反射与泛型--徒手教你写个Android数据库Dao层玩玩
最近一直在忙项目数据库重构,需求是把所有的内容提供者以及对数据库的操作都换成Orm(Object Relational Mapping)关系对象关系映射。期间遇到非常多的问题,于是乎把数据库的orm的代码都撸了一遍,在此记录一下学习过程。
泛型与反射
之前每次听人家讲反射和泛型,总感觉叼叼的,这次深入学习了一下,感觉,反射和泛型的用处非常大,可以使我们把一项知识存放在一处,以遵守DRY(Don't Repeat Yourself)原则.
首先是反射,其实就是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制(百度百科上定义的),单纯概念上可以得到,反射就是用来知道类的属性和方法的,这时候你可能会笑了,我通过get和set也可以改变属性为什么还需要反射,举个例子吧,我要操作一个类,计划中这个类里面有个name属性,但是这个类是其他程序员写的,我们不知道他有没有加这个属性。但是我们还是要完成我们的工作啊,要能编译,怎么办,这时候就用到了反射咯。我不管你这个类中有没有name属性,我先把我的代码并且能编译的代码写出来。看代码
Student学生类 计划中里面有个name属性,但由于其他程序员未完成,所以没有这个属性。
public class Student {
//什么也没有,别的程序员还没动工呢?
}
Test测试类
public static void main(String[] args) throws SecurityException, IllegalArgumentException, IllegalAccessException {
// TODO Auto-generated method stub'
Student stu = new Student();
//获得Class实例
Class cls= stu.getClass();
Field field;
try {
//获取Student的name字段,如果存在继续执行,否则被异常Catch住,输出“Dao't have name”
field = cls.getDeclaredField("name");
field.setAccessible(true);//如果字段为私有的,必须调用,来打破权限
System.out.println(field.get(stu))
} catch (NoSuchFieldException e) {
// TODO Auto-generated catch block
System.out.println("Don't have name");
}
}测试结果:
Don't have name看到没,虽然Student类中没有name属性,但并不影响程序的工作啊,只是被异常catch到了。再来试一下在Student类中加入name属性看看。
public class Student {
private String name = "rush_yu";
public String getName() {
name ="rcl";
return name;
}
public void setName(String name) {
this.name = name;
}
}
测试结果:
rush_yu
看到没,我Test类什么都没改,就仅仅在Student中加入一个name属性,Test里面的就获取到了name的值咯,这样是不是更高效一点,在也不用等其他人写完代码,然后我们在去调用咯。仔细的看看你还会发现name属性定义的是private私有的,原则上私有的只能是此类中访问,但是我们通过反射也可以得到咯,反射已经打破private属性,让你获得私有的变量值。你现在还会觉得反射没用吗?
下面我们在讲讲泛型吧。
泛型泛型指的就是泛指任何类型,就是可以代替任何类型的对象啊。
有人会问,为什么要用泛型啊?我java中的Object不是可以用来代替任何类型吗?其实Object虽然能代替任何类型,因为它是所有类的父类,面向各种各样的子类,实现了一个多态(一种类型多种运作形态),Object的短板就出来咯,通过对类型Object的引用来实现参数的“任意化”,“任意化”带来的缺点是要做显式的强制类型转换,而这种转换是要求开发者对实际参数类型可以预知的情况下进行的。对于强制类型转换错误的情况,编译器可能不提示错误,在运行的时候才出现异常,这是一个安全隐患。我们来看看代码,Object给我带来的问题
新建一个Sun类
public class Sun {
private String age;
public String getAge() {
return age;
}
public void setAge(String age) {
this.age = age;
}
}Test2代码
public static void main(String[] args) {
// TODO Auto-generated method stub
Object stu = new Student();
Sun stu2= (Sun) stu;
System.out.println(stu2.getAge());
}测试结果:
Exception in thread "main" java.lang.ClassCastException: Student cannot be cast to Sun
at Test2.main(Test2.java:10)
我们先把Student对象转换成Object对象,之后将Object对象强制类型转换成Sun对象,对象类型转换错误,编译器没有提示错误哟,结果一运行就出错了,这就是Object的短板,相反泛型的好处是在编译的时候检查类型安全,并且所有的强制转换都是自动和隐式的,提高代码的重用率。
在引入范型之前,要在类中的方法支持多个数据类型,就需要对方法进行重载,在引入范型后,可以解决此问题
(多态),更进一步可以定义多个参数以及返回值之间的关系。
例如
public void generic(String i);
public void generic(Float d);
的范型版本为
public void generic(T t);
下面讲一下泛型的例子吧,
public class Book {
public static Book create(){
return new Book();
}
public void generic(T t){
System.out.println(t.toString());
}
} 测试代码
public static void main(String args[]){
Book book = Book.create();
book.generic("aa");
book.generic(1);
}测试结果
aa
1泛型更多细节,以及时如何在编译时类型擦除,感兴趣的可以去看一下http://blog.csdn.net/lonelyroamer/article/details/7868820这篇博客写的挺不错的,还有参考jdk官网http://www.oracle.com/technetwork/java/index.html。
扯了这么多,万能的Dao层的该有的两个知识点都有了,我们下面就来一步一步的实现这个万能的Dao把!!
