Flume概述与使用
文章目录
- Flume概述
- 1.什么是Flume
- 2.名词介绍
- 3.Flume架构介绍
- 4.可靠性和可用性
- Flume的安装与使用
- 单机与集群安装
Flume概述
1.什么是Flume
可以理解flume是日志收集系统,Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
当前Flume有两个版本Flume 0.9X版本的统称Flume-og,Flume1.X版本的统称Flume-ng。由于Flume-ng经过重大重构,与Flume-og有很大不同,使用时请注意区分,经过架构重构后,Flume NG更像是一个轻量级的小工具,适应各种方式的日志收集,并支持failover和负载均衡。改动的另一原因是将 Flume 纳入 apache 旗下,cloudera Flume 改名为 Apache Flume。
Apache Flume是一个分布式,可靠且可用的系统,用于高效地收集,汇总和将来自多个不同源的大量日志数据移动到集中式数据存储区。Apache Flume的使用不仅限于日志数据聚合。 由于数据源是可定制的,Flume可用于传输大量的事件数据,包括但不限于网络流量数据,社交媒体生成的数据,电子邮件消息以及几乎所有可能的数据源。Apache Flume是Apache软件基金会的顶级项目。(来自Flume官网)
2.名词介绍
- Event:Event是Flume数据传输的基本单元。Flume以事件的形式将数据从源头传送到最终的目的。Event由可选的header和载有数据的一个byte array 构成。可以是日志记录、 avro 对象等。1.载有的数据对flume是不透明的;2.Headers是容纳了key-value字符串对的无序集合,key在集合内是唯一的;3.Headers可以在上下文路由中使用扩展
- Client:Client 是一个将原始log包装成events并且发送他们到一个或多个agent的实体目的是从数据源系统中解耦Flume,在flume的拓扑结构中不是必须的。Client实例:flume log4j Appender,可以使用Client SDK(org.apache.flume.api)定制特定的Client。生产数据,运行在一个独立的线程。
- Agent:使用JVM 运行Flume。每台机器运行一个agent,但是可以在一个agent中包含多个sources和sinks。一个Agent包含 source ,channel,sink 和其他组件。它利用这些组件将events从一个节点传输到另一个节点或最终目的地,agent是flume流的基础部分。flume为这些组件提供了配置,声明周期管理,监控支持。
- Source:从Client收集数据,传递给Channel。Source 负责接收event或通过特殊机制产生event,并将events批量的放到一个或多个Channel,包含event驱动和轮询两种类型。必须至少和一个channel关联。
- Channel:连接 sources 和 sinks ,这个有点像一个队列,Channel有多种方式:有MemoryChannel, JDBC Channel, MemoryRecoverChannel, FileChannel。MemoryChannel可以实现高速的吞吐,但是无法保证数据的完整。MemoryRecoverChannel在官方文档的建议上已经建义使用FileChannel来替换。FileChannel保证数据的完整性与一致性。在具体配置FileChannel时,建议FileChannel设置的目录和程序日志文件保存的目录设成不同的磁盘,以便提高效率。中转Event的一个临时存储,保存有source组件传递过来的Event,当sink成功的将event发送到下一个channel或最终目的,event从Channel移除,不同的channel提供的持久化水平是不一样的。
- Sink:从Channel收集数据,运行在一个独立线程,Sink在设置存储数据时,可以向文件系统中,数据库中,hadoop中储数据,在日志数据较少时,可以将数据存储在文件系中,并且设定一定的时间间隔保存数据。在日志数据较多时,可以将相应的日志数据存储到Hadoop中,便于日后进行相应的数据分析。负责将event传输到下一跳或最终目的,成功后将event从channel移除,必须作用一个确切的channel。
- Iterator:作用于Source,按照预设的顺序在必要地方装饰和过滤events。
- channel selector:允许Source基于预设的标准,从所有channel中,选择一个或者多个channel。
- sink processor:多个sink 可以构成一个sink group,sink processor 可以通过组中所有sink实现负载均衡,也可以在一个sink失败时转移到另一个。
3.Flume架构介绍
- flume的外部结构
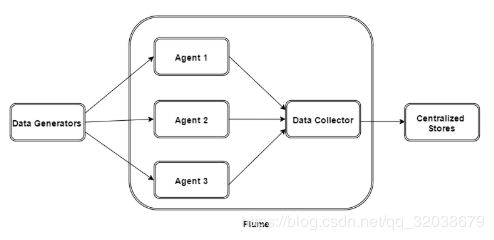
如上图所示,数据发生器(如:facebook,twitter)产生的数据被被单个的运行在数据发生器所在服务器上的agent所收集,之后数据收容器从各个agent上汇集数据并将采集到的数据进行存储。
- 数据流模型
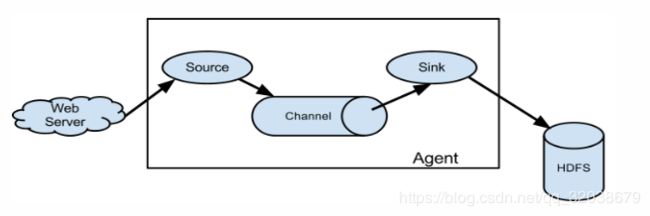
flume的核心就是一个 agent ,这个agent对外有两个进行交互的地方,一个是接受数据的输入——source,一个是数据的输出sink,sink负责将数据发送到外部指定的目的地。source接收到数据之后,将数据发送给channel,chanel作为一个数据缓冲区会临时存放这些数据,随后sink会将channel中的数据发送到指定的地方—-例如HDFS等,注意:只有在sink将channel中的数据成功发送出去之后,channel才会将临时数据进行删除,这种机制保证了数据传输的可靠性与安全性。
换言之,flume的核心是把数据从数据源( source )收集过来,在将收集到的数据送到指定的目的地( sink )。为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据( channel ),待数据真正到达目的地(sink)后,flume在删除自己缓存的数据。
在整个数据的传输的过程中,流动的是event,即事务保证是在event级别进行的event将传输的数据进行封装,是flume传输数据的基本单位,如果是文本文件,通常是一行记录,event也是事务的基本单位。event从source,流向channel,再到sink,本身为一个字节数组,并可携带headers(头信息)信息。event代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去。
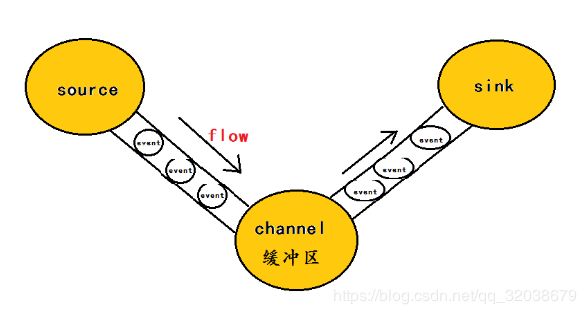
- 复杂的流

