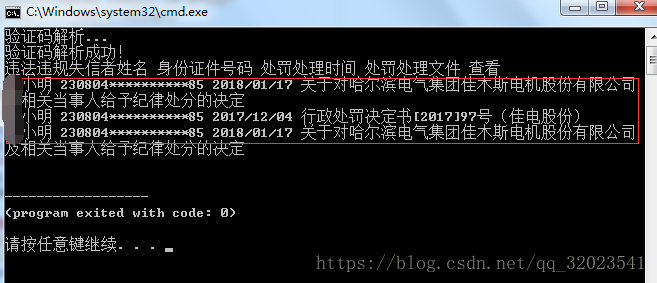
爬虫实战 -- (爬取证券期货市场失信记录平台)
这里我们要通过实际展示爬取证券期货市场失信记录平台上的搜索数据。
页面:http://shixin.csrc.gov.cn/honestypub 如下:

我们现在要通过爬虫给定一个 姓名,机构代码 ,爬取获得的结果。
这里主要说明两点:
1. 这是一个动态网页,因此我采用 selenium 方法。
2.这里的验证码图片并不在源码内,因此前面的通过 css 选择器直接下载的方式是不行的。并且给定的验证码图片的连接即使一样,生成的验证码也是随机的,因此我们并不能通过源码中给定链接下载验证码这种方式。
验证码部分在源代码解析如下:

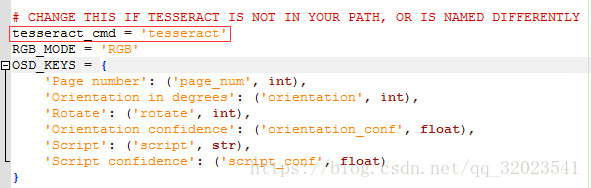
这是一个链接,并且这个链接生成的验证码是会变动,并不能通过这个链接下载到我们要的验证码图形。因此我的处理方案是直接截图下来进行解析。解析采用 pytesseract 模块,但其实里面源码就是调用 tesseract ,因此要安装这个。
爬虫完整代码如下:
# -*- coding:utf-8 -*-
import json
from PIL import Image
import pytesseract
from selenium import webdriver
# 为实现异步请求,增加 monkey
from gevent import monkey
from gevent.pywsgi import WSGIServer
#monkey.patch_all()
#from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import ui
#from selenium.webdriver.common.keys import Keys
#from selenium.webdriver.firefox.options import Options
import sys,os
reload(sys)
sys.setdefaultencoding("utf-8")
import datetime
import logging
import time
from io import BytesIO
# 因为要用docker 服务,所以不采用任何写入操作
#logger_file = logging.getLogger("firefox")
logger_console = logging.getLogger("firefox_console")
formatter = logging.Formatter('%(process)s -- %(asctime)s %(levelname)s: %(message)s')
#file_handler = logging.FileHandler("firefox.log")
#file_handler.setFormatter(formatter)
console_handler = logging.StreamHandler(sys.stdout)
console_handler.setFormatter(formatter)
#logger_file.addHandler(file_handler)
logger_console.addHandler(console_handler)
#logger_file.setLevel(logging.INFO)
logger_console.setLevel(logging.INFO)
from flask import Flask, request
from flask import Response
from flask_cors import CORS
from flask_restful import reqparse, abort, Api, Resource
from conf.config import APPID
#ff_option = Options()
#ff_option.add_argument('-headless')
options = webdriver.FirefoxOptions()
options.set_headless()
# 设置用户代理
#profile = webdriver.FirefoxProfile()
#profile.set_preference("general.useragent.enable_overrides",True)
#profile.set_preference("general.useragent.override","Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Mobile Safari/537.36")
#profile.update_preferences()
import platform
SYSTEM = platform.system()
if SYSTEM == "Windows":
chromedriver = "C:\Program Files\Mozilla Firefox\geckodriver.exe"
#chromedriver = r"E:\phantomjs-2.1.1-windows\bin\phantomjs.exe"
else:
chromedriver = "driver/geckodriver"
# 验证码最大解析次数
MAX_RETRY = 10
RESTART_FLAG = 0
PAGE_LOAD_TIME = 20
LOGIN_WEB = "http://shixin.csrc.gov.cn/honestypub"
driver = webdriver.Firefox(executable_path=chromedriver,firefox_options=options) #,firefox_profile = profile)
wait = ui.WebDriverWait(driver,10)
driver.get(LOGIN_WEB)
wait.until(lambda driver: driver.find_element_by_id("objName"))
# 设置页面加载时间
driver.set_page_load_timeout(PAGE_LOAD_TIME)
cache = []
app = Flask(__name__)
CORS(app, resources=r'/*')
# 使用 restful 扩展库
api = Api(app)
# 获取失信人信息
def get_shixinren(driver,name,card = ""):
# 为了防止卡顿的问题,造成浏览器无法刷新
# driver.refresh()
global RESTART_FLAG
driver.back()
if RESTART_FLAG >= 5:RESTART_FLAG = 0; logger_console.warn("浏览器重启中...".decode("utf-8") if SYSTEM == "Windows" else "浏览器重启中..."); restart_driver()
# 模拟回车操作
# ActionChains(driver).key_down(Keys.ENTER).key_up(Keys.ENTER).perform()
# 组合操作示例 control + c
# ActionChains(driver).key_down(Keys.CONTROL).send_keys('c').key_up(Keys.CONTROL).perform()
logger_console.info("name = %s & card = %s".decode("utf-8") %(name,card) if SYSTEM == "Windows" else "name = %s & card = %s" %(name,card))
