happens-before,内存重排序,数据依赖的理解
在JMM(Java内存模型)中,如果一个操作执行的结果需要对另一个操作可见,那么这两个操作之间必须存在happens-before关系。
happens-before原则规则:
- 程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作;
- 锁定规则:一个unLock操作先行发生于后面对同一个锁的lock操作;
- volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作;
- 传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C;
- 线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作;
- 线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生;
- 线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行;
- 对象终结规则:一个对象的初始化完成先行发生于他的finalize()方法的开始;
我们来详细看看上面每条规则(摘自《深入理解Java虚拟机第12章》):
程序次序规则:一段代码在单线程中执行的结果是有序的。注意是执行结果,因为虚拟机、处理器会对指令进行重排序(重排序后面会详细介绍)。虽然重排序了,但是并不会影响程序的执行结果,所以程序最终执行的结果与顺序执行的结果是一致的。故而这个规则只对单线程有效,在多线程环境下无法保证正确性。
锁定规则:这个规则比较好理解,无论是在单线程环境还是多线程环境,一个锁处于被锁定状态,那么必须先执行unlock操作后面才能进行lock操作。
volatile变量规则:这是一条比较重要的规则,它标志着volatile保证了线程可见性。通俗点讲就是如果一个线程先去写一个volatile变量,然后一个线程去读这个变量,那么这个写操作一定是happens-before读操作的。
传递规则:提现了happens-before原则具有传递性,即A happens-before B , B happens-before C,那么A happens-before C
线程启动规则:假定线程A在执行过程中,通过执行ThreadB.start()来启动线程B,那么线程A对共享变量的修改在接下来线程B开始执行后确保对线程B可见。
线程终结规则:假定线程A在执行的过程中,通过制定ThreadB.join()等待线程B终止,那么线程B在终止之前对共享变量的修改在线程A等待返回后可见。
上面八条是原生Java满足Happens-before关系的规则,但是我们可以对他们进行推导出其他满足happens-before的规则:
- 将一个元素放入一个线程安全的队列的操作Happens-Before从队列中取出这个元素的操作
- 将一个元素放入一个线程安全容器的操作Happens-Before从容器中取出这个元素的操作
- 在CountDownLatch上的倒数操作Happens-Before CountDownLatch#await()操作
- 释放Semaphore许可的操作Happens-Before获得许可操作
- Future表示的任务的所有操作Happens-Before Future#get()操作
- 向Executor提交一个Runnable或Callable的操作Happens-Before任务开始执行操作
这里再说一遍happens-before的概念:如果两个操作不存在上述(前面8条 + 后面6条)任一一个happens-before规则,那么这两个操作就没有顺序的保障,JVM可以对这两个操作进行重排序。如果操作A happens-before操作B,那么操作A在内存上所做的操作对操作B都是可见的。
上面的程序次序原则,和重排序之间一直有一个疑惑,看下面的代码:
//线程A:
context = loadContext();
inited = true;
//线程B:
while(!inited ){
sleep
}
doSomethingwithconfig(context);线程A中的操作可能会重排序,导致线程B中的context初始化不完全。但是,为什么线程A的操作会重排序呢?根据happens-before的程序次序原则,context的初始化不是应该在inited前面吗?直到我看到了这样的解释:
1. 如果一个操作happens-before另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前。
2. 两个操作之间存在happens-before关系,并不意味着一定要按照happens-before原则制定的顺序来执行。如果重排序之后的执行结果与按照happens-before关系来执行的结果一致,那么这种重排序并不非法。
第二条中描述了,如果重排序的执行结果,和按照happens-before关系执行的结果一致,那么重排序并不非法。所以就解释了为什么线程1中会重排序了:线程1中的两个操作没有关联关系,就是执行结果互不依赖。按照happens-before的关系执行,context先初始化,inited后初始化。按照重排序的顺序执行,inited先初始化,context后初始化。最终的结果都是一样的:两个变量的初始化。所以,重排序不非法。这也解释了,为什么程序次序规则在多线程下,两个操作之间无关系的情况下,操作有可能会被重排序的原因了。
另一方面,如果两个操作之间存在关联关系,为了保证程序的执行结果不会改变,需要遵循as-if-serial语义。即:编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果。但是,如果操作之间不存在数据依赖关系,这些操作就可能被编译器和处理器重排序
数据依赖性定义:
如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间就存在数据依赖性
数据依赖分为下列3种类型,如表所示:

double pi = 3.14; // A
double r = 1.0; // B
double area = pi * r * r; // C操作A和C之间有数据依赖性,B和C之间也存在数据依赖性,所以C不能在A和B之前执行。但是,A和B之间没有数据依赖性,所以A和B之间可能会被重排序。
控制依赖性定义:
考察下面的代码,线程1运行writer,线程2运行reader:
class ReorderExample {
int a = 0;
boolean flag = false;
public void writer() {
a = 1; // 1
flag = true; // 2
}
Public void reader() {
if (flag) { // 3
int i = a * a; // 4
……
}
}
}我们知道,操作1和2直接没有数据依赖性,可能会被重排序,导致程序异常。那么,3和4之间会重排序吗?答案是会的。这里有个新的概念——控制依赖性。操作3和操作4存在控制依赖关系。当代码中存在控制依赖性时,会影响指令序列执行的并行度。为此,编译器和处理器会采用猜测(Speculation)执行来克服控制相关性对并行度的影响。以处理器的猜测执行为例,执行线程B的处理器可以提前读取并计算a*a,然后把计算结果临时保存到一个名为重排序缓冲(Reorder Buffer,ROB)的硬件缓存中。当操作3的条件判断为真时,就把该计算结果写入变量i中。
从图中我们可以看出,猜测执行实质上对操作3和4做了重排序。重排序在这里破坏了多线程程序的语义!
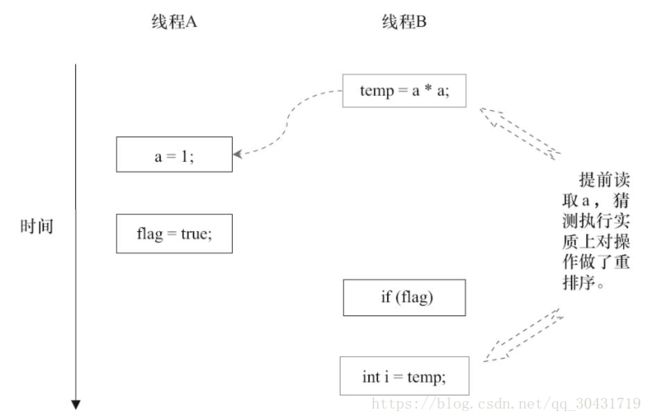
在单线程程序中,对存在控制依赖的操作重排序,不会改变执行结果(这也是as-if-serial语义允许对存在控制依赖的操作做重排序的原因);但在多线程程序中,对存在控制依赖的操作重排序,可能会改变程序的执行结果。
参考:【死磕Java并发】—–Java内存模型之happens-before