Flume允许用户在到达最终目的地之前通过多个代理程序建立多跳流。 它还允许扇入(fan-in)和扇出(fan-out)流,上下文路由和备份路由(故障转移),以用于失败的跳数。
需要注意的是:同一个Source可以将数据存储到多个Channel,实际上是Replication。一个sink只能从一个Channel中读取数据Channel和Sink是一一对应的。一个Channel只能对应一个Sink,一个Sink也只能对应一个Channel。
- 多跳流:在Flume中,可以有多个代理,在到达最终目的地之前,事件可能会通过多个代理。这被称为多跳流 。
- 扇出流量:从一个源到多个通道的数据流称为 扇出流 。它有两种类型 -
- 扇入流量:将数据从多个源传输到一个通道的数据流称为 扇入流 。
- 多路复用:将数据发送到事件标题中提到的选定通道的数据流。
4.可靠性和可用性
- 可靠性:Flume提供了三种级别的可靠性保障,从强到弱依次分别为:
- end-to-end(收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送)
- Store on failure(这也是scribe采用的策略,当数据接收方crash时,将数据写到本地,待恢复后,继续发送)
- Best effort(数据发送到接收方后,不会进行确认)
- flume使用两个独立的事务分别负责从soucrce到channel,以及从channel到sink的事件传递
- source->channel
source端到channel事务容易实现,比如spooldir,每次文件从source端到channel端,一旦文件所有数据全部传递到channel,则文件标示为成功,如果要做到精细化点,可以设置batchsize,配置一个事务多少行数据,一个batch一个事务单元,多个batch事务成功,则文件标示成功。 - channel->target
channel端到sink端事务,根据不同的channel类型有不同设定,基于FileChannel,根据sink传递状态来决定,重传数据还是标示该事务成功。而基于MemoryChannel,由于不存在数据备份,一旦sink失败,需要数据回滚,重新写回channel。
- 可用性:
- 内建的Load balancing支持:source里的event流经channel,进入sink组,在sink组内部根据负载算法(round_robin、random)选择sink,后续可以选择不同机器上的agent实现负载均衡。

- Failover:配置一组sink,这组sink组成一个Failover Sink Processor,当有一个sink处理失败,Flume将这个sink放到一个地方,等待冷却时间,可以正常处理event时再拿回来。event通过通过一个channel流向一个sink组,在sink组内部根据优先级选择具体的sink,一个失败后再转向另一个sink