driver.find_element_by_id("objName").click()
driver.find_element_by_id("objName").clear()
driver.find_element_by_id("objName").send_keys(name)
driver.find_element_by_id("realCardNumber").click()
driver.find_element_by_id("realCardNumber").clear()
driver.find_element_by_id("realCardNumber").send_keys(card)
count = 0
check_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
while True:
if count >= MAX_RETRY:
RESTART_FLAG += 1
logger_console.warn("验证码解析超过 %d 次未成功".decode("utf-8") %MAX_RETRY if SYSTEM == "Windows" else "验证码解析超过 %d 次未成功" %MAX_RETRY)
return json.dumps({"status":1,"check_time":check_time,"result":[],"message":"验证码解析超过 %d 次未成功".decode("utf-8") %MAX_RETRY},ensure_ascii = False) if SYSTEM == "Windows" \
else json.dumps({"status":1,"check_time":check_time,"result":[],"message":"验证码解析超过 %d 次未成功" %MAX_RETRY},ensure_ascii = False)
driver.find_element_by_id("captcha_img").click()
try:
# 获取验证码图片
im = get_picture(driver)
# 解析验证码
yanzhengma = parse_ycode(im)
except:
logger_console.error("当前网络不佳,页面加载失败...".decode("utf-8") if SYSTEM == "Windows" else "当前网络不佳,页面加载失败...")
return json.dumps({"status":1,"check_time":check_time,"result":[],"message":"网络故障!".decode("utf-8") if SYSTEM == "Windows" else "网络故障!"},ensure_ascii = False)
count += 1
# 如果验证码解析错误,刷新验证码重新解析
if yanzhengma is None:continue
driver.find_element_by_id("ycode").click()
driver.find_element_by_id("ycode").clear()
driver.find_element_by_id("ycode").send_keys(yanzhengma)
driver.find_element_by_id("querybtn").click()
res = driver.find_element_by_css_selector(
".search_bg > table:nth-child(2) > tbody:nth-child(1) > tr:nth-child(3) > td:nth-child(4)")
res = res.text
error = "验证码错误!".decode("utf-8") if SYSTEM == "Windows" else "验证码错误!"
if res.strip() == error:
logger_console.warn("解析验证码不正确,重新刷新验证码...".decode("utf-8") if SYSTEM == "Windows" else "解析验证码不正确,重新刷新验证码...")
#driver.find_element_by_id("objName").click()
#driver.find_element_by_id("objName").clear()
#driver.find_element_by_id("objName").send_keys(name)
#driver.find_element_by_id("realCardNumber").click()
#driver.find_element_by_id("realCardNumber").clear()
#driver.find_element_by_id("realCardNumber").send_keys(card)
driver.back()
#ActionChains(driver).key_down(Keys.ENTER).key_up(Keys.ENTER).perform()
else:
#logger_file.info("验证码解析成功!,刷新次数 %d " %count)
logger_console.info("验证码解析成功!,刷新次数 %d ".decode("utf-8") %count if SYSTEM == "Windows" else "验证码解析成功!,刷新次数 %d " %count)
break
# 全部都执行成功后,返回失信人记录
RESTART_FLAG = 0
return json.dumps({"status":0,"check_time":check_time,"result":get_information(driver),"message":"success"},ensure_ascii = False)
# 获取验证码图像
def get_picture(driver):
global cache
if cache == []:
captchaElem = driver.find_element_by_xpath('//*[@id="captcha_img"]')
captchaX = int(captchaElem.location['x'])
captchaY = int(captchaElem.location['y'])
captchaWidth = captchaElem.size['width']
captchaHeight = captchaElem.size['height']
captchaRight = captchaX + captchaWidth
captchaBottom = captchaY + captchaHeight
cache = [captchaX,captchaY,captchaRight,captchaBottom]
else:
captchaX,captchaY,captchaRight,captchaBottom = cache
# 注意不保存截图,直接获取图片信息,所以不用 as_file
#driver.get_screenshot_as_file("screenshot.png")
#imgObject = Image.open("screenshot.png")
imgObject = driver.get_screenshot_as_png()
img = Image.open(BytesIO(imgObject))
im = img.crop((captchaX, captchaY, captchaRight, captchaBottom))
