python-scrapy模拟登陆网站--登陆青果教务管理系统(二)
前言:
第一篇,分析青果教务管理系统登陆模块,理清思路
第二篇,使用常规的python常用库 requests来实现模拟登陆
第三篇,使用scrapy来实现模拟登陆
目的在于了解模拟登陆网站的要点和方法,了解http请求的一些知识。
(1)前期工作
该篇最好参考下源码理解查看,源码在文章最后。
上一篇我们说明了模拟登陆青果教务系统需要注意的问题。那么我们就先把,密码验证码的加密,保存验证码图片等先写一下测试一下。
1、密码和验证码加密
上一篇中我们已经找到了加密的算法,通常在登陆的参数有加密的话,加密算法都会在前台写好。我们只需要找到即可。
加密:
function chkpwd(obj) {
if (obj.value != '') {
var s = md5(document.all.txt_asmcdefsddsd.value + md5(obj.value).substring(0, 30).toUpperCase() + '10479').substring(0, 30).toUpperCase();
document.all.dsdsdsdsdxcxdfgfg.value = s;
} else {
document.all.dsdsdsdsdxcxdfgfg.value = obj.value;
}
}
function chkyzm(obj) {
if (obj.value != '') {
var s = md5(md5(obj.value.toUpperCase()).substring(0, 30).toUpperCase() + '10479').substring(0, 30).toUpperCase();
document.all.fgfggfdgtyuuyyuuckjg.value = s;
} else {
document.all.fgfggfdgtyuuyyuuckjg.value = obj.value.toUpperCase();
}
}(document.all.txt_asmcdefsddsd.value 是用户名)
chkpwd 加密密码的 , chkyzm 加密验证码的。
这两个js 方法触发的地方,在form 表单中:
密 码
验证码
根据上面的描述,我们编写 python 代码实现,代码如下:
md5tools.py
# coding:utf-8
import md5
def md5_encrypt(src):
"""
md5 加密
:param src: 需要加密的字段
:return:
"""
m1 = md5.new()
m1.update(src.encode(encoding='utf-8'))
return m1.hexdigest()
# function chkpwd(obj) {
# if(obj.value!='')
# { var s=md5(document.all.txt_asmcdefsddsd.value+md5(obj.value).substring(0,30).toUpperCase()+'10479').substring(0,30).toUpperCase();
# document.all.dsdsdsdsdxcxdfgfg.value=s;} else { document.all.dsdsdsdsdxcxdfgfg.value=obj.value;
# } }
#function chkyzm(obj) { if(obj.value!='') { var s=md5(md5(obj.value.toUpperCase()).substring(0,30).toUpperCase()+'10479').substring(0,30).toUpperCase(); document.all.fgfggfdgtyuuyyuuckjg.value=s;} else { document.all.fgfggfdgtyuuyyuuckjg.value=obj.value.toUpperCase();}}
