【数据集】LVIS:大规模细粒度词汇级标记数据集 ,出自FAIR ,连披萨里的菠萝粒都能完整标注...
本文转自『AI开发者』 稍有改动
作者 / 杨鲤萍,编译 / 昱良
最近,FAIR 开放了 LVIS,一个大规模细粒度词汇集标记数据集,该数据集针对超过 1000 类物体进行了约 200 万个高质量的实例分割标注,包含 164k 大小的图像。

LVIS 数据集概述
我们的目标就是通过设计和收集 LVIS,一个用于大规模词汇量对实例分割研究基准数据集来实现这一新的研究方向,并在最终完成 164k 大小的包含 1000 类物体的约 200 万个高质量的实力分割标注图像数据集。

图 1 示例注释。我们提供了一个新的数据集lvis,用于在 1000+ 类别图像中基准化大型词汇实例分割,以及找出具有挑战性的稀有对象长尾分布
标注流程从一组图像开始,这些图像在未知标记类别的情况下所收集。我们让注标器完成迭代对象定位过程,并找出图像中自然存在的长尾分布,来代替机器学习算法对自动化数据标记过程。
同时也设计了一个众包标注流程,可以收集大型数据集,同时还可以生成高质量的标注。标注质量对于未来的研究非常重要,因为相对粗糙的标注,例如 COCO 数据集,它会限制算法对于标注预测质量的提高。与 COCO 和 ADE20K 相比,我们的数据标注具有更大的重叠面积和更好的边界连续性。
为了构建这个数据集,我们采用了评估优先的设计原则。该原则指出,我们应该首先确定如何执行定量评估,然后再设计和构建数据集收集流程,以满足评估所需数据的需求。我们选择类似与 COCO 风格的实例分段评测基准,并且使用了相同风格的平均精度(AP)度量标准。
解决这些挑战的基本设计选择是构建联合数据集:由大量较小的组成数据集联合形成的单个数据集,每个数据集看起来与单个类别的传统目标检测数据集完全相同。每个小数据集为单个类别提供详尽标注的基本保证,即该类别的所有实例都被标注。多个组成数据集可以重叠,因此图像中的单个对象可以用多个类别标记。此外,由于详尽的标注保证仅存在于每个小数据集中,因此我们不需要对整个联合数据集的所有类别进行详尽地标注,这将大大减少标注工作量。至关重要的是,在测试时每个图像相对于组成数据集的子集衡量标准是算法未知的,因此它必须进行预测,使得所有类别都将被评估。
我们目前在图像识别方面的成功很大程度上归功于 MNIST(http://yann.lecun.com/exdb/mnist/ )、BSDS、Caltech 101、PASCAL VOC、ImageNet 和 COCO 等先驱数据集。这些数据集支持开发检测边缘、执行大规模图像分类以及通过边界框和分割蒙版定位对象的算法。它们还被用于发现重要的方法,如卷积网络、残余网络和批量标准化 。LVIS 的灵感来自这些以及其他相关数据集,包括关注街景(Cityscapes 和 Mapillary)和行人(Caltech Pedestrians)的数据集。

图 2 lvis示例注释(为了清晰起见,每个图像对应一个类别);更多信息请参阅http://www.lvisdataset.org/explore
数据集设计
任务和评估准则
任务和指标。我们的数据集基准是实例分割任务,即给定一组固定的已知类别,然后设计一种算法。当出现之前没有的图像时,该算法将为图像中出现的每个类别中的每个实例输出一个标注以及类别标签与置信度分数。而给定算法在一组图像上的输出,我们使用 COCO 数据集中的定义和实现计算标注平均精度(AP)。
评估挑战。像 PASCAL VOC 和 COCO 这样的数据集使用手动选择的成对不相交类别,例如:当标注汽车时,如果检测到的目标是盆栽植物或沙发,则不会出现错误。但增加类别数量时,则不可避免会出现其他类型的成对关系,例如:部分视觉概念的重叠、父子分类关系的界定、同义词识别等。如果这些关系没有得到妥善解决,那么评估标准将是不公平的。
例如:大多数玩具不是鹿,大多数鹿不是玩具,但是玩具鹿却既是玩具也是鹿。如果检测器输出鹿的同时物体仅标记为玩具,则目标检测算法为错误的标记;如果汽车仅被标记为 vehicle,而算法输出 car,则也是错误的标注。因此,提供公平的基准对于准确反映算法性能非常重要。