gray = im.convert('L')
gray = gray.point(lambda x: 0 if x < 100 else 255, '1')
# 降噪
noise_point_list = collect_noise_point(gray)
remove_noise_pixel(gray, noise_point_list)
return gray
# 解析验证图像字符
def parse_ycode(im):
yanzhengma = pytesseract.image_to_string(im, lang='shixin1')
yanzhengma = filter(str.isalnum, str(yanzhengma))
if len(yanzhengma) == 5:
return yanzhengma
elif len(yanzhengma) > 0:
return None
else:
raise BaseException("error")
# driver.find_element_by_id("ycode").click()
# driver.find_element_by_id("ycode").send_keys("yanzhengma")
## 降噪
def sum_9_region_new(img, x, y):
'''确定噪点 '''
cur_pixel = img.getpixel((x, y)) # 当前像素点的值
width = img.width
height = img.height
if cur_pixel == 1: # 如果当前点为白色区域,则不统计邻域值
return 0
# 因当前图片的四周都有黑点,所以周围的黑点可以去除
if y < 2: # 本例中,前两行的黑点都可以去除
return 1
elif y == height - 1: # 最下面一行
if x < 1 or x == width - 1:
return 1
else:
sum = img.getpixel((x - 1, y - 1)) \
+ img.getpixel((x - 1, y)) \
+ img.getpixel((x, y - 1)) \
+ cur_pixel \
+ img.getpixel((x + 1, y - 1)) \
+ img.getpixel((x + 1, y))
return 6 - sum
else: # y不在边界
if x < 2: # 前两列
return 1
elif x == width - 1: # 右边非顶点
sum = img.getpixel((x - 1, y - 1)) \
+ img.getpixel((x - 1, y)) \
+ img.getpixel((x - 1, y + 1)) \
+ img.getpixel((x, y - 1)) \
+ cur_pixel \
+ img.getpixel((x, y + 1))
return 6 - sum
else: # 具备9领域条件的
sum = img.getpixel((x - 1, y - 1)) \
+ img.getpixel((x - 1, y)) \
+ img.getpixel((x - 1, y + 1)) \
+ img.getpixel((x, y - 1)) \
+ cur_pixel \
+ img.getpixel((x, y + 1)) \
+ img.getpixel((x + 1, y - 1)) \
+ img.getpixel((x + 1, y)) \
+ img.getpixel((x + 1, y + 1))
return 9 - sum
def collect_noise_point(img):
'''收集所有的噪点'''
noise_point_list = []
for x in range(img.width):
for y in range(img.height):
res_9 = sum_9_region_new(img, x, y)
if (0 < res_9 < 3) and img.getpixel((x, y)) == 0: # 找到孤立点
pos = (x, y)
noise_point_list.append(pos)
return noise_point_list
def remove_noise_pixel(img, noise_point_list):
'''根据噪点的位置信息,消除二值图片的黑点噪声'''
for item in noise_point_list:
img.putpixel((item[0], item[1]), 1)
# 获取失信人记录
def get_information(driver):
result = driver.find_element_by_css_selector("#sorttab2 > tbody:nth-child(2)")
try:
result = [{"name": s[0], "id_card": s[1], "date": s[2], "file": s[3]} for s in [i.split(" ") for i in result.text.split("\n")]]
for i in range(len(result)):
link = driver.find_element_by_xpath(
'/html/body/table[2]/tbody/tr/td/form/table/tbody/tr[4]/td/div/table[2]/tbody/tr[%d]/td[5]/a' % (i + 1))
link = link.get_attribute("href")
result[i]["link"] = link
except IndexError:
result = []
return result
# 原来通过最原始的方式实现,没有使用flask的RESTful扩展库
# 现在使用 RESTful 扩展库,因此注释掉
"""
@app.route('/shixinren', methods=['GET'])
def service():
t1 = datetime.datetime.now()
# 不设置 headers
'''
try:
token = request.headers["Content-Type"]
if token != "application/json":
raise BaseException("invalid type")
except Exception as e:
#logger_file.exception(str(e))
logger_console.exception(str(e))
return json.dumps({"status":1,"message":str(e),"result":[]},ensure_ascii = False)
'''
# 改成get 方法
name = request.args.get("name")
card = request.args.get("card",type = str,default = "")
'''
data = request.get_data()
try:
data = json.loads(data)
name = data["name"]
if "card" in data.keys():
card = data["card"]
else:
card = ""
except Exception as e:
#logger_file.exception(str(e))
logger_console.exception(str(e))
return json.dumps({"status":1,"message":str(e),"result":[]},ensure_ascii = False)
