如何薅羊毛 | PyTorch终于能用上谷歌云TPU,推理性能提升4倍
晓查 发自 凹非寺
量子位 报道 | 公众号 QbitAI
Facebook在PyTorch开发者大会上正式推出了PyTorch 1.3,并宣布了对谷歌云TPU的全面支持,而且还可以在Colab中调用云TPU。
之前机器学习开发者虽然也能在Colab中使用PyTorch,但是支持云TPU还是第一次,这也意味着你不需要购买昂贵的GPU,可以在云端训练自己的模型。
而且如果你是谷歌云平台(Google Cloud Platform)的新注册用户,还能获得300美元的免费额度。

现在PyTorch官方已经在Github上给出示例代码,教你如何免费使用谷歌云TPU训练模型,然后在Colab中进行推理。
训练ResNet-50
PyTorch先介绍了在云TPU设备上训练ResNet-50模型的案例。如果你要用云TPU训练其他的图像分类模型,操作方式也是类似的。
在训练之前,我们先要转到控制台创建一个新的虚拟机实例,指定虚拟机的名称和区域。

如果要对Resnet50在真实数据上进行训练,需要选择具有最多CPU数量的机器类型。为了获得最佳效果,请选择n1-highmem-96机器类型。
然后选择Debian GNU/Linux 9 Stretch + PyTorch/XLA启动盘。如果打算用ImageNet真实数据训练,需要至少300GB的磁盘大小。如果使用假数据训练,默认磁盘大小只要20GB。
创建TPU
转到控制台中创建TPU。
在“Name”中指定TPU Pod的名称。
在“Zone”中指定云TPU的区域,确保它与之前创建的虚拟机在同一区域中。
在“ TPU Type”下,选择TPU类型,为了获得最佳效果,请选择v3-8TPU(8个v3)。
在“ TPU software version”下,选择最新的稳定版本。
使用默认网络。
设置IP地址范围,例如10.240.0.0。
官方建议初次运行时使用假数据进行训练,因为fake_data会自动安装在虚拟机中,并且只需更少的时间和资源。你可以使用conda或Docker进行训练。
在fake_data上测试成功后,可以开始尝试用在ImageNet的这样实际数据上进行训练。
用conda训练:
# Fill in your the name of your VM and the zone.
$ gcloud beta compute ssh "your-VM-name" --zone "your-zone".
(vm)$ export TPU_IP_ADDRESS=your-ip-address
(vm)$ export XRT_TPU_CONFIG="tpu_worker;0;$TPU_IP_ADDRESS:8470"
(vm)$ ulimit -n 10240
(vm)$ conda activate torch-xla-0.5
(torch-xla-0.5)$ python /usr/share/torch-xla-0.5/pytorch/xla/test/test_train_imagenet.py --datadir=~/imagenet --model=resnet50 --num_epochs=90 --num_workers=64 --batch_size=128 --log_steps=200
$ gcloud beta compute ssh "your-VM-name" --zone "your-zone".
(vm)$ export TPU_IP_ADDRESS=your-ip-address
(vm)$ export XRT_TPU_CONFIG="tpu_worker;0;$TPU_IP_ADDRESS:8470"
(vm)$ ulimit -n 10240
(vm)$ conda activate torch-xla-0.5
(torch-xla-0.5)$ python /usr/share/torch-xla-0.5/pytorch/xla/test/test_train_imagenet.py --datadir=~/imagenet --model=resnet50 --num_epochs=90 --num_workers=64 --batch_size=128 --log_steps=200
用Docker训练:
# Fill in your the name of your VM and the zone.
$ gcloud beta compute ssh "your-VM-name" --zone "your-zone".
(vm)$ export TPU_IP_ADDRESS=your-ip-address
(vm)$ docker run --shm-size 128G -v ~/imagenet:/tmp/imagenet -e XRT_TPU_CONFIG="tpu_worker;0;$TPU_IP_ADDRESS:8470" gcr.io/tpu-pytorch/xla:r0.5 python3 pytorch/xla/test/test_train_imagenet.py --model=resnet50 --num_epochs=90 --num_workers=64 --log_steps=200 --datadir=/tmp/imagenet
$ gcloud beta compute ssh "your-VM-name" --zone "your-zone".