图 3 从左到右的类别关系:部分视觉概念的重叠、父子分类关系、等效(同义词)关系;这意味着单个对象可能具有多个有效标签;目标探测器的公平评估必须考虑到多个有效标签的问题
当 GT 标注缺少目标的一个或多个真实标签时,则会出现这些问题。如果算法恰好预测了其中一个正确但不完整的标签,将得到错误的结果。而现在,如果所有目标都是详尽且正确地标记了所有类别,那么问题就可以解决了。
数据集构建
数据集的标注主要分为了六个阶段,包括目标定位、穷尽标记、实例分割、验证、穷尽标注验证以及负例集标注。
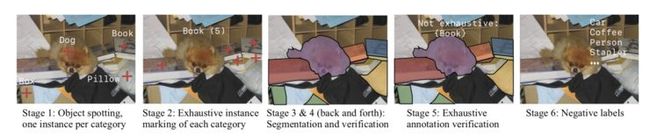
图 4 数据集标注流程的六个阶段
第 1 阶段的目标定位是一个迭代过程,其中每个图像被访问可变次数。在第一次访问时,要求标注器用一个点标记一个对象,并使用自动完成文本输入将其命名为类别 c∈V;在每次后续访问时,显示所有先前发现的对象,并且要求标注器标记先前未标记的类别的对象,或者如果不能发现 V 中的更多类别则跳过图像;当图像被跳过 3 次时,将不再访问该图像。总结阶段 1 的输出:对于词汇表中的每个类别,我们有一组(可能是空的)图像,其中每个图像都标记了该类别的一个目标;这一步骤为每个类别 c 定义了初始正集 Pc。
阶段 2 的穷尽标记目标则是:验证阶段 1 标注和用点标记每个图像 i∈Pc 中的所有 c 实例。在这个阶段,来自阶段 1 的(i,c)对被发送到了 5 个标注器中;首先,它们显示了类别 c 的定义,并验证它是否描述了点标记的目标;如果匹配,则要求标注器标记同一类别的所有其他实例;反之,则终止第二步。因此,从第 2 阶段开始,我们为每个图像提供详尽的实例标注。
在第 3 阶段的实例分割中,我们的目标是:验证第 2 阶段中每个标记对象的类别,以及将每个标记对象从点标注升级到完整分段标注。为此,将图像 i 和标记对象实例 o 的每对(i,o)呈现给一个标注器,该标注器被要求验证 o 的类别标签是否正确,并为它绘制详细的分割标注。从第 3 阶段开始,我们为每个图像和被发现的实例对分配一个分割标注。
第 4 阶段验证时,我们的目标是验证第 3 阶段的分段标注质量。我们将每个分段显示为最多 5 个标注器,并要求它们使用量规对其质量进行评级。如果两个或多个标注器不通过,那么我们将该实例重新排队以进行阶段 3 分段;如果 4 个标注者同意它是高质量的,我们接受该分割标注。我们在第 3 和第 4 阶段之间迭代共四次,每次只重新标注被拒绝的实例。总结第 4 阶段的输出(在第 3 阶段来回迭代之后):我们有超过 99%的所有标记对象的高质量分割标注。
第 5 阶段是穷尽标注验证,它将确定最终的正例集。我们通过询问标注器是否在 i 中存在类别 c 的任何未分段实例来执行此操作。我们要求至少 4 个标注器同意标注是详尽的,而只要有两个人不通过,我们就会将详尽的标注标记 eci 标记为 false。
在最后阶段的负例集标注,它将为词汇表中的每个类别 c 收集负集 Nc。我们通过随机采样图像 i∈D Pc 来做到这一点,其中 D 是数据集中的所有图像。对于每个采样图像 i,如果图像 i 中出现类别 c,我们最多询问 5 个标注器,其中任何一个标注器显示不通过,我们则拒绝该图像。否则将其添加到 Nc。我们采样过程将持续到负例集 Nc 达到数据集中图像的 1%的目标大小。从阶段 6 开始,对于每个类别 c∈V,我们具有负例集 Nc,使得该类别不出现在 Nc 中的任何图像中。
词汇建构
我们使用迭代过程构建词汇表 V,该过程从大型超级词汇表开始,并使用目标定位过程(阶段 1)将其缩小。我们将从 WordNet 中选择的 8.8k 同义词进行明确词汇的删除(例如:专有名词),然后找到了高度具体的常用名词交集。
这产生了一个穷尽的具体组合,因此能得到一些视觉上的入门级同义词;然后,我们将目标定位应用于具有针对这些超级词汇表自动完成的 10k COCO 图像。这将减少词汇量,然后我们再次重复这一过程,最后,我们执行次要的手动编辑,得到了包含 1723 个同义词的词汇表,这也是可以出现在 LVIS 中的类别数量的上限。
LVIS 数据集标注结果
通过使用 LVIS,我们能够将很多图像中对于某一类别图像进行完整的标注,包括一些小的、被遮盖的、难以辨认的,都能够通过这一方法实现标注。

图 5 LVIS 上标注得到的分类数据展示(1)
在 LVIS 的网站上,我们可以看到大量的标注结果,包括一些小工具(剪刀、桶),小配饰(太阳镜、腰带),餐盘里的黄瓜,甚至是披萨上的菠萝粒,都能够完整的标注出来。

图 6 LVIS 上标注得到的分类数据展示(2)
正如 FAIR 自己所说:LVIS 是一个新的数据集,旨在首次对实例分割算法进行严格的研究,它可以识别不同对象类别的大量词汇(> 1000)。虽然 LVIS 强调从少数例子中学习,但数据集并不小;它将跨越 164k 图像并标记~2 百万个对象实例。每个对象实例都使用高质量的蒙版进行分割,该蒙版超过了相关数据集的标注质量。
原文链接:
https://arxiv.org/pdf/1908.03195.pdf
LVIS 网站:
http://www.lvisdataset.org
封面图来源:
LVIS 网站(http://www.lvisdataset.org)
推荐阅读
高考失常错过清华,而今保送清华直博,还发了数篇 Nature
【知识点】关于 CPU,这些基础必须得懂!
12岁上大学,23岁获博士学位,31岁成最年轻IEEE Fellow,这位少年班走出的神童有多厉害?
各种AI模型拿来就能用!五大深度学习模型库大盘点
那个双非本科,还想转算法岗的姑娘,最后怎么了?

喜欢就点击“在看”吧