username = "xxxx"
passwd = "xxx"
yzm = 'gbhg'
#密码加密
passwd_jiami = md5_encrypt((username+md5_encrypt(passwd)[0:30].upper()+'10479'))[0:30].upper()
print passwd_jiami
#验证码加密
yzm_jiami = md5_encrypt((md5_encrypt(yzm.upper())[0:30].upper()+'10479'))[0:30].upper()
print yzm_jiami我们只是用python的写法重写了一遍加密的过程。
1.2、获取请求的cookie信息
上一篇中已经介绍了,cookie 的用途,就是用来标识用户,来保证同一个用户对应用一个会话。
代码如下:
getCookie.py
# coding:utf-8
import requests
def getCookieByRequestUrl(response):
"""
根据请求的响应获取cookie信息
:param response: 请求网站后的响应
:return:
"""
cookiejar = response.cookies
# 8. 将CookieJar转为字典:
cookiedict = requests.utils.dict_from_cookiejar(cookiejar)
return cookiedict['ASP.NET_SessionId']
# print cookiejar
#
# print cookiedict
def getCookieByRequestSession(url,headers):
"""
发送请求获取cookie信息
:param url: 请求的网站的网址
:param headers: 请求头
:return:
"""
session = requests.session()
response = session.get(url=url,headers=headers)
cookiedict = requests.utils.dict_from_cookiejar(response.cookies)
return cookiedict['ASP.NET_SessionId']
headers ={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"
}
# print getCookieByRequestUrl("http://jwglxt.aynu.edu.cn/",headers=headers)
#print getCookieByRequestSession("http://jwglxt.aynu.edu.cn/",headers=headers)1.3、保存验证码图片
上一篇我们已经知道验证码的网址了:http://jwglxt.aynu.edu.cn/sys/ValidateCode.aspx?t=198
我们就按照上一篇说的第一种做法,将验证码下载到本地,我们自己查看后,手动输入。
但是要注意,我们要在同一个cookie 下获取验证码才是有用的,而且在请求验证码的时候请求头中需要Referer 等字段,
我们最直接的做法就是原模原样的将浏览器正常请求验证码网址的请求头拿下拉使用。
代码如下:
getyzm.py
# coding:utf-8
import requests
import time
from getCookie import getCookieByRequestUrl
def getYZMImage(url,cookie):
