第三章 JVM垃圾回收机制与收集器
垃圾机制
引用计数法
定义:
一个对象应用了就对他加1,释放就减1.
过程
通过可达性分析。
分析存在的问题
1、性能问题: 大量的计算
2、导致对象无法被回收(循环引用的问题)。
标记清除算法
定义
标记阶段和清除阶段,通过可达性分析
过程
可达性分析
分析存在的问题
会产生碎片空间。
标记压缩
定义
先标志存活对象,然后在压缩。
过程
可达性分析 主要应用在老年代
分析存在的问题
同上。
复制算法
定义
将存活的对象复制到内存的另外一端,然后释放之前的对象的内存空间。
分代
定义
新生代与老年代
使用的算法
新生代:复制
老年代:标记–压缩
前面一直说到可达性分析
根
- 栈中的对象
- 方法区中静态成员变量或者常量引用对象
- JNI方法栈中得以引用
Stop The World
-
出现Java中一种暂停现象
-全局停顿。 所有的Java代码停止运行。native代码可以运行,不能与JVM交互 -
多半由 GC 引起,也可能由以下操作引起
Dump 线程
堆 Dump
死搀检查
出现的原因:
垃圾不断生产,只有停止产生垃圾,才能清除干净
收集器
新生代垃圾收集器
串行收集器(Serial )单线程

参数设置
-XX:+UseSerialGC
此时,新生代、老年代使用串行回收
新生代使用复制算法
优缺点
- 稳定
- 效率较高
- 停顿
- 只开启一条 GC 线程进行垃圾回收,并且在垃圾收集过程中停止一切用户线程(Stop The World)
使用场景
一般客户端应用所需内存较小,不会创建太多对象,而且堆内存不大,因此垃圾收集器回收时间短,即使在这段时间停止一切用户线程,也不会感觉明显卡顿。因此 Serial 垃圾收集器适合客户端使用。
由于 Serial 收集器只使用一条 GC 线程,避免了线程切换的开销,从而简单高效
并行收集器(ParNew)
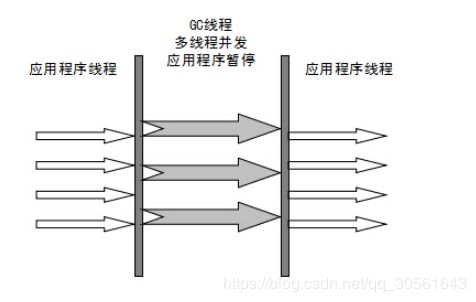
ParNew 是 Serial 的多线程版本。由多条 GC 线程并行地进行垃圾清理。但清理过程依然需要 Stop The World
ParNew 追求“低停顿时间”,与 Serial 唯一区别就是使用了多线程进行垃圾收集,在多 CPU 环境下性能比 Serial 会有一定程度的提升;但线程切换需要额外的开销,因此在单 CPU 环境中表现不如 Serial。
# 参数设置
-XX:+UseParNewGC
新生代并行、老年代串行
优缺点
- 多线程,需要多核支持
- 复制算法
Parallel Scavenge 垃圾收集器(多线程)
Parallel Scavenge 和 ParNew 一样,都是多线程、新生代垃圾收集器。但是两者有巨大的不同点:
- Parallel Scavenge:追求 CPU 吞吐量,能够在较短时间内完成指定任务,因此适合没有交互的后台计算。
- ParNew:追求降低用户停顿时间,适合交互式应用。
吞吐量 = 运行用户代码时间 / (运行用户代码时间 + 垃圾收集时间)
追求高吞吐量,可以通过减少 GC 执行实际工作的时间,然而,仅仅偶尔运行 GC 意味着每当 GC 运行时将有许多工作要做,因为在此期间积累在堆中的对象数量很高。单个 GC 需要花更多的时间来完成,从而导致更高的暂停时间。而考虑到低暂停时间,最好频繁运行 GC 以便更快速完成,反过来又导致吞吐量下降
参数设置
- 通过参数 -XX:GCTimeRadio 设置垃圾回收时间占总 CPU 时间的百分比。
- 通过参数 -XX:MaxGCPauseMillis 设置垃圾处理过程最久停顿时间。
- 通过命令 -XX:+UseAdaptiveSizePolicy 开启自适应策略。我们只要设置好堆的大小和 MaxGCPauseMillis 或 GCTimeRadio,收集器会自动调整新生代的大小、Eden 和 Survivor 的比例、对象进入老年代的年龄,以最大程度上接近我们设置的 MaxGCPauseMillis 或 GCTimeRadio。
老年代垃圾收集器
Serial Old 垃圾收集器(单线程)
Serial Old 收集器是 Serial 的老年代版本,都是单线程收集器,只启用一条 GC 线程,都适合客户端应用。它们唯一的区别就是:Serial Old 工作在老年代,使用“标记-整理”算法;Serial 工作在新生代,使用“复制”算法
Parallel Old 垃圾收集器(多线程)
Parallel Old 收集器是 Parallel Scavenge 的老年代版本,追求 CPU 吞吐量。
CMS 垃圾收集器
CMS(Concurrent Mark Sweep,并发标记清除)收集器是以获取最短回收停顿时间为目标的收集器(追求低停顿),它在垃圾收集时使得用户线程和 GC 线程并发执行,因此在垃圾收集过程中用户也不会感到明显的卡顿。
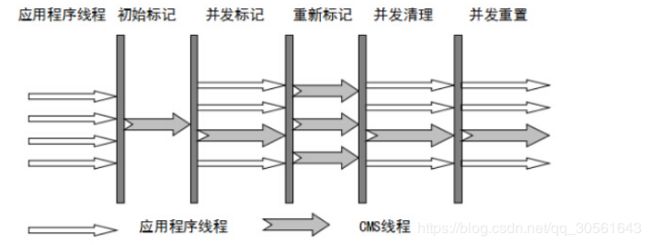
回收阶段:
初始标记:Stop The World,仅使用一条初始标记线程对所有与 GC Roots 直接关联的对象进行标记。
并发标记:使用多条标记线程,与用户线程并发执行。此过程进行可达性分析,标记出所有废弃对象。速度很慢。
重新标记:Stop The World,使用多条标记线程并发执行,将刚才并发标记过程中新出现的废弃对象标记出来。
并发清除:只使用一条 GC 线程,与用户线程并发执行,清除刚才标记的对象。这个过程非常耗时。
并发标记与并发清除过程耗时最长,且可以与用户线程一起工作,因此,总体上说,CMS 收集器的内存回收过程是与用户线程一起并发执行的。
CMS 的缺点:
- 吞吐量低
- 无法处理浮动垃圾,导致频繁 Full GC
- 使用“标记-清除”算法产生碎片空间
参数设置
对于产生碎片空间的问题,可以通过开启 -XX:+UseCMSCompactAtFullCollection,在每次 Full GC 完成后都会进行一次内存压缩整理,将零散在各处的对象整理到一块。设置参数 -XX:CMSFullGCsBeforeCompaction告诉 CMS,经过了 N 次 Full GC 之后再进行一次内存整理。
G1 通用垃圾收集器 (服务端)
G1 是一款面向服务端应用的垃圾收集器,它没有新生代和老年代的概念,而是将堆划分为一块块独立的 Region。当要进行垃圾收集时,首先估计每个 Region 中垃圾的数量,每次都从垃圾回收价值最大的 Region 开始回收,因此可以获得最大的回收效率。
从整体上看, G1 是基于“标记-整理”算法实现的收集器,从局部(两个 Region 之间)上看是基于“复制”算法实现的,这意味着运行期间不会产生内存空间碎片。
这里抛个问题point_down
一个对象和它内部所引用的对象可能不在同一个 Region 中,那么当垃圾回收时,是否需要扫描整个堆内存才能完整地进行一次可达性分析?
并不!每个 Region 都有一个 Remembered Set,用于记录本区域中所有对象引用的对象所在的区域,进行可达性分析时,只要在 GC Roots 中再加上 Remembered Set 即可防止对整个堆内存进行遍历。
如果不计算维护 Remembered Set 的操作,G1 收集器的工作过程分为以下几个步骤:
初始标记:Stop The World,仅使用一条初始标记线程对所有与 GC Roots 直接关联的对象进行标记。
并发标记:使用一条标记线程与用户线程并发执行。此过程进行可达性分析,速度很慢。
最终标记:Stop The World,使用多条标记线程并发执行。
筛选回收:回收废弃对象,此时也要 Stop The World,并使用多条筛选回收线程并发执行。