项目需求:
项目经理最近脑洞大开,让你设计一个数据库并且对一张表的操作,
对于有很多年OO经验的小马来说,这都不是事啊,很快小马写出了一个MySqliteOpenHelper数据库管理类。然后对一个Student表进行操作。看代码咯!注释写的好详细我就不说咯。
数据库管理类:
public class MySqliteOpenHelper extends SQLiteOpenHelper{
public MySqliteOpenHelper(Context context, String name,
CursorFactory factory, int version) {
super(context, name, factory, version);
// TODO Auto-generated constructor stub
}
@Override
public void onCreate(SQLiteDatabase db) {
// TODO Auto-generated method stub
db.beginTransaction();//开始事务处理
/**
* 创建一个student表
*/
db.execSQL("create table student (_id int primary key,name varchar(50) not null,age varchar(50) not null)");
db.setTransactionSuccessful();//事务提交
db.endTransaction();//事务结束
}
@Override
public void onUpgrade(SQLiteDatabase db, int arg1, int arg2) {
// TODO Auto-generated method stub
System.out.println("数据库版本升级时回调");
db.beginTransaction();//开始事务处理
/**
* 创建一个student表
*/
db.execSQL("create table student (depNo int primary key,depName varchar(50) not null,depMan varchar(50) not null)");
db.setTransactionSuccessful();//事务提交
db.endTransaction();//事务结束
}
MainActivity界面:
protected void onCreate(Bundle savedInstanceState) {
// TODO Auto-generated method stub
super.onCreate(savedInstanceState);
setContentView(R.layout.main);
name = (EditText) findViewById(R.id.name);
age = (EditText) findViewById(R.id.age);
lv = (ListView) findViewById(R.id.lv);
//1为版本号,初始化时版本号必须大于0
mySqliteOpenHelper = new MySqliteOpenHelper(this, "rush_yu", null, 1);
}
/**
* 插入数据库操作
* @param view
*/
public void insert(View view){
SQLiteDatabase db =mySqliteOpenHelper.getWritableDatabase();
ContentValues values = new ContentValues();
values.put("name", name.getText().toString().trim());
values.put("age", age.getText().toString().trim());
db.insert("student", null, values);
}
/**
* 查询数据库操作
* @param view
*/
public void query(View view){
List mList = new ArrayList();
SQLiteDatabase db = mySqliteOpenHelper.getReadableDatabase();
Cursor cursor = db.query("student", null, null, null, null, null, null);
while(cursor.moveToNext()){
mList.add("name="+cursor.getString(cursor.getColumnIndex("name"))+",age="+cursor.getString(cursor.getColumnIndex("age")));
Log.v("YX", "1");
}
ArrayAdapter adapter = new ArrayAdapter(this, android.R.layout.simple_list_item_1, mList);
lv.setAdapter(adapter);
}
main.xml好简单,具体参考最后的源代码,
Test结果
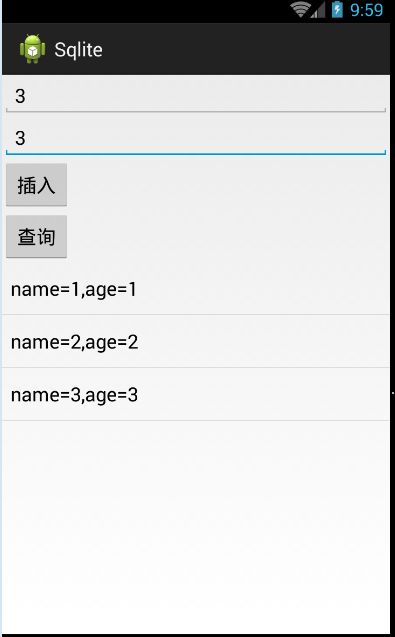
聪明的小马写完程序,兴奋的跑去向老板炫耀自己的成果咯,老板也比较满意小马的设计,但是老板又开始兴奋,又给了小马几个表,小马,照刚才样子做了,写了几个后小马发现,插入的表名和values都是写死了的,每增加一个表,我们就要在写一次insert和query,烦不烦啊,都是在写一些重复操作数据库的代码啊?没有意思哦,好无聊啊,这时候他在想有没有什么设计能帮我只要写一遍代码,不用再去改数据库操作了啊,这时候我们就来帮帮小马分析分析把!!