"""
请求验证码的网址,下载验证码信息
:param url: 验证码的链接
:param cookie: cookie信息
:return:
"""
cookievalue = 'ASP.NET_SessionId='+str(cookie)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36",
'Cookie':cookievalue,
'Referer': 'http://jwglxt.aynu.edu.cn/_data/home_login.aspx',
'Connection':'keep-alive',
'Accept-Language':'zh-CN,zh;q=0.9',
#'Accept-Encoding':' gzip, deflate',
'Accept':'image/webp,image/apng,image/*,*/*;q=0.8',
'Host':'jwglxt.aynu.edu.cn',
}
response = requests.get(url=url,headers =headers)
captcha(response.content)
def captcha(data):
"""
保存验证码图片到本地
:param data:
:return:
"""
with open('captcha.jpg','wb') as fp:
fp.write(data)
time.sleep(1)
# headers ={
# "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"
# }
#
# cookie = getCookieByRequestUrl("http://jwglxt.aynu.edu.cn/",headers=headers)
#
# url = "http://jwglxt.aynu.edu.cn/sys/ValidateCode.aspx?t=121"
# getYZMImage(url=url,cookie=cookie)(2)编写模拟登陆的代码
下面我们会从开始网址到最后获取到登陆数据介绍整个流程。
1,访问教务系统主网页获取cookie信息
response = requests.get(url="http://jwglxt.aynu.edu.cn/", headers=headers)
cookie = getCookieByRequestUrl(response)2,拼装新的请求头,访问登陆的链接,获取到额外的参数和对应的值
获取的值就是上一篇中说的 form 表单额外的参数
loginhomeheaders = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36",
'Cookie': cookie,
'Referer': 'http://jwglxt.aynu.edu.cn/',
#'Referer': 'http://jwglxt.aynu.edu.cn/default.new.aspx',
}
loginhomeurl = 'http://jwglxt.aynu.edu.cn/_data/home_login.aspx'
response = requests.get(loginhomeurl,headers=loginhomeheaders)
VIEWSTATE = re.search(r'这里我们使用了正则来获取该值,本来是想用xpath,但是由于是 隐藏的input 不是很好获取,就采用了正则的方式。
这里我们来演示下Referer 的作用,在不加的情况下,我们访问登陆链接。直接系统出错,这就是系统验证了该链接不是从http://jwglxt.aynu.edu.cn/ 发出的,直接响应失败。

如果是加上 Referer 就可以正常访问
