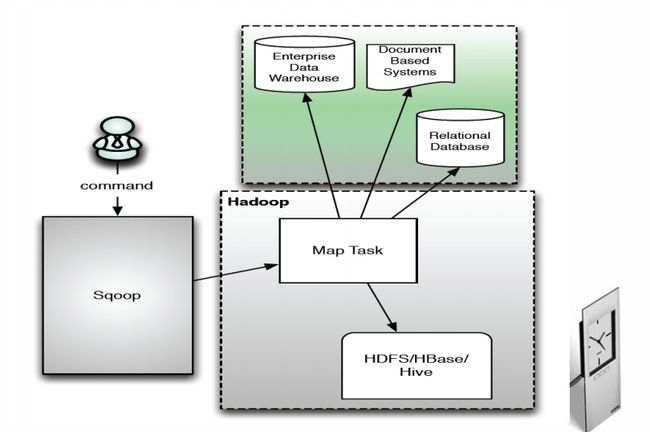
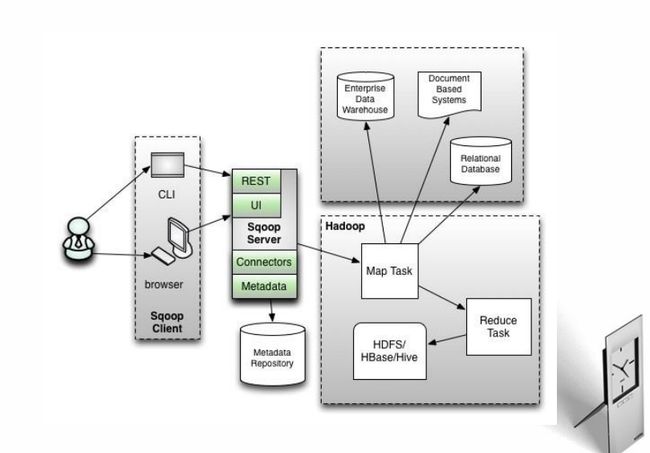
Sqoop是一个关系型数据库与Hadoop间的数据同步的工具
- 将数据同步问题转化为MR作业
- 实时性不够好
Sqoop:SQL-to-Hadoop 连接 传统关系型数据库 和 Hadoop 的桥梁 把关系型数据库的数据导入到 Hadoop 系统 ( 如 HDFSHBase 和 Hive) 中;
把数据从 Hadoop 系统里抽取并导出到关系型数据库里。利用MapReduce加快数据传输速度批处理方式进行数据传输
Sqoop优势
- 高效、可控地利用资源,任务并行度,超时时间等
- 数据类型映射与转换,可自动进行,用户也可自定义
- 支持多种数据库。MySQL、Oracle、PostgreSQL
Sqoop1架构
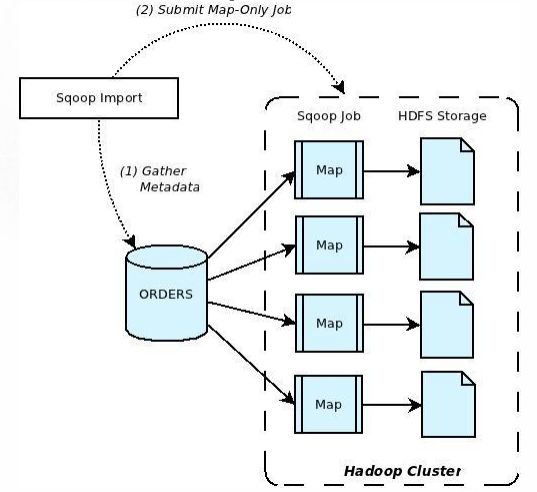
Sqoop import
将数据从关系型数据库导入Hadoop中
- 步骤1:Sqoop与数据库Server通信,获取数据库表的元数据信息;
- 步骤2:Sqoop启动一个MapOnly的MR作业,利用元数据信息并行将数据写入Hadoop。
Sqoop import使用
sqoop import \
--connect jdbc:mysql://mysql.example.com/sqoop \
--username sqoop \
--password sqoop \
--table cities
--connnect: 指定JDBC URL --username/password:mysql数据库的用户名 --table:要读取的数据库表
bin/hadoop fs -cat cities/part-m-*
1,USA,Palo Alto
2,Czech Republic,Brno
3,USA,Sunnyvale
Sqoop import示例
sqoop import
--connect jdbc:mysql://mysql.example.com/sqoop
--username sqoop
--password sqoop
--table cities
--target dir /etl/input/cities
sqoop import
--connect jdbc:mysql://mysql.example.com/sqoop
--username sqoop
--password sqoop
--table cities
--where "country = 'USA'"
sqoop import \
--connect jdbc:mysql://mysql.example.com/sqoop \
--username sqoop \
--password sqoop \
--table cities \
--as-sequencefile
sqoop import \
--connect jdbc:mysql://mysql.example.com/sqoop \
--username sqoop \
--password sqoop \
--table cities \
--num-mappers 10
Sqoop import—导入多个表
sqoop import \
--connect jdbc:mysql://mysql.example.com/sqoop \
--username sqoop \
--password sqoop \
--query 'SELECT normcities.id, \
countries.country, \
normcities.city \
FROM normcities \
JOIN countries USING(country_id) \
WHERE $CONDITIONS' \
--split-by id \
--target-dir cities
Sqoop import增量导入
sqoop import \
--connect jdbc:mysql://mysql.example.com/sqoop \
--username sqoop \
--password sqoop \
--table visits \
--incremental append \
--check-column id \
--last-value 1
sqoop import \
--connect jdbc:mysql://mysql.example.com/sqoop \
--username sqoop \
--password sqoop \
--table visits \
--incremental append \
