CS321n入门之KNN(1)——一个初学者的随学笔记
CS321n入门之KNN(1)——一个初学者的随学笔记
来源:吃树叶的土豆
视频中的第一个实例就是一个简单的KNN算法,作为小白特别是对py特性还不是很清楚的初学者。刷完视频之后再去看作业PPt的时候着实是一脸懵逼。通过几个小时的调试勉强弄明白是什么情况,同时也希望给同样是小白的初学者分享一些经验,以提高学习效率。
1、了解数据集
视频中实现KNN进行图像分类算法的数据集是:CIFAR-10。所以我们从这个数据集开始分析:
通过调试我们可以很直观的看到CIFAR-10数据集中的数据呈现状况如下:
1)batch_label: 用于标记数据集的类型,如:这里的训练集:training batch
2)label:标签,CIFAR-10是具有10种类型的图像数据库。这里的标签是指是数据集中的每张图片属于10种类型中的哪一类:“0~9”
3)data:数据,这里存的是数据集中所有图像的各个像素值。实际上是将nm二维的图像数据先转化成一位数组,由此data中的每一行则代表一张图像。图像大小为3232
4)filename:文件名,记录数据集中所有图像的文件名
如下图所示:


2、相关步骤
该算法实现的主要步骤可以分为以下:
1)数据处理:将数据集中的数据进行格式标准处理,这里通常会使用到numpy数据处理库。
2)模型建立:利用已封装好或自定义的模型进行训练,也就是class
3)评价指标:通过测试集的分类结果和测试集中已标记的label进行比较,求得该模型训练结果的有效性。由此来判断一个模型的好坏。
4)模型优化:调整超参数。在本算法中存在的超参数包括两个。其一:distance距离公式的选择,通常是曼哈顿距离和欧式距离;其二,k值的设定。
3、代码
import pickle as p
import matplotlib.pyplot as plt
import numpy as np
# NearestNeighbor class
class NearestNeighbor(object):
def __init__(self):
pass
def train(self, X, y):
""" X is N x D where each row is an example. Y is 1-dimension of size N """
# the nearest neighbor classifier simply remembers all the training data
self.Xtr = X
self.ytr = y
def predict(self, X):
""" X is N x D where each row is an example we wish to predict label for """
num_test = X.shape[0]#获取数据大小
print(num_test)
# lets make sure that the output type matches the input type
Ypred = np.zeros(num_test, dtype=self.ytr.dtype)
# loop over all test rows
for i in range(num_test):
# find the nearest training image to the i'th test image
# using the L1 distance (sum of absolute value differences)
distances = np.sum(np.sqrt(pow(self.Xtr - X[i, :],2)), axis=1)
print(distances)
min_index = np.argmin(distances) # get the index with smallest distance
Ypred[i] = self.ytr[min_index] # predict the label of the nearest example
return Ypred
def load_CIFAR_batch(filename):
""" load single batch of cifar """
#打开文件赋予权限
with open(filename, 'rb')as f:
datadict = p.load(f, encoding='latin1') #建立文件读取变量
X = datadict['data']#读取data字段
Y = datadict['labels']#读取labels字段
#print(Y)
Y = np.array(Y) # 字典里载入的Y是list类型,把它变成array类型,具体是将Y中的逗号去掉
#print(Y)
return X, Y
def load_CIFAR_Labels(filename):
with open(filename, 'rb') as f:
label_names = p.load(f, encoding='latin1')
names = label_names['label_names']
return names
# load data
label_names = load_CIFAR_Labels("cifar-10-batches-py/batches.meta")#读取数据集中数据名
imgX1, imgY1 = load_CIFAR_batch("cifar-10-batches-py/data_batch_1")
imgX2, imgY2 = load_CIFAR_batch("cifar-10-batches-py/data_batch_2")
imgX3, imgY3 = load_CIFAR_batch("cifar-10-batches-py/data_batch_3")
imgX4, imgY4 = load_CIFAR_batch("cifar-10-batches-py/data_batch_4")
imgX5, imgY5 = load_CIFAR_batch("cifar-10-batches-py/data_batch_5")#分别读取数据集中的label和data字段
Xte_rows, Yte = load_CIFAR_batch("cifar-10-batches-py/test_batch")#测试集
Xtr_rows = np.concatenate((imgX1, imgX2, imgX3, imgX4, imgX5))
print(Xtr_rows)
Ytr_rows = np.concatenate((imgY1, imgY2, imgY3, imgY4, imgY5))
print(Ytr_rows)
nn = NearestNeighbor() # create a Nearest Neighbor classifier class
nn.train(Xtr_rows[:1000, :], Ytr_rows[:1000]) # train the classifier on the training images and labels
Yte_predict = nn.predict(Xte_rows[:100, :]) # predict labels on the test images
# and now print the classification accuracy, which is the average number
# of examples that are correctly predicted (i.e. label matches)
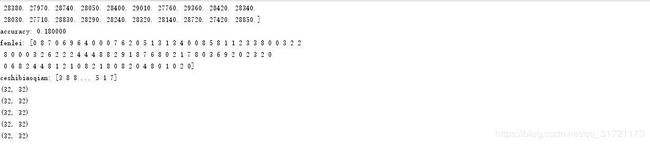
print('accuracy: %f' % (np.mean(Yte_predict == Yte[:100])))#计算准确率
print('fenlei:' ,Yte_predict)
print('ceshibiaoqian:',Yte)
# show a picture
image = imgX1[6, 0:1024].reshape(32, 32)
print(image.shape)
plt.imshow(image, cmap=plt.cm.gray)
plt.axis('off') # 去除图片边上的坐标轴
plt.show()
image = imgX2[6, 0:1024].reshape(32, 32)
print(image.shape)
plt.imshow(image, cmap=plt.cm.gray)
plt.axis('off') # 去除图片边上的坐标轴
plt.show()
image = imgX3[6, 0:1024].reshape(32, 32)
print(image.shape)
plt.imshow(image, cmap=plt.cm.gray)
plt.axis('off') # 去除图片边上的坐标轴
plt.show()
image = imgX4[6, 0:1024].reshape(32, 32)
print(image.shape)
plt.imshow(image, cmap=plt.cm.gray)
plt.axis('off') # 去除图片边上的坐标轴
plt.show()
image = imgX5[6, 0:1024].reshape(32, 32)
print(image.shape)
plt.imshow(image, cmap=plt.cm.gray)
plt.axis('off') # 去除图片边上的坐标轴
plt.show()
'''
image = imgX6[6, 0:1024].reshape(32, 32)
print(image.shape)
plt.imshow(image, cmap=plt.cm.gray)
plt.axis('off') # 去除图片边上的坐标轴
plt.show()
4、相关运行结果
1)曼哈顿距离运行结果

2)欧式距离运行结果
5、建议
各位和博主一样的小白,可以通过读取各个变量中的数据来了解数据集的构成。以及各个模型中的具体操作。祝大家学习顺利。
(未完待续)