小马要实现的也就是一个这样的功能:
我不知道你表名是什么,我也不知道你有多少表,就算你数据库里面没有这张表,我也能对你操作,对你进行增删改查,就是这么Nb,就是这么厉害。好,下面我们就来写dao的代码帮帮小马把!!Come on.
首先打开eclipse,然后新建项目NBDao,就叫他NbDao,非常nb。
接下来分包
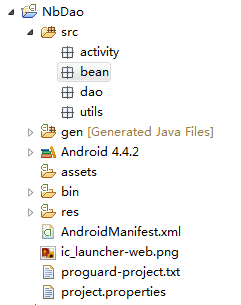
分四个,bean放值对象,uitis放数据库管理,activity放界面,dao放我们的Dao层。
界面布局非常简单
 跟之前一样我们先写一个数据库管理类MySqliteOpenHelper把 ,跟之前的一样,我就不写了,直接copy过来,接下来我们就要用类似hibernate配置,去配置xml与数据库字段的映射。首先在assets下面新建一个xml文件,我的规范是xml的名字跟数据库的表名相同,并且是以student.orm.xml这种命名方式出现的,便于我们查找。当然你们可以有你们自己的规范。
跟之前一样我们先写一个数据库管理类MySqliteOpenHelper把 ,跟之前的一样,我就不写了,直接copy过来,接下来我们就要用类似hibernate配置,去配置xml与数据库字段的映射。首先在assets下面新建一个xml文件,我的规范是xml的名字跟数据库的表名相同,并且是以student.orm.xml这种命名方式出现的,便于我们查找。当然你们可以有你们自己的规范。
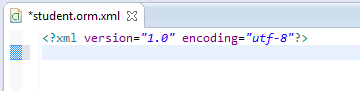
我要的是一个空的xml文件哈,大家别建错咯。
之后在bean包下面新建一个值对象Student类吧,所谓的值对象指的就是数据库字段对应的对象。
public class Student {
//主键
private Integer _id;
private String name;
private String age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAge() {
return age;
}
public void setAge(String age) {
this.age = age;
}
}好简单把,之后我们开始写我们的student.orm.xml把。
有些人可能不会写咯,平常都是编译工具自动生成的,习惯了自动生成了的咯,原生的并不会写,没事的,跟着脚步来吧。
先我们把这个对应student表的起一个根节点如 Orm结点
<Orm tableName="student" beanName="Student">
Orm>根节点名字可以随意起,之后定义两个属性,一个是tableName对应数据表的名字,另一个是Student对应值对象的名字,tableName和beanName可以随意起名.大家应该知道一条数据一般分成两部分,一部分是主键Key,另一部分是属性item。所以我们在Orm中这样子写。
<Orm tableName="student" beanName="Student">
<Key column="_id" property="_id" type="java.lang.Integer" identity="true"/>
<item column="name" property="name" type="java.lang.String"/>
<item column="age" property="age" type="java.lang.String"/>
Orm>属性名字可以随意起,自己喜欢就好,之后的值需对应。
column对应数据库字段,property对应值对象中的值,type对应数据类型。
徒手写的xml写完了,之后我们在utils包下新建一个Key类和Item类以及Orm类对应xml三个跟节点。
我们先写Item类把
public class Item {
private String column;
private String property;
private String type;
}然后生成三个属性的构造函数,Key比Item多一个属性,我们采用继承的方式。
Key类
public class Key extends Item{
private boolean identity;
}
同理Orm类
public class Orm {
private String tableName;
private String beanName;
//只有一个主键的情况
private Key key;
//多个属性
private List- items = new ArrayList
- ();
}
也许也有人问了,搞这些要干嘛啊!!好复杂啊,我来总结一下,我们把数据库的所有信息都放入了xml文件中,我们操作数据表所需的所有内容都可以从xml文件得到,我们现在要做的只是把xml解析出来,解析成一个Orm对象。然后从对象中获取我们需要的内容。继续往下看
在utils包下新建一个TemplateConfig类
我们采用Pull解析,解析student.orm.xml文件,看代码
public class TemplateConfig {
//map集合存放多个xml解析出来文件
public static Map mapping = new HashMap();
public static Orm parser(InputStream is) throws Exception{
Orm orm =null;
//获取一个解析工厂
XmlPullParserFactory xmlPullParserFactory = XmlPullParserFactory.newInstance();
//获取一个解析实例
XmlPullParser parser = xmlPullParserFactory.newPullParser();
//设置数据源,采用utf-8编码
parser.setInput(is, "utf-8");
int eventType = parser.getEventType();
//解析未完成
while(XmlPullParser.END_DOCUMENT!=eventType){
switch (eventType) {
//刚开始解析
case XmlPullParser.START_DOCUMENT:
orm = new Orm();
break;
case XmlPullParser.START_TAG:
//如果根节点未Orm
if(parser.getName().equals("Orm")){
orm.setTableName(parser.getAttributeValue(null, "tableName"));
orm.setBeanName(parser.getAttributeValue(null, "beanName"));
}
//如果根节点未key
else if(parser.getName().equals("Key")){
Key key = new Key();
key.setColumn(parser.getAttributeValue(null, "column"));
key.setProperty(parser.getAttributeValue(null, "property"));
key.setType(parser.getAttributeValue(null, "type"));
key.setIdentity(Boolean.getBoolean(parser.getAttributeValue(null, "identity")));
orm.setKey(key);
}
//如果根节点未item
else if(parser.getName().equals("item")){
Item item = new Item();
item.setColumn(parser.getAttributeValue(null, "column"));
item.setProperty(parser.getAttributeValue(null, "property"));
item.setType(parser.getAttributeValue(null, "type"));
orm.getItems().add(item);
}
break;
case XmlPullParser.END_TAG:
break;
default:
break;
}
eventType = parser.next();
}
return orm;
}
} 啊啊啊!!这显示格式有问题,我就不调了,具体看后面的源代码把,
好了我们解析xml文件已经完成了,并且已经获得了Orm对象咯,离成功好近咯。
接下来我们写我们的Dao层把, 这层才是最要的啊?大家吃个冰淇淋放松一下,在dao包下新建一个BaseDao泛型类,BaseDao中提供插入与查询方法,查找与修改我这就不写咯。
public class BaseDao {
private MySqliteOpenHelper mySqliteOpenHelper;
public BaseDao(MySqliteOpenHelper mySqliteOpenHelper) {
super();
this.mySqliteOpenHelper = mySqliteOpenHelper;
}
//插入
public void insert(T t){
}
//查询所有
public List queryAll(){
}
}
其中T是泛型,之前说过,这里泛指数据表对应的值对象哈。
数据库插入语句db.insert(table,null, values)
意味着我们只要知道表名和得到values就可以插入了。
下面来看我怎么实现的,先看代码吧。
//插入数据
public long insert(T t) throws Exception{
SQLiteDatabase db = mySqliteOpenHelper.getWritableDatabase();
//获取Orm对象
Orm orm = TemplateConfig.mapping.get(t.getClass().getSimpleName()+".orm.xml");
ContentValues values = new ContentValues();
Class cls = t.getClass();
if(!orm.getKey().isIdentity()){
//反射开始咯 得到值对象的Class实例
//反射获取值对象orm.getKey().getProperty()的值
Field field = cls.getDeclaredField(orm.getKey().getProperty());
//打破权限
field.setAccessible(true);
//获取到要插入值
Object value = field.get(t);
//反射获取ContentValues中的方法
Method method = values.getClass().getDeclaredMethod("put", Class.forName(orm.getKey().getType()));
//调用put方法相当于values.put(String,Object),
method.invoke(values,new Object[]{orm.getKey().getColumn(),value});
}
for (Item item : orm.getItems()) {
//反射开始咯,获取item字段的值
Field field = cls.getDeclaredField(item.getProperty());
//打破权限
field.setAccessible(true);
//反射获取值
Object value = field.get(t);
//反射获取ContentValues中的方法
Method method = values.getClass().getDeclaredMethod("put", Class.forName(orm.getKey().getType()));
//调用put方法相当于values.put(String,Object),
method.invoke(values,new Object[]{item.getColumn(),value});
}
long result = db.insert(orm.getTableName(), null, values);
return result;
}注释已经写得挺详细了,我就不多说了。上面的插入数据的功能就实现咯,接下来我们在实现以下queryAll把,看代码
public List queryAll(T t) throws Exception{
//定义一个集合
List mList = new ArrayList();
SQLiteDatabase db = mySqliteOpenHelper.getReadableDatabase();
//获取orm对象
Orm orm = TemplateConfig.mapping.get(t.getClass().getSimpleName().toLowerCase()+".orm.xml");
//查询
Cursor cursor = db.query(orm.getTableName(), null, null,null,null,null,null);
//获取cursor实例
Class cls = cursor.getClass();
//获取值对象Class实例
Class cls2 = t.getClass();
while(cursor.moveToNext()){
//获取值对象实例
t= (T) cls2.newInstance();
int index= cursor.getColumnIndex(orm.getKey().getColumn());
//反射开始获取cursor中的cursor.getString(int index)或者cursor.getInt(int index)方法
Method method = cls.getMethod(TemplateConfig.methodMappings.get(orm.getKey().getType()), int.class);
//反射获得property对应值对象中的字段的值
Field field = cls2.getDeclaredField(orm.getKey().getProperty());
//打破权限
field.setAccessible(true);
//反射调用给上面获得的字段赋值
field.set(t, method.invoke(cursor,index));
for (Item item : orm.getItems()) {
//请对比之前小马写的,你就知道为什么要这么写咯
index =cursor.getColumnIndex(item.getColumn());
method=cls.getMethod(TemplateConfig.methodMappings.get(item.getType()), int.class);
field = cls2.getDeclaredField(item.getProperty());
field.setAccessible(true);
field.set(t, method.invoke(cursor,index));
}
mList.add(t);
}
return mList; 我来总结一下,要查询所有数据,常规的调用db.query(表名, 显示的列, 条件, 条件对象, 分组统计, having, 排序),表名orm对象里面已经有了,查询获得一个Cursor对象,一般我们会采用小马的那份代码将Cursor转化成集合,但是考虑不能把代码写死,不能写死意味着cursor中的get方法不能写死咯,所以我们只能通过反射,去动态加载调用方法咯。动态的选择调用cursor.getInt()还是cursor.getString().这就是为什么一定要这样写咯。是不是有点复杂有点晕啊?晕是正常的,我也晕过好几次,这就是为什么只有十万分之一的人才能当上架构师的原因。
好了,我们继续前进,现在回到主界面来。
@Override
protected void onCreate(Bundle savedInstanceState) {
// TODO Auto-generated method stub
super.onCreate(savedInstanceState);
setContentView(R.layout.main);
//初始化content对象
content = MainActivity.this;
init();
}
private void init() {
// TODO Auto-generated method stub
lv = (ListView) findViewById(R.id.lv);
name = (EditText) findViewById(R.id.name);
age = (EditText) findViewById(R.id.age);
tableName = (EditText) findViewById(R.id.tablename);
try {
//获取Assets目录下所有文件名
String[] files = getAssets().list("");
for (String string : files) {
//以.orm.xml结尾的是我们定义的xml
if(string.endsWith(".orm.xml")){
//解析xml文件
Orm orm = TemplateConfig.parser(getAssets().open(string));
//将xml文件放入Mapping中
TemplateConfig.mapping.put(orm.getTableName()+".orm.xml",orm);
}
}
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public void insert(View view) throws Exception{
//判断表名是否为空
if(tableName.getText()==null&&TextUtils.equals(tableName.getText().toString(),"")){
Toast.makeText(this, "No find mapping file1", Toast.LENGTH_LONG).show();
}
else{
//获取表名所对应的orm对象
Orm orm = TemplateConfig.mapping.get(tableName.getText().toString().trim()+".orm.xml");
if(orm!=null){
//获取值对象Class实例
Class cls = Class.forName(orm.getBeanName());
//获取值对象实例
Object object = cls.newInstance();
for (Item item : orm.getItems()) {
/*对值对象属性赋值*/
Field field = cls.getDeclaredField(item.getProperty());
field.setAccessible(true);
field.set(object, name.getText().toString().trim());
}
/*插入到数据库中去*/
Method method = baseDao.getClass().getMethod("insert", new Class[]{Object.class});
method.invoke(baseDao, object);
}
else{
Toast.makeText(this, "No find mapping file2", Toast.LENGTH_LONG).show();
}
}
}
@SuppressWarnings("unchecked")
public void query(View view) throws Exception{
//获取tableName所对应的Orm对象
Orm orm = TemplateConfig.mapping.get(tableName.getText().toString().trim()+".orm.xml");
if(orm!=null){
//获取值对象的Class实例
Class cls = Class.forName(orm.getBeanName());
//获取值对象实例
Object object = cls.newInstance();
for (Item item : orm.getItems()) {
//设置值对象属性对应的值
Field field = cls.getDeclaredField(item.getProperty());
field.setAccessible(true);
field.set(object, name.getText().toString().trim());
}
//反射获取方法
Method method = baseDao.getClass().getMethod("queryAll", Object.class);
//调用baseDao里面的queryAll方法
List mList = (List) method.invoke(baseDao, object);
ArrayAdapter adapter = new ArrayAdapter(this, android.R.layout.simple_list_item_1, mList);
lv.setAdapter(adapter);
}
else{
Toast.makeText(this, "No find mapping file", Toast.LENGTH_LONG).show();
}
}
Test结果
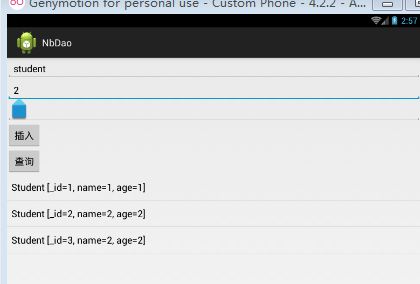
全部的代码都写完咯,注释非常清楚咯,我们在流程图的方式来理清一下思路吧!!
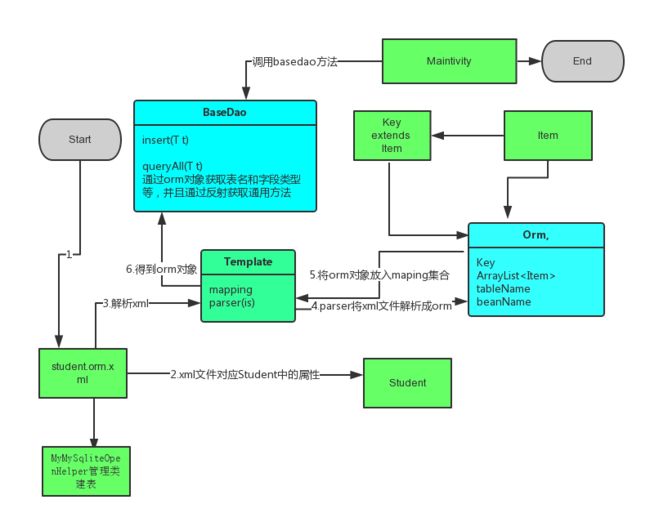
现在再也不用重复的写数据的操作咯,增加一个表的操作,只需2步就可以搞定,而且不用改之前的代码。
1.新建一个xml文件
2.新建一个xml文件对应的值对象
就这两步,我的代码中扩展了一个Product表,有兴趣的去看看吧。
属于我们自己的dao到此结束了,虽然比不过现在安卓中流行的GreenDao以及OrmLite(采用注解式)这两种框架,但是基本的思想大致相同,工作一天,累了,下次在专门写一篇关于GreenDao和OrmLite使用细节供大家参考吧!!
源代码下载地址 http://download.csdn.net/detail/qq_29282475/9389979