EM(期望最大)算法详解(上)
EM算法(The Expectation-Maximization Algorithm)实质是对含有隐变量的概率模型参数的极大似然估计。EM算法的推导过程真的灰常容易理解,只需要一点点概率论的知识加上一点点的讲解,便可对此算法了然。
学习EM算法,只需要2个小技能(合计4个小知识点):
1. 概率分布的参数常用极大似然估计——了解极大似然估计以及她的对数形式;在一概率分布下有一组观测值: X={x1,x2,...,xn} ,极大似然估计的工作就是找到一组符合这个概率分布的参数,使得出现这些观测值的概率最大,数学表示就是:找到参数 θ , 使得 P(X|θ) 最大。为了计算简便,通常我们计算的对数似然函数:
2. 知道什么事凸函数以及凸函数的三个小知识点——
2.1) 凸函数的定义:
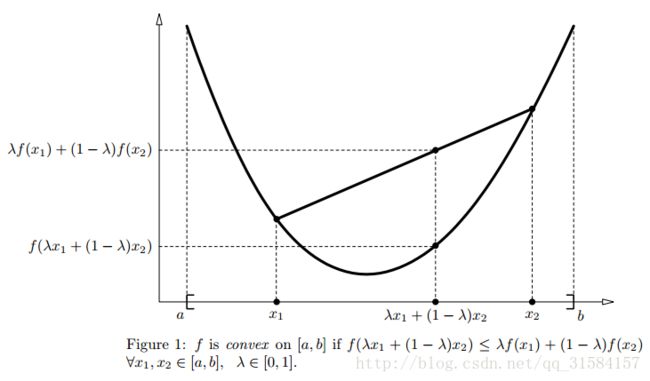
2.2) 若 f 是凹函数,则 −f 是凸函数,比如我们即将用到的 lnx ,在 x∈(0, ∞) 上,它是凹函数,显然 −lnx 是凸函数;
2.3) 詹森不等式(Jensen’s inequality)
接下来该是我们今天的主角出场了:EM算法的过程——
因为有隐变量的存在,我们无法直接令对数似然函数的导数方程等于零的方式来求参数——需要迭代去计算:
1) E-step:根据观测数据和对当前的参数估计值,去计算出隐变量的期望值;
2)M-step:根据E-step得到的隐变量的期望值去重新估计参数值,也就是进行新的一次极大似然估计
重复E & M 步骤,直至满足终止条件(参数估计值没有多大的变化)
很多时候,我们去学EM算法,最先接触到大概就是上面的定义了,往往让我们摸不着头脑,瞬间失去学习它的兴趣。别急,下面会用简单的推导去说明这一切~
怎么去理解”极大似然估计”呢?比如说当我们在 n 次估值后,得到参数估计值为 θn ,可能似然函数 L(θn) 已经比以往的都要大了,在这样的情况下我们仍然希望继续迭代的更新参数 L(θ) ,使得 L(θ) 比 θn 大,
也就是不管在什么时候,我们希望最大化这样的差异:
下面,再把隐变量 Z={z1,z2,...,zn} 考虑进来,先上一个无厘头的等式:
所以,重写等式(5)
注意到我们之前提到的 Jensen′s不等式 和 lnx 的性质,能得到这样的不等式成立
接下来的一小段推导请仔细看着,其中使用到的技巧皆是为了推导出EM形式而服务的——
将 Jensen′s不等式 应用到(9)式中,我们选用 P(Z|X,θn) (作为 λi ),部分原因是因为 ∑ZP(Z|X,θn)=1 。
于是,重写(9)式:
草版,未完待续