Flume的安装与使用
单机与集群安装
- 单点Flume安装
- 下载安装包:http://archive.apache.org/dist/flume/1.7.0/
- 修改配置文件:flume-env.sh.template -> flume-env.sh,配置一下JAVA_HOME
- 在/etc/profile 配置一下FLUME_HOME ,也可以不配
图上无法加载主类是由于与已装的某个工具配置冲突,如Hbase,但这个好像不影响什么,所以就不更改了。- 编写配置:flume-hdfs.conf,内容如下
#agent1 name
agent1.sources=source1
agent1.sinks=sink1
agent1.channels=channel1
#Spooling Directory
#set source1
agent1.sources.source1.type=spooldir
agent1.sources.source1.spoolDir=/usr/local/include/flumetest/test
agent1.sources.source1.channels=channel1
agent1.sources.source1.fileHeader = false
agent1.sources.source1.interceptors = i1
agent1.sources.source1.interceptors.i1.type = timestamp
#set sink1
agent1.sinks.sink1.type=hdfs
agent1.sinks.sink1.hdfs.path=hdfs://host1:9000/flume/logs
agent1.sinks.sink1.hdfs.fileType=DataStream
agent1.sinks.sink1.hdfs.writeFormat=TEXT
agent1.sinks.sink1.hdfs.rollInterval=1
agent1.sinks.sink1.channel=channel1
agent1.sinks.sink1.hdfs.filePrefix=%Y-%m-%d
agent1.sinks.sink1.hdfs.fileSuffix=.txt
#set channel1
agent1.channels.channel1.type=file
agent1.channels.channel1.checkpointDir=/usr/local/include/flumetest/channel
agent1.channels.channel1.dataDirs=/usr/local/include/flumetest/logdfstmp- 执行:flume-ng agent --conf conf --conf-file /usr/local/include/flume/conf/flume-hdfs.conf --name agent1 -Dflume.root.logger=INFO,console > /usr/local/include/flume/logs/flume-hdfs.log 2>&1 &
在上面配置的spoolDir里编辑一个文件,
配置的sink1.hdfs.path就会出现文件,打开看内容与上面一致。



- Flume-ng高可用集群
1. 把安装包发送到另外两台机器上
2. 测试:从两台机器上汇总数据到一台机器,然后上传到hdfs
- 在第一台机器上按照刚刚一样的步骤新建一个master.conf
#获取slave1,2上的数据,聚合起来,传到hdfs上面
#注意:Flume agent的运行,主要就是配置source channel sink
#下面的a1就是agent的代号,source叫r1 channel叫c1 sink叫k1
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#对于source的配置描述 监听avro
a1.sources.r1.type = avro
#hostname是最终传给的主机名称或者ip地址
a1.sources.r1.bind = host1
a1.sources.r1.port = 44444
#定义拦截器,为消息添加时间戳
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
#对于sink的配置描述 传递到hdfs上面
a1.sinks.k1.type = hdfs
#集群的nameservers名字
#单节点的直接写:hdfs://host1:9000/flume/logs
#ns是hadoop集群名称
a1.sinks.k1.hdfs.path = hdfs://host1:9000/flume/logs
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.fileType = DataStream
#不按照条数生成文件
a1.sinks.k1.hdfs.rollCount = 0
#HDFS上的文件达到128M时生成一个文件
a1.sinks.k1.hdfs.rollSize = 134217728
#HDFS上的文件达到60秒生成一个文件
a1.sinks.k1.hdfs.rollInterval = 60
#对于channel的配置描述 使用内存缓冲区域做数据的临时缓存
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#通过channel c1将source r1和sink k1关联起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1- 在另外两台机器上新建文件slave.conf
#主要作用是监听目录中的新增数据,采集到数据之后,输出到avro (输出到agent)
#注意:Flume agent的运行,主要就是配置source channel sink
#下面的a1就是agent的代号,source叫r1 channel叫c1 sink叫k1
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#具体定义source
a1.sources.r1.type = spooldir
#先创建此目录,保证里面空的
a1.sources.r1.spoolDir = /usr/local/include/flumetest/test
#对于sink的配置描述 使用avro日志做数据的消费
a1.sinks.k1.type = avro
#hostname是最终传给的主机名称或者ip地址
a1.sinks.k1.hostname = host1
a1.sinks.k1.port = 44444
#对于channel的配置描述 使用文件做数据的临时缓存 这种的安全性要高
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /usr/local/include/flumetest/checkpoint
a1.channels.c1.dataDirs = /usr/local/include/flumetest/data
#通过channel c1将source r1和sink k1关联起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1- 启动:
机器一:flume-ng agent -n a1 --conf conf --conf-file /usr/local/include/flume/conf/master.conf -Dflume.root.logger=INFO,console > /usr/local/include/flume/logs/master.log 2>&1 &
另外两台机器:flume-ng agent --conf conf --conf-file /usr/local/include/flume/conf/slave.conf --name a1 -Dflume.root.logger=INFO,console > /usr/local/include/flume/logs/slave.log 2>&1 &

这里就到这里了,还有更多的知识,可以自己去摸索!