--check-column id \
--last-value 1
适用于数据每次被追加到数据库中,而已有数据不变的情况;
仅导入id这一列值大于1的记录。
sqoop job \
--create visits \
--import \
--connect jdbc:mysql://mysql.example.com/sqoop \
--username sqoop \
--password sqoop \
--table visits \
--incremental append \
--check-column id \
--last-value 0
运行sqoop作业:sqoop job --exec visits
- 每次成功运行后,sqoop将最后一条记录的id值保存到metastore中,供下次使用。
sqoop import \
--connect jdbc:mysql://mysql.example.com/sqoop \
--username sqoop \
--password sqoop \
--table visits \
--incremental lastmodified \
--check-column last_update_date \
--last-value “2013-05-22 01:01:01”
- 数据库中有一列last_update_date,记录了上次修改时间;
- Sqoop仅将某时刻后的数据导入Hadoop。
- 将数据从Hadoop导入关系型数据库导中
Sqoop Export
将数据从Hadoop导入关系型数据库导中
步骤1:Sqoop与数据库Server通信,获取数据库表的元数据信息;
步骤2:并行导入数据:将Hadoop上文件划分成若干个split;每个split由一个Map Task进行数据导入。

sqoop export \
--connect jdbc:mysql://mysql.example.com/sqoop \
--username sqoop \
--password sqoop \
--table cities \
--export-dir cities
--connnect: 指定JDBC URL
--username/password:mysql数据库的用户名
--table:要导入的数据库表
export-dir:数据在HDFS上存放目录
保证原子性
sqoop export \
--connect jdbc:mysql://mysql.example.com/sqoop \
--username sqoop \
--password sqoop \
--table cities \
--staging-table staging_cities
更新已有数据
sqoop export \
--connect jdbc:mysql://mysql.example.com/sqoop \
--username sqoop \
--password sqoop \
--table cities \
--update-key id
sqoop export \
--connect jdbc:mysql://mysql.example.com/sqoop \
--username sqoop \
--password sqoop \
--table cities \
--update-key id \
--update-mode allowinsert
选择性插入
sqoop export \
--connect jdbc:mysql://mysql.example.com/sqoop \
--username sqoop \
--password sqoop \
--table cities \
--columns country,city
Sqoop与其他系统结合
- Sqoop可以与Oozie、Hive、Hbase等系统结合;用户需要在sqoop-env.sh中增加HBASE_HOME、
- HIVE_HOME等环境变量。
Sqoop与Hive结合
sqoop import \
--connect jdbc:mysql://mysql.example.com/sqoop \
--username sqoop \
--password sqoop \
--table cities \
--hive-import
Sqoop与HBase结合
sqoop import \
--connect jdbc:mysql://mysql.example.com/sqoop \
--username sqoop \
--password sqoop \
--table cities \
--hbase-table cities \
--column-family world