'''
result = get_shixinren(driver,name = name ,card = card)
resp = Response(result)
resp.headers['Access-Control-Allow-Origin'] = '*'
t2 = datetime.datetime.now()
#logger_file.info("search %s spend %g seconds" %(name,(t2-t1).seconds))
logger_console.info("search %s spend %g seconds" %(name,(t2-t1).seconds))
return resp
"""
def name_not_chinese(name):
if name is None or name == "":
logger_console.exception("检索信息名字 '{0}' 不是两个及以上的汉字,非法输入".decode("utf-8").format(name) if SYSTEM == "Windows" else
"检索信息名字 '{0}' 不是两个以上的汉字,非法输入".format(name))
return True
# 特殊名
name = filter(lambda x:x<> '·',name)
for ch in name:
if not (ch >= u'\u4e00' and ch<=u'\u9fa5') or len(name) < 2:
logger_console.exception("检索信息名字 '{0}' 不是两个及以上的汉字,非法输入".decode("utf-8").format(name) if SYSTEM == "Windows" else
"检索信息名字 '{0}' 不是两个以上的汉字,非法输入".format(name))
return True
return False
def restart_driver():
global driver
driver.close()
logger_console.info("------------ReStart Driver------------")
driver = webdriver.Firefox(executable_path=chromedriver, firefox_options=options) # ,firefox_profile = profile)
wait = ui.WebDriverWait(driver, 10)
driver.get(LOGIN_WEB)
wait.until(lambda driver: driver.find_element_by_id("objName"))
driver.set_page_load_timeout(PAGE_LOAD_TIME)
class Service(Resource):
def __init__(self):
self.parser = reqparse.RequestParser()
self.parser.add_argument('name')
self.parser.add_argument('card', type=str,default = "")
self.parser.add_argument('appid', type=str, location='headers')
def get(self):
t1 = datetime.datetime.now()
args = self.parser.parse_args()
header = args.get("appid")
name = args.get("name")
check_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
logger_console.info("APPID:[%s] Request:[ %s ]" % (header, request.url))
try:
if header not in set(APPID.split(',')):
result = json.dumps({"status": 1, "check_time": check_time, "result": [], "message": "The header is not valid,please check up"})
elif name_not_chinese(name):
result = json.dumps({"status":1,"check_time":check_time,"result":[],"message":"The name is not valid,please check up"})
else:
card = args.get("card")
result = get_shixinren(driver,name = name ,card = card) if card == filter(str.isalnum,str(card)) else json.dumps( \
{"status":1,"check_time":check_time, "result":[],"message":"The card is not valid,please check up"})
logger_console.info("Output:%s" %result)
except Exception as e:
result = json.dumps({"status":2,"check_time":check_time,"result":[],"message":"some thing is error,detail in logs"})
logger_console.exception(str(e))
logger_console.info("Output:%s" %result)
restart_driver()
resp = Response(result)
resp.headers['Access-Control-Allow-Origin'] = '*'
t2 = datetime.datetime.now()
logger_console.info("search %s spend %g seconds" %(name,(t2-t1).seconds))
return resp
class Health(Resource):
def __init__(self):
self.parser = reqparse.RequestParser()
def get(self):
result = json.dumps({"status":0,"message":"ok"})
resp = Response(result)
resp.headers['Access-Control-Allow-Origin'] = '*'
return resp
api.add_resource(Service, '/shixinren')
api.add_resource(Health, '/healthcheck')
logger_console.info("*"*10 + " Service Start Now " + "*"*10)
if __name__ == "__main__":
WSGIServer(('0.0.0.0', 10723), app).serve_forever()
# 如果要用多进程 pip install gunicorn 然后执行
# gunicorn -w 4 firefox_win_mac:app -b 0.0.0.0:10723浏览器查询结果如图:
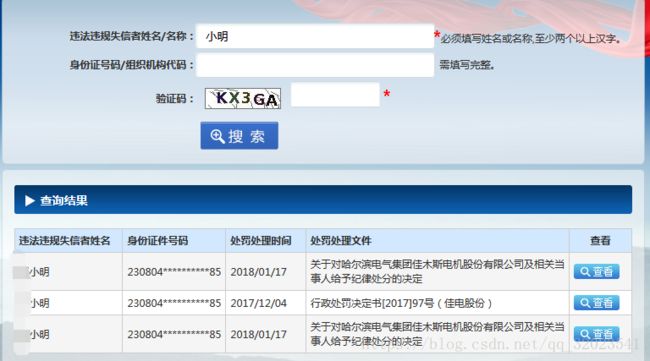
爬取结果如下: