项目实战——基于计算机视觉的物体位姿定位及机械臂矫正(二)
项目实战——基于计算机视觉的物体位姿定位及机械臂矫正(二)
为什么进行相机标定
在图像测量过程以及机器视觉应用中,为确定空间物体表面某点的三维几何位置与其在图像中对应点之间的相互关系,必须建立相机成像的几何模型,这些几何模型参数就是相机参数。当然,很多相机在出厂的时候就会把参数给你,但大多数情况下,这都是不准的,需要自己进行求解。在大多数条件下这些参数必须通过实验与计算才能得到,这个求解参数(内参、外参、畸变参数)的过程就称之为相机标定(或摄像机标定)。无论是在图像测量或者机器视觉应用中,相机参数的标定都是非常关键的环节,其标定结果的精度及算法的稳定性直接影响相机工作产生结果的准确性。因此,做好相机标定是做好后续工作的前提。
关于相机标定的原理和算法,可以参考“没想到”的博客,这是他的地址,或者搜索相机标定第一个就是。
https://blog.csdn.net/a083614/article/details/78579163
程序+最详细注解
我参考的是《Learning Opencv3:Computer Vision in C++ with the Opencv Library》P592,例18-1。自己手动撸了一遍代码,对原来的代码进行了一定的改写,并附上详细的注解,以供刚入坑的朋友们(其实是我怕以后看不懂了orz)参考。好了,闲话少叙,书归正传,附上代码:
/*******************************
* @Function Camera calibration
* @Works 读取棋盘的高度和宽度,读取和收集所需的视图数量,标定相机
* @Author Hunt Tiger Tonight
* @Platform VS2015 C++
* @Connect phone:18398621916/QQ:136768916
* @Date 2018-10-20
********************************/
#include
#include
using namespace std; //使用命名空间std
int main(int argc, char *argv[])
{
int n_boards = 0; //初始化监测标定图像的数目,后面在输入参数里面获取,为了保证参数的求解精度,我们至少需要10张以上的图像
float image_sf = 0.5f; //初始化缩放比例为0.5。
float delay = 1.f; //初始化相机的拍摄延时为1s.
int board_w = 0; //初始化窗口的宽度
int board_h = 0; //初始化窗口的高度
//输入参数一定要是5个,否则输出:输出参数有误,并返回-1
if (argc < 4 || argc > 6)
{
cout << "\nERROR:输入参数有误。";
return -1;
}
board_w = atoi(argv[1]);
board_h = atoi(argv[2]);
n_boards = atoi(argv[3]);
delay = atof(argv[4]);
image_sf = atof(argv[5]); //获取输入参数并转化为整形、浮点型数
int board_n = board_w*board_h;
cv::Size board_sz = cv::Size(board_w, board_h); //board_sz定义为size类型的数据
//打开摄像头
cv::VideoCapture capture(0);
if (!capture.isOpened())
{
cout << "\n无法打开摄像头。";
return -1;
}
//分配储存面
vector> image_points; //定义棋盘中图像角点的输出矩阵(向量中的向量)
vector> object_points; //定义物理坐标系中角点的输出矩阵(向量中的向量)
//相机不断拍摄图像,直到找到棋盘,并找齐所有的图像。
double last_captured_timestamp = 0; //初始化最后一次捕获图像时间为0
cv::Size image_size; //构造size型函数
//开始搜索,直到找到全部图像
while (image_points.size() < (size_t)n_boards)
{
cv::Mat image0, image; //构造原始图像矩阵以及输出图像矩阵
capture >> image0; //将原始图像存到capture中
image_size = image0.size(); //获取image0d大小
cv::resize(image0, image, cv::Size(), image_sf, image_sf, cv::INTER_LINEAR); //缩放图像,函数解析详见P268
//寻找棋盘
vector corners; //定义角点输出矩阵
bool found = cv::findChessboardCorners(image, board_sz, corners); //寻找角点函数,详见p568
//绘制棋盘
drawChessboardCorners(image, board_sz, corners, found); //绘制角点,详见p569
//如果找到棋盘了,就把他存入数据中
double timestamp = (double)clock() / CLOCKS_PER_SEC; //获取时间戳
if (found && timestamp - last_captured_timestamp > 1) //如果寻找到了棋盘
{
last_captured_timestamp = timestamp; //将当前时间更新为最后一次时间
image ^= cv::Scalar::all(255); //将图像进行一次异或运算,255为白色,即:黑变白,白变黑
cv::Mat mcorners(corners); //复制矩阵(避免破坏原有矩阵)
mcorners *= (1. / image_sf); //缩放角坐标
image_points.push_back(corners); //在image_points后插入corners,这里注意一下,此举相当于,在image图像上叠加了一个棋盘图像
object_points.push_back(vector()); //在object_points后插入Point3f类型函数,同理,先加上一个还没有求解到的图像,用一个空矩阵表示
//下面这段其实我觉得我的理解有点问题,我的理解是:将输出图像所占内存大小调整到最优,获取图像直到数目达到预设值
vector & opts = object_points.back(); //opts即:Options,简单来说就是将输出图像的最后一位大小最优
opts.resize(board_n); //调整容器大小
for (int j = 0; j < board_n; j++)
{
opts[j] = cv::Point3f(static_cast(j / board_w), static_cast(j % board_w), 0.f); //将三维数据存入opts中,注意,这个地方必须加强制转换,不然会出错!!!!!!
