Pandas大全(一直补充)
一、pandas基本数据结构
Pandas 是基于 NumPy 的一个非常好用的库,正如名字一样,人见人爱。之所以如此,就在于不论是读取、处理数据,用它都非常简单。
基本的数据结构
Pandas 有两种自己独有的基本数据结构。读者应该注意的是,它固然有着两种数据结构,因为它依然是 Python 的一个库,所以,Python 中有的数据类型在这里依然适用,也同样还可以使用类自己定义数据类型。只不过,Pandas 里面又定义了两种数据类型:Series 和 DataFrame,它们让数据操作更简单了。
1、Series
Series 就如同列表一样,一系列数据,每个数据对应一个索引值。比如这样一个列表:[9, 3, 8],如果跟索引值写到一起,就是:
| data | 9 | 3 | 8 |
|---|---|---|---|
| index | 0 | 1 | 2 |
这种样式我们已经熟悉了,不过,在有些时候,需要把它竖过来表示:
| index | data |
|---|---|
| 0 | 9 |
| 1 | 3 |
| 2 | 8 |
上面两种,只是表现形式上的差别罢了。
Series 就是“竖起来”的 list:
s = Series([1, 'hello', {'key': 'world', 'hao': 'lian'}, 'zhouman'])
print(s)0 1
1 hello
2 {'key': 'world', 'hao': 'lian'}
3 zhouman
dtype: object
这里,我们实质上创建了一个 Series 对象,这个对象当然就有其属性和方法了。比如,下面的两个属性依次可以显示 Series 对象的数据值和索引:
print(s.values)
print(s.index)[1 'hello' {'key': 'world', 'hao': 'lian'} 'zhouman']
RangeIndex(start=0, stop=4, step=1)
列表的索引只能是从 0 开始的整数,Series 数据类型在默认情况下,其索引也是如此。不过,区别于列表的是,Series 可以自定义索引:

2、DataFrame
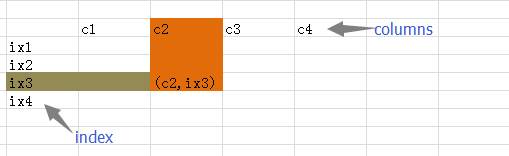
DataFrame 是一种二维的数据结构,非常接近于电子表格或者类似 mysql 数据库的形式。它的竖行称之为 columns,横行跟前面的 Series 一样,称之为 index,也就是说可以通过 columns 和 index 来确定一个主句的位置。(有人把 DataFrame 翻译为“数据框”,是不是还可以称之为“筐”呢?向里面装数据嘛。)
import pandas as pd from pandas import Series, DataFrame data = {"name":["yahoo","google","facebook"], "marks":[200,400,800], "price":[9, 3, 7]} f1 = DataFrame(data) print(f1)marks name price 0 200 yahoo 9 1 400 google 3 2 800 facebook 7
这是定义一个 DataFrame 对象的常用方法——使用 dict 定义。字典的“键”("name","marks","price")就是 DataFrame 的 columns 的值(名称),字典中每个“键”的“值”是一个列表,它们就是那一竖列中的具体填充数据。上面的定义中没有确定索引,所以,按照惯例(Series 中已经形成的惯例)就是从 0 开始的整数。从上面的结果中很明显表示出来,这就是一个二维的数据结构(类似 excel 或者 mysql 中的查看效果)。
上面的数据显示中,columns 的顺序没有规定,就如同字典中键的顺序一样,但是在 DataFrame 中,columns 跟字典键相比,有一个明显不同,就是其顺序可以被规定,向下面这样做:
>>> f2 = DataFrame(data, columns=['name','price','marks'])
>>> f2
name price marks
0 yahoo 9 200
1 google 3 400
2 facebook 7 800 跟 Series 类似的,DataFrame 数据的索引也能够自定义。
>>> f3 = DataFrame(data, columns=['name', 'price', 'marks', 'debt'], index=['a','b','c'])
>>> f3
name price marks debt
a yahoo 9 200 NaN
b google 3 400 NaN
c facebook 7 800 NaN 读者还要注意观察上面的显示结果。因为在定义 f3 的时候,columns 的参数中,比以往多了一项('debt'),但是这项在 data 这个字典中并没有,所以 debt 这一竖列的值都是空的,在 Pandas 中,空就用 NaN 来代表了。
定义 DataFrame 的方法,除了上面的之外,还可以使用“字典套字典”的方式。
>>> newdata = {"lang":{"firstline":"python","secondline":"java"}, "price":{"firstline":8000}}
>>> f4 = DataFrame(newdata)
>>> f4
lang price
firstline python 8000
secondline java NaN 在字典中就规定好数列名称(第一层键)和每横行索引(第二层字典键)以及对应的数据(第二层字典值),也就是在字典中规定好了每个数据格子中的数据,没有规定的都是空。
>>> DataFrame(newdata, index=["firstline","secondline","thirdline"])
lang price
firstline python 8000
secondline java NaN
thirdline NaN NaN 如果额外确定了索引,就如同上面显示一样,除非在字典中有相应的索引内容,否则都是 NaN。
前面定义了 DataFrame 数据(可以通过两种方法),它也是一种对象类型,比如变量 f3 引用了一个对象,它的类型是 DataFrame。承接以前的思维方法:对象有属性和方法。
>>> f3.columns
Index(['name', 'price', 'marks', 'debt'], dtype=object) DataFrame 对象的 columns 属性,能够显示素有的 columns 名称。并且,还能用下面类似字典的方式,得到某竖列的全部内容(当然包含索引):
>>> f3['name']
a yahoo
b google
c facebook
Name: name 这是什么?这其实就是一个 Series,或者说,可以将 DataFrame 理解为是有一个一个的 Series 组成的。
一直耿耿于怀没有数值的那一列,下面的操作是统一给那一列赋值:
>>> f3['debt'] = 89.2
>>> f3
name price marks debt
a yahoo 9 200 89.2
b google 3 400 89.2
c facebook 7 800 89.2除了能够统一赋值之外,还能够“点对点”添加数值,结合前面的 Series,既然 DataFrame 对象的每竖列都是一个 Series 对象,那么可以先定义一个 Series 对象,然后把它放到 DataFrame 对象中。如下:
>>> sdebt = Series([2.2, 3.3], index=["a","c"]) #注意索引
>>> f3['debt'] = sdebt 将 Series 对象(sdebt 变量所引用) 赋给 f3['debt']列,Pandas 的一个重要特性——自动对齐——在这里起做用了,在 Series 中,只有两个索引("a","c"),它们将和 DataFrame 中的索引自动对齐。于是乎:
>>> f3
name price marks debt
a yahoo 9 200 2.2
b google 3 400 NaN
c facebook 7 800 3.3自动对齐之后,没有被复制的依然保持 NaN。
还可以更精准的修改数据吗?当然可以,完全仿照字典的操作:
>>> f3["price"]["c"]= 300
>>> f3
name price marks debt
a yahoo 9 200 2.2
b google 3 400 NaN
c facebook 300 800 3.3 这些操作是不是都不陌生呀,这就是 Pandas 中的两种数据对象。
下一篇:Pandas大全(一直补充)2