3、根据cookie信息,访问验证码链接,保存验证码图片到本地
url = "http://jwglxt.aynu.edu.cn/sys/ValidateCode.aspx?t="+str(random.randint(0,999))
getYZMImage(url=url, cookie=cookie)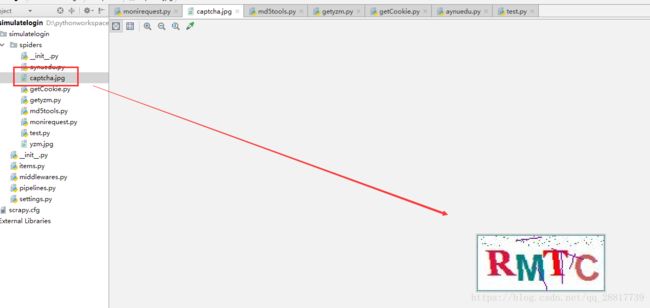
4、等待用户输入账号,密码,验证码,将密码和验证码进行加密处理
username = str(raw_input("请输入账号:"))
print username
passwd = str(raw_input("请输入密码:"))
print passwd
yzm = str(raw_input("请输入验证码:"))
print yzm
# username = "xxx"
# passwd = "xxx"
# 密码加密
passwd_jiami = md5_encrypt((username + md5_encrypt(passwd)[0:30].upper() + '10479'))[0:30].upper()
# 验证码加密
yzm_jiami = md5_encrypt((md5_encrypt(yzm.upper())[0:30].upper() + '10479'))[0:30].upper()我们使用raw_input 来接收用户输入的数据
5、访问登陆的网址,模拟登陆
def login(username,passwd,yzm,cookie,viewstate):
#组拼 data
login_data = {
'__VIEWSTATE':viewstate,
'pcInfo':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36undefined5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36 SN:NULL',
'typeName':'ѧ��',
'dsdsdsdsdxcxdfgfg': passwd,
'fgfggfdgtyuuyyuuckjg':yzm,
'Sel_Type': 'STU',
'txt_asmcdefsddsd':username,
'txt_pewerwedsdfsdff':'',
'txt_sdertfgsadscxcadsads':'',
}
cookievalue = 'ASP.NET_SessionId=' + str(cookie)
login_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36",
'Cookie':cookievalue,
'Referer': 'http://jwglxt.aynu.edu.cn/_data/home_login.aspx',
'Origin': 'http://jwglxt.aynu.edu.cn',
}
loginurl = "http://jwglxt.aynu.edu.cn/_data/home_login.aspx"
session = requests.session()
response = session.post(url=loginurl,data=login_data,headers=login_headers)
getinfoheaders = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36",
'Cookie': cookievalue,
'Referer': 'http://jwglxt.aynu.edu.cn/xsxj/Stu_MyInfo.aspx',
}