(vm)$ export TPU_IP_ADDRESS=your-ip-address
(vm)$ docker run --shm-size 128G -v ~/imagenet:/tmp/imagenet -e XRT_TPU_CONFIG="tpu_worker;0;$TPU_IP_ADDRESS:8470" gcr.io/tpu-pytorch/xla:r0.5 python3 pytorch/xla/test/test_train_imagenet.py --model=resnet50 --num_epochs=90 --num_workers=64 --log_steps=200 --datadir=/tmp/imagenet
在n1-highmem-96的虚拟机上选用完整v3-8 TPU进行训练,第一个epoch通常需要约20分钟,而随后的epoch通常需要约11分钟。该模型在90个epoch后达到约76%的top-1准确率。
为了避免谷歌云后续进行计费,在训练完成后请记得删除虚拟机和TPU。
性能比GPU提升4倍
训练完成后,我们就可以在Colab中导入自己的模型了。
打开notebook文件,在菜单栏的Runtime中选择Change runtime type,将硬件加速器的类型改成TPU。
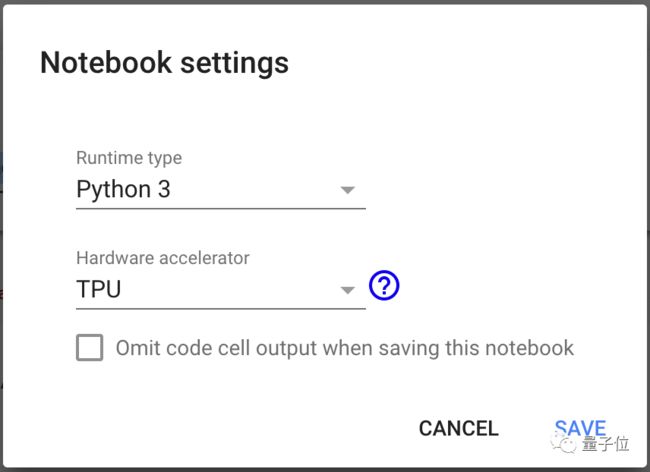
先运行下面的代码单元格,确保可以访问Colab上的TPU:
import os
assert os.environ[‘COLAB_TPU_ADDR’], ‘Make sure to select TPU from Edit > Notebook settings > Hardware accelerator’
assert os.environ[‘COLAB_TPU_ADDR’], ‘Make sure to select TPU from Edit > Notebook settings > Hardware accelerator’
然后在Colab中安装兼容PyTorch/TPU组件:
DIST_BUCKET="gs://tpu-pytorch/wheels"
TORCH_WHEEL="torch-1.15-cp36-cp36m-linux_x86_64.whl"
TORCH_XLA_WHEEL="torch_xla-1.15-cp36-cp36m-linux_x86_64.whl"
TORCHVISION_WHEEL="torchvision-0.3.0-cp36-cp36m-linux_x86_64.whl"
# Install Colab TPU compat PyTorch/TPU wheels and dependencies
!pip uninstall -y torch torchvision
!gsutil cp "$DIST_BUCKET/$TORCH_WHEEL" .
!gsutil cp "$DIST_BUCKET/$TORCH_XLA_WHEEL" .
!gsutil cp "$DIST_BUCKET/$TORCHVISION_WHEEL" .
!pip install "$TORCH_WHEEL"
!pip install "$TORCH_XLA_WHEEL"
!pip install "$TORCHVISION_WHEEL"
!sudo apt-get install libomp5
TORCH_WHEEL="torch-1.15-cp36-cp36m-linux_x86_64.whl"
TORCH_XLA_WHEEL="torch_xla-1.15-cp36-cp36m-linux_x86_64.whl"
TORCHVISION_WHEEL="torchvision-0.3.0-cp36-cp36m-linux_x86_64.whl"
# Install Colab TPU compat PyTorch/TPU wheels and dependencies
!pip uninstall -y torch torchvision
!gsutil cp "$DIST_BUCKET/$TORCH_WHEEL" .
!gsutil cp "$DIST_BUCKET/$TORCH_XLA_WHEEL" .
!gsutil cp "$DIST_BUCKET/$TORCHVISION_WHEEL" .
!pip install "$TORCH_WHEEL"
!pip install "$TORCH_XLA_WHEEL"
!pip install "$TORCHVISION_WHEEL"
!sudo apt-get install libomp5
接下来就可以导入你要训练好的模型和需要进行推理的图片了。
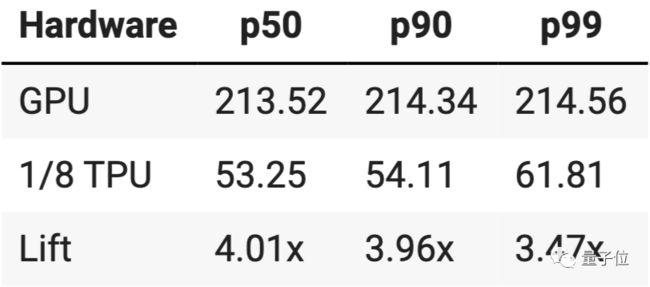
在PyTorch上使用TPU对性能的提升到底有多明显呢?官方选用了v2-8的一个核心,即1/8 TPU的情形,与使用英伟达Tesla K80 GPU进行对比,实测显示推理时间大大缩短,性能约有4倍左右的提升。
GitHub地址:
https://github.com/pytorch/xla/tree/master/contrib/colab
https://github.com/pytorch/xla/tree/master/contrib/colab
作者系网易新闻·网易号“各有态度”签约作者
推荐阅读
