聚类算法的改进——DBSCAN
聚类算法的改进——DBSCAN
K-means算法有几个明显的缺点,例如需要用户指定聚类数目,而且聚类的形状比较有局限性。
这里考虑采用DBSCAN(Density - Based Spatial Clustering of Applications with Noise)
该算法将具有足够高密度的区域划分为簇,并可以发现任何形状的聚类
DBSCAN和K-Means的比较:
1、 DBSCAN和K-Means的比较:
2、DBSCAN不需要输入聚类个数
3、聚类簇的形状没有要求
4、可以在需要时输入过滤噪声的参数
from sklearn.cluster import DBSCAN
载入数据后,训练模型、预测、可视化
# eps距离阈值,min_sample核心对象在eps领域的样本数阈值
model = DBSCAN(eps = 1.5,min_samples=4)
model.fit(data)
result = model.fit_predict(data)
print(result)
mark = ['or', 'ob', 'og', 'oy', 'ok', 'om']
for i, d in enumerate(data):
plt.plot(d[0], d[1], mark[result[i]])
plt.show()
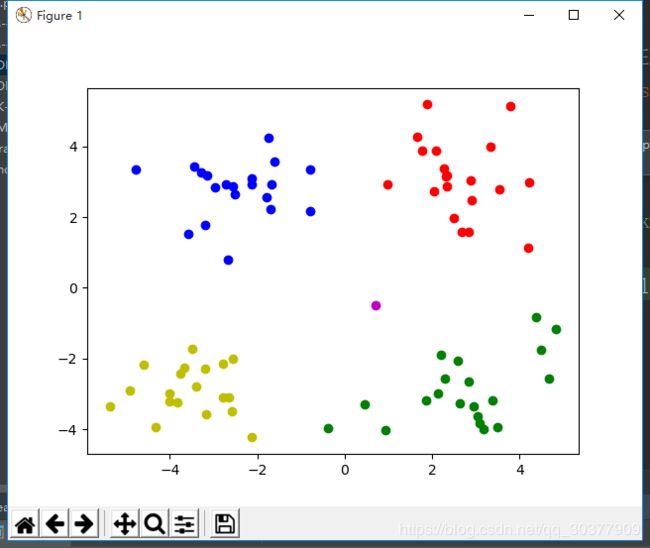
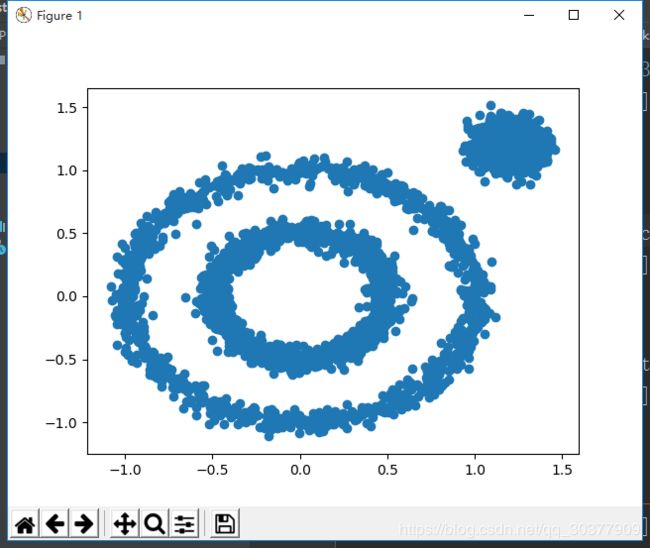
接下来看一看另外的形状的聚类,这次用代码生成的数据集。
x1, y1 = datasets.make_circles(n_samples=2000, factor=0.5, noise=0.05)