}
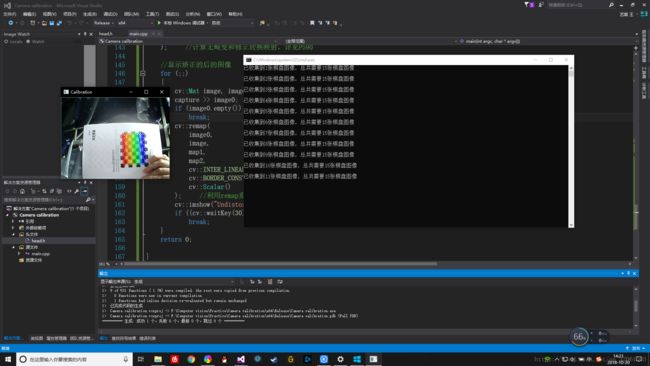
cout << "已收集到" << (int)image_points.size() << "张棋盘图像,总共需要" << n_boards << "张棋盘图像\n" << endl;
}
cv::imshow("Calibration", image); //显示图像
//等待时间为30ms,如果在这个时间段内, 用户按下ESC(ASCII码为27),则跳出循环,否则,则跳出循环
if ((cv::waitKey(30)) & 255 == 27)
return -1;
}
//结束循环
cv::destroyWindow("calibration"); //销毁窗口
cout << "\n\n***正在矫正相机...\n" << endl;
//校准相机
cv::Mat intrinsic_matrix, distortion_coeffs; //instrinsic_matrix:线性内在参数,3*3矩阵, distortion_coeffs:畸变系数:k1、k2、p1、p2
double err = cv::calibrateCamera(
object_points,
image_points,
image_size,
intrinsic_matrix,
distortion_coeffs,
cv::noArray(),
cv::noArray(),
cv::CALIB_ZERO_TANGENT_DIST|cv::CALIB_FIX_PRINCIPAL_POINT
); //校准相机函数,详见P582
//保存相机内在参数以及畸变参数
cout << "***Done!\n\nReprojection error is" << err << "\nStoring Intrinsics.xml and Distortions.xml files\n\n";
cv::FileStorage fs("intrinsics.xml", cv::FileStorage::WRITE); //保存文件为intrinsics.xml,开始写入文件
fs << "image_width" << image_size.width << "image_hight" << image_size.height << "camera_matrix" << intrinsic_matrix << "distortion" << distortion_coeffs;
fs.release(); //写入相机的宽和高,线性内在参数,畸变参数,然后释放缓存
//加载矩阵示例
fs.open("intrinsics.xml", cv::FileStorage::READ); //读取文件intrinsics.xml
cout << "\nimage width:" << static_cast(fs["image_width"]); //读取图像宽,注意,这个地方必须加强制转换,不然会出错!!!!!!
cout << "\nimage height:" << static_cast(fs["image_height"]); //读取图像高,注意,这个地方必须加强制转换,不然会出错!!!!!!
cv::Mat intrinsic_matrix_loaded, distortion_coeffs_loaded; //创建矩阵相机参数读取矩阵,畸变系数读取矩阵
fs["camera_matrix"] >> intrinsic_matrix_loaded;
fs["distortion_coefficients"] >