response1 = session.get(url="http://jwglxt.aynu.edu.cn/xsxj/Stu_MyInfo_RPT.aspx",headers=getinfoheaders)
print response1.text解释几点:'typeName':'ѧ��', 这个就是 “学生”,但是在浏览器端登陆的时候,就是将其转码了,所以我们也写成这样。
登陆一般都是 post 请求,所以我们构建了一个 login_data 就是登陆的数据,跟使用浏览器登陆一致。
请求头也有所变化,我们写的与浏览器登陆一致即可。
当登陆成功之后,就可以获取数据了。这里就会使用到session了,其实还是cookie,因为有了cookie,session才能找到。
这里使用了 requests.session() 会自动携带一些登陆信息,免去设置cookie
自己可以测试使用一下。
6、获取登陆后某网页的数据
response1 = session.get(url="http://jwglxt.aynu.edu.cn/xsxj/Stu_MyInfo_RPT.aspx",headers=getinfoheaders)
print response1.text我们可以看下打印的数据。看是否正常获取。
(3)测试模拟登陆
由于不能直观的看到请求的过程,我们使用fidder来进抓包。关于fidder软件的使用,可以参考很多网站。
让我们运行写好的模拟登陆的爬虫:monirequest.py
先看下控制台:
爬取成功,我们来分析一下fidder 访问的过程:
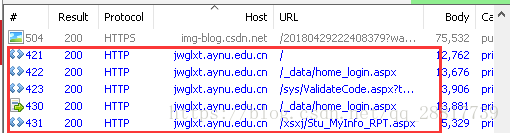
所有的请求都在这里了。
看第一个请求:http://jwglxt.aynu.edu.cn/ 教务系统的主网站
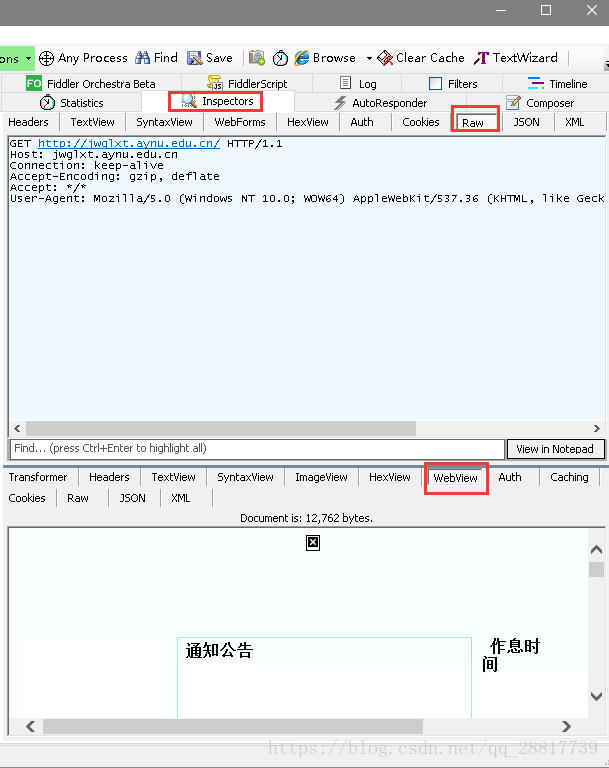
这是第一次请求,没有cookie信息。正常的请求,没啥问题。
查看第二个请求,登陆的界面 http://jwglxt.aynu.edu.cn/_data/home_login.aspx
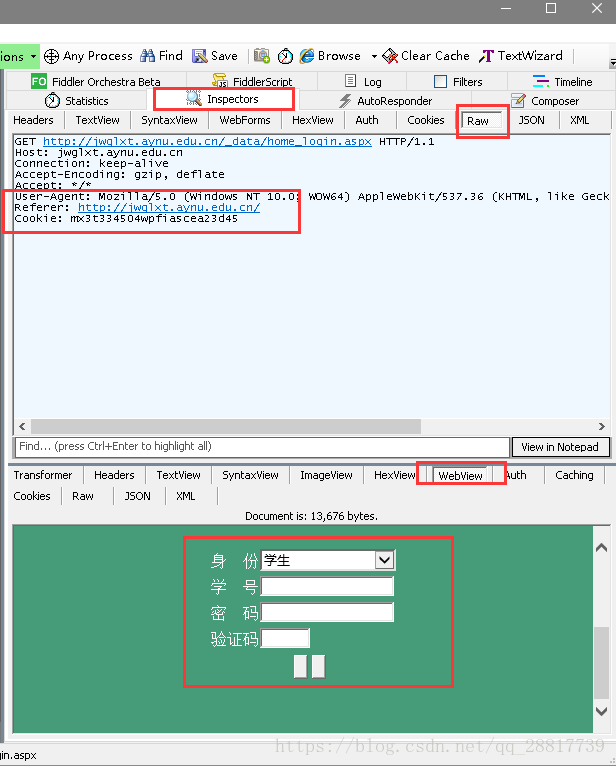
注意查看 cookie 信息 和referer 信息,我们正确的拿到了登陆的界面
查看第三个请求,获取验证码图片 http://jwglxt.aynu.edu.cn/sys/ValidateCode.aspx?t=203
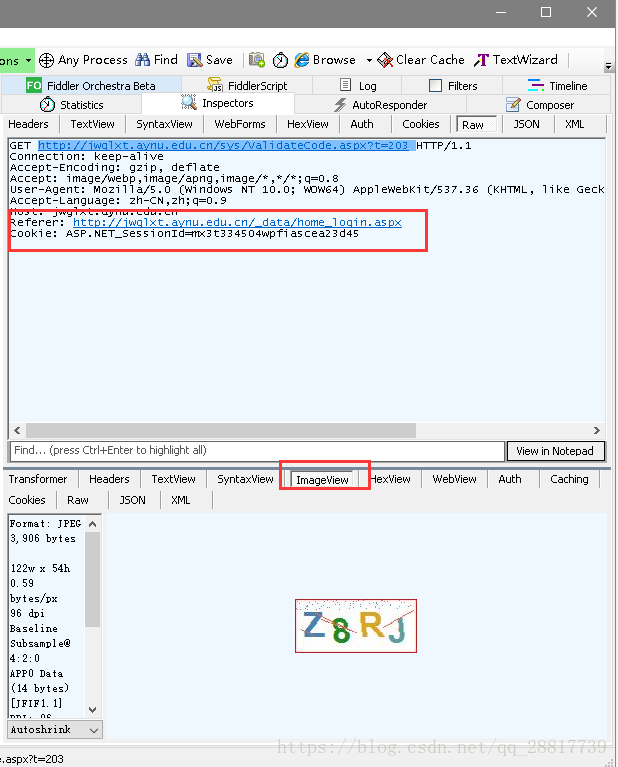
注意 cookie 和 referer ,显然 cookie 值是跟上一个请求一致的。 而且我们也看到了验证码的图片。
查看第四个请求,模拟登陆,发送登陆请求,http://jwglxt.aynu.edu.cn/_data/home_login.aspx
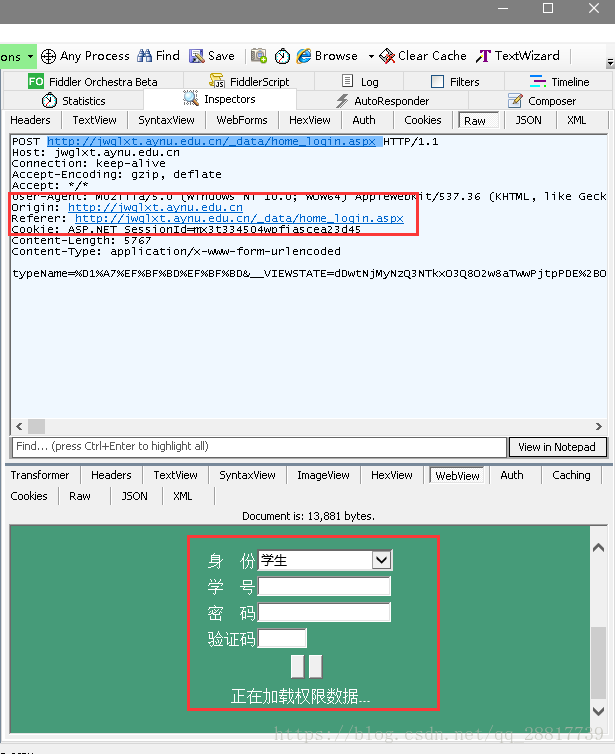
注意 cookie ,referer 和 origin。cookie没有改变。
再来看下请求发送的数据
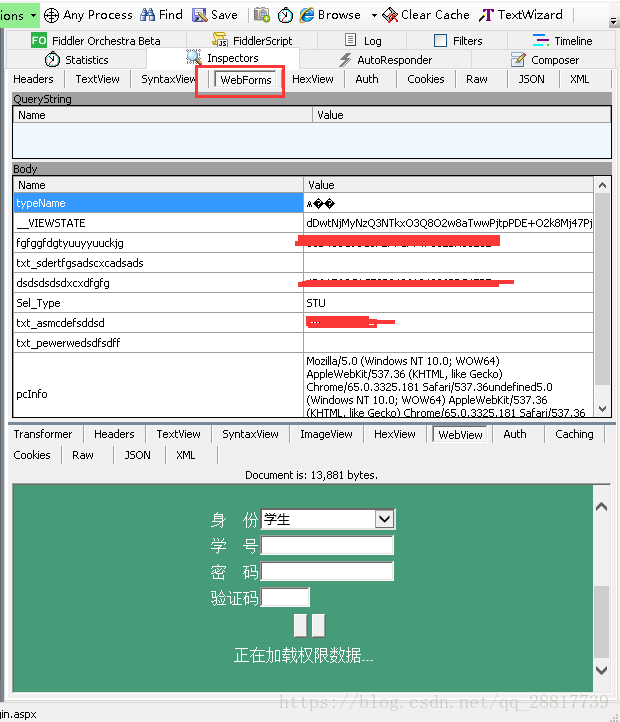
我们发现和浏览器登陆发送的一致。
查看最后发送的请求,获取登陆后才能查看的数据。http://jwglxt.aynu.edu.cn/xsxj/Stu_MyInfo_RPT.aspx
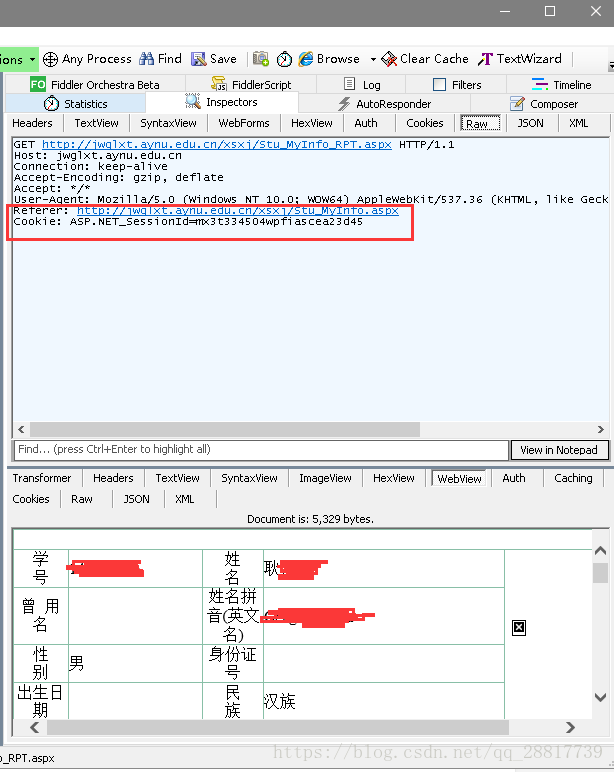
数据正确的拿回来了。
(4)总结
这一篇中我们使用了python常用库requests 来完成了模拟登陆,只要跟浏览器登陆一致,设置正确的请求头,参数。都是可以登陆的。这一部分的代码也可以换成java代码编写,原理没有区别。如果我在文中暴露了账号密码,请不要使用,谢谢。
源码:https://github.com/gengzi/simulatelogin
码字不易,给个赞吧。