x2, y2 = datasets.make_blobs(n_samples=1000, centers=[[1.2, 1.2]], cluster_std=[[.1]])
x = np.concatenate((x1, x2))
plt.scatter(x[:, 0], x[:, 1], marker='o')
plt.show()
KMeans的效果:
from sklearn.cluster import KMeans
y_pred = KMeans(n_clusters=3).fit_predict(x)
plt.scatter(x[:, 0], x[:, 1], c=y_pred)
plt.show()
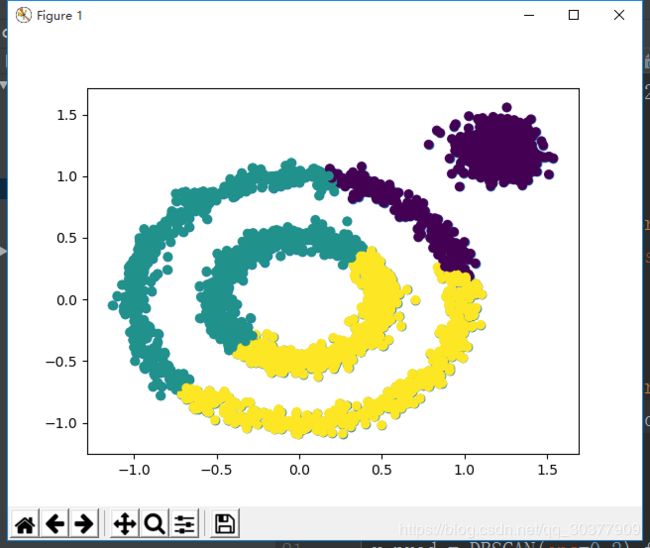
很莫名其妙的分类
默认的DBSCAN
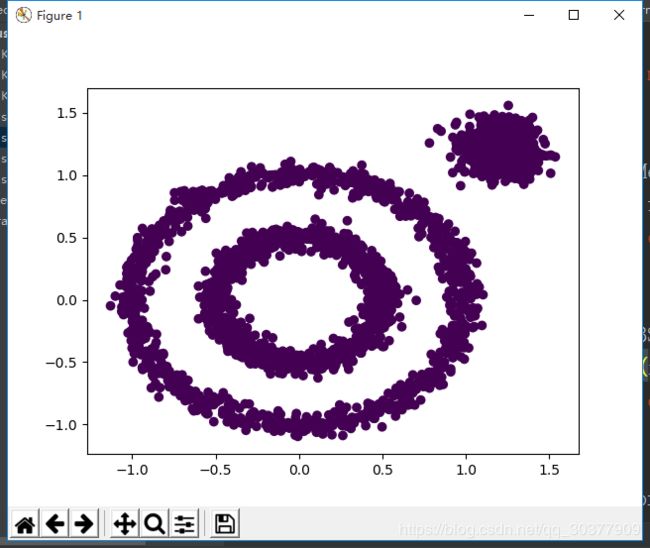
将所有数据都分为了同一类
给DBSCAN设置相应的参数eps
y_pred = DBSCAN(eps=0.2).fit_predict(x)
plt.scatter(x[:, 0], x[:, 1], c=y_pred)
plt.show()
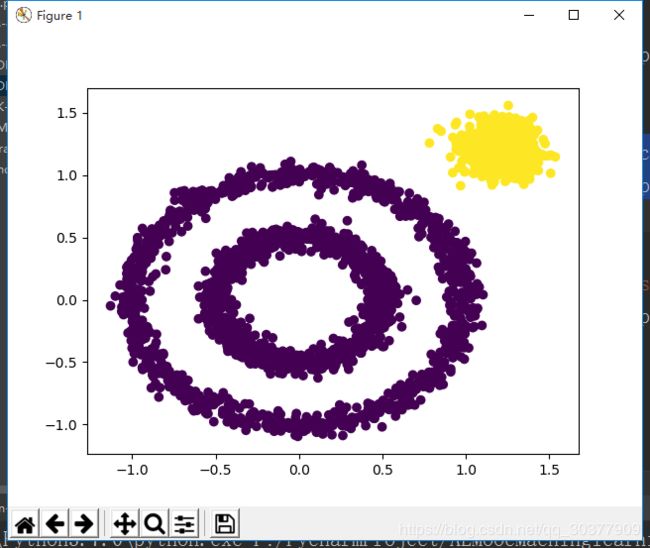
效果有提升,至少是把右上角分出来了,但是中间的两个环似乎分成两类更合理
于是尝试设置min_samples参数
y_pred = DBSCAN(eps=0.2,min_samples=50).fit_predict(x)
plt.scatter(x[:, 0], x[:, 1], c=y_pred)
plt.show()
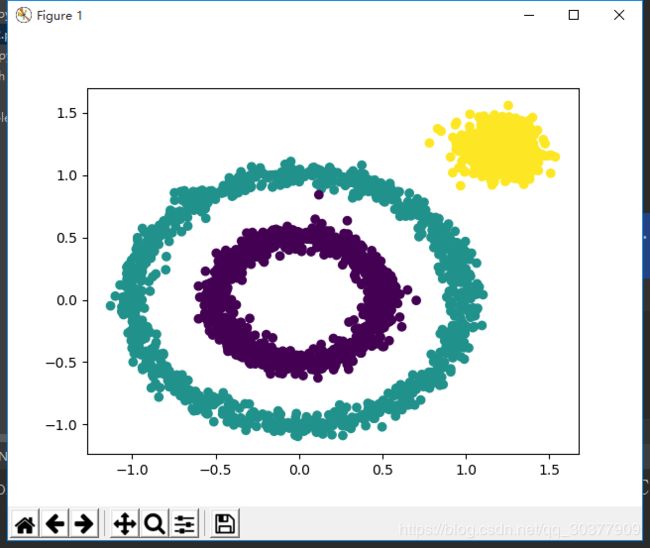
这样总算获得一个较为合理的结果。