STL标准库六大组件 关系 作用
STL六大组件简介
1、容器(Containers):各种数据结构,如Vector,List,Deque,Set,Map,用来存放数据,STL容器是一种Class Template,就体积而言,这一部分很像冰山载海面的比率。
2、算法(Algorithms):各种常用算法如Sort,Search,Copy,Erase,从实现的角度来看,STL算法是一种Function Templates。
3、迭代器(Iterators):扮演容器与算法之间的胶合剂,是所谓的“泛型指针”,共有五种类型,以及其它衍生变化,从实现的角度来看,迭代器是一种将:Operators*,Operator->,Operator++,Operator--等相关操作予以重载的Class Template。所有STL容器都附带有自己专属的迭代器——是的,只有容器设计者才知道如何遍历自己的元素,原生指针(Native pointer)也是一种迭代器。
4、仿函数(Functors): 行为类似函数,可作为算法的某种策略(Policy),从实现的角度来看,仿函数是一种重载了Operator()的Class 或 Class Template。一般函数指针可视为狭义的仿函数。
5、配接器(适配器)(Adapters):一种用来修饰容器(Containers)或仿函数(Functors)或迭代器(Iterators)接口的东西,例如:STL提供的Queue和Stack,虽然看似容器,其实只能算是一种容器配接器,因为 它们的底部完全借助Deque,所有操作有底层的Deque供应。改变Functor接口者,称为Function Adapter;改变Container接口者,称为Container Adapter;改变Iterator接口者,称为Iterator Adapter。配接器的实现技术很难一言蔽之,必须逐一分析。
6、分配器(Allocators):负责空间配置与管理,从实现的角度来看,配置器是一个实现了动态空间配置、空间管理、空间释放的Class Template。
——《STL源码剖析》
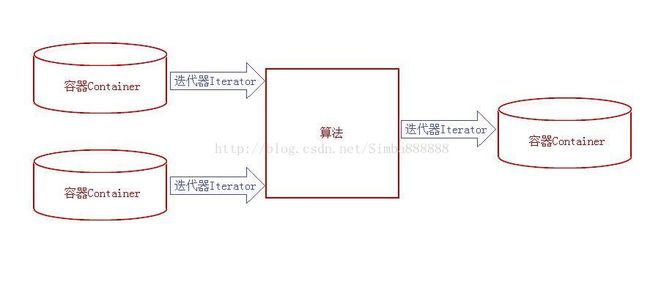
这六大组件的交互关系:container(容器) 通过 allocator(配置器) 取得数据储存空间,algorithm(算法)通过 iterator(迭代器)存取 container(容器) 内容,functor(仿函数) 可以协助 algorithm(算法) 完成不同的策略变化,adapter(配接器) 可以修饰或套接 functor(仿函数)。
一、STL简介
(一)、泛型程序设计
泛型编程(generic programming)
将程序写得尽可能通用
将算法从数据结构中抽象出来,成为通用的
C++的模板为泛型程序设计奠定了关键的基础
(二)、什么是STL
1、STL(Standard Template Library),即标准模板库,是一个高效的C++程序库。
2、包含了诸多在计算机科学领域里常用的基本数据结构和基本算法。为广大C++程序员们提供了一个可扩展的应用框架,高度体现了软件的可复用性
3、从逻辑层次来看,在STL中体现了泛型化程序设计的思想(generic programming)
在这种思想里,大部分基本算法被抽象,被泛化,独立于与之对应的数据结构,用于以相同或相近的方式处理各种不同情形。
4、从实现层次看,整个STL是以一种类型参数化(type parameterized)的方式实现的
基于模板(template)
二、STL组件
Container(容器) 各种基本数据结构
Adapter(适配器) 可改变containers、Iterators或Function object接口的一种组件
Algorithm(算法) 各种基本算法如sort、search…等
Iterator(迭代器) 连接containers和algorithms
Function object(函数对象)
Allocator(分配器)
(一)、容器
容器类是容纳、包含一组元素或元素集合的对象
七种基本容器:
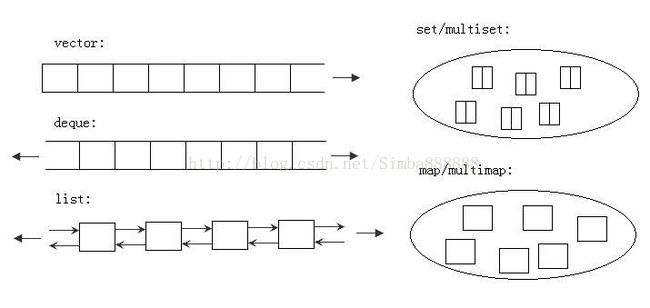
向量(vector)、双端队列(deque)、列表(list)、集合(set)、多重集合(multiset)、映射(map)和多重映射(multimap)
标准容器的成员绝大部分都具有共同的名称
序列式容器
序列式容器Sequence containers,其中每个元素均有固定位置——取决于插入时机和地点,和元素值无关。(vector、deque、list)
关联式容器
关联式容器Associative containers,元素位置取决于特定的排序准则以及元素值,和插入次序无关。(set、multiset、map、multimap)
1、需要频繁在序列中间位置上进行插入和/或删除操作且不需要过多地在序列内部进行长距离跳转,应该选择list
2、vector头部与中间插入删除效率较低,在尾部插入与删除效率高。
3、deque是在头部与尾部插入与删除效率较高
set/map/multiset/multimap
set,同map一样,所有元素都会根据元素的键值自动被排序,因为set/map两者的所有各种操作,都只是转而调用RB-tree的操作行为,不过,值得注意的是,两者都不允许两个元素有相同的键值。
不同的是:set的元素不像map那样可以同时拥有实值(value)和键值(key),set元素同时拥有实值和键值,且实值就是键值,键值就是实值,而map的所有元素都是pair,同时拥有实值(value)和键值(key),pair的第一个元素被视为键值,第二个元素被视为实值。
至于multiset/multimap,他们的特性及用法和set/map完全相同,唯一的差别就在于它们允许键值重复,即所有的插入操作基于RB-tree的insert_equal()而非insert_unique()。In computer science, a multimap (sometimes also multihash) is a generalization of a map or associative array
abstract data type in which more than one value may be associated with and returned for a given key.
摘自 sgi stl 红黑树数据结构定义:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
typedef
bool _Rb_tree_Color_type;
const _Rb_tree_Color_type _S_rb_tree_red = false; const _Rb_tree_Color_type _S_rb_tree_black = true; struct _Rb_tree_node_base { typedef _Rb_tree_Color_type _Color_type; typedef _Rb_tree_node_base* _Base_ptr; _Color_type _M_color; _Base_ptr _M_parent; _Base_ptr _M_left; _Base_ptr _M_right; static _Base_ptr _S_minimum(_Base_ptr __x) { while (__x->_M_left != 0) __x = __x->_M_left; return __x; } static _Base_ptr _S_maximum(_Base_ptr __x) { while (__x->_M_right != 0) __x = __x->_M_right; return __x; } }; template < class _Value> struct _Rb_tree_node : public _Rb_tree_node_base { typedef _Rb_tree_node<_Value>* _Link_type; _Value _M_value_field; }; |
hash_set/hash_map/hash_multiset/hash_multimap
hash_set/hash_map,两者的一切操作都是基于hashtable之上。不同的是,hash_set同set一样,同时拥有实值和键值,且实值就是键值,键值就是实值,而hash_map同map一样,每一个元素同时拥有一个实值(value)和一个键值(key),所以其使用方式,和上面的map基本相同。但由于hash_set/hash_map都是基于hashtable之上,所以不具备自动排序功能。为什么? 因为hashtable没有自动排序功能。
至于hash_multiset/hash_multimap的特性与上面的multiset/multimap完全相同,唯一的差别就是它们hash_multiset/hash_multimap的底层实现机制是hashtable(而multiset/multimap,上面说了,底层实现机制是RB-tree),所以它们的元素都不会被自动排序,不过也都允许键值重复。
所以说白了,什么样的结构决定其什么样的性质,因为set/map/multiset/multimap都是基于RB-tree之上,所以有自动排序功能,而hash_set/hash_map/hash_multiset/hash_multimap都是基于hashtable之上,所以不含有自动排序功能,至于加个前缀multi_无非就是允许键值重复而已。
std::tr1::unordered_map 是无序哈希表,但操作效率要比 std::map、std::hash_map、 __gnu_cxx::hash_map 都要高,可以研究一下。
(二)、迭代器
1、迭代器Iterators,用来在一个对象群集(collection of objects)的元素上进行遍历。这个对象群集或许是个容器,或许是容器的一部分。迭代器的主要好处是,为所有容器提供了一组很小的公共接口。迭代器以++进行累进,以*进行提领,因而它类似于指针,我们可以把它视为一种smart pointer
2、比如++操作可以遍历至群集内的下一个元素。至于如何做到,取决于容器内部的数据组织形式。
3、每种容器都提供了自己的迭代器,而这些迭代器能够了解容器内部的数据结构。
(三)、算法
算法Algorithms,用来处理群集内的元素。它们可以出于不同的目的而搜寻、排序、修改、使用那些元素。通过迭代器的协助,我们可以只需编写一次算法,就可以将它应用于任意容器,这是因为所有的容器迭代器都提供一致的接口。
(四)、适配器
1、适配器是一种接口类
为已有的类提供新的接口
目的是简化、约束、使之安全、隐藏或者改变被修改类提供的服务集合
2、三种类型的适配器:
容器适配器:用来扩展7种基本容器,它们和顺序容器相结合构成栈、队列和优先队列容器
迭代器适配器(反向迭代器、插入迭代器、IO流迭代器)
函数适配器(函数对象适配器、成员函数适配器、普通函数适配器)
(五)、函数对象
1、函数对象(function object)也称为仿函数(functor)
2、一个行为类似函数的对象,它可以没有参数,也可以带有若干参数。
3、任何重载了调用运算符operator()的类的对象都满足函数对象的特征
4、函数对象可以把它称之为smart function。
5、STL中也定义了一些标准的函数对象,如果以功能划分,可以分为算术运算、关系运算、逻辑运算三大类。为了调用这些标准函数对象,需要包含头文件
(六)、分配器
负责空间配置与管理。从实现的角度来看,配置器是一个实现了动态空间配置、空间管理、空间释放的class template。
隐藏在这些容器后的内存管理工作是通过STL提供的一个默认的allocator实现的。当然,用户也可以定制自己的allocator,只要实现allocator模板所定义的接口方法即可,然后通过将自定义的allocator作为模板参数传递给STL容器,创建一个使用自定义allocator的STL容器对象,如:
stl::vector
大多数情况下,STL默认的allocator就已经足够了。这个allocator是一个由两级分配器构成的内存管理器,当申请的内存大小大于128byte时,就启动第一级分配器通过malloc直接向系统的堆空间分配,如果申请的内存大小小于128byte时,就启动第二级分配器,从一个预先分配好的内存池中取一块内存交付给用户,这个内存池由16个不同大小(8的倍数,8~128byte)的空闲列表组成,allocator会根据申请内存的大小(将这个大小round up成8的倍数)从对应的空闲块列表取表头块给用户。
这种做法有两个优点:
(1)小对象的快速分配。小对象是从内存池分配的,这个内存池是系统调用一次malloc分配一块足够大的区域给程序备用,当内存池耗尽时再向系统申请一块新的区域,整个过程类似于批发和零售,起先是由allocator向总经商批发一定量的货物,然后零售给用户,与每次都向总经商要一个货物再零售给用户的过程相比,显然是快捷了。当然,这里的一个问题时,内存池会带来一些内存的浪费,比如当只需分配一个小对象时,为了这个小对象可能要申请一大块的内存池,但这个浪费还是值得的,况且这种情况在实际应用中也并不多见。
(2)避免了内存碎片的生成。程序中的小对象的分配极易造成内存碎片,给操作系统的内存管理带来了很大压力,系统中碎片的增多不但会影响内存分配的速度,而且会极大地降低内存的利用率。以内存池组织小对象的内存,从系统的角度看,只是一大块内存池,看不到小对象内存的分配和释放。
参考:
C++ primer 第四版
Effective C++ 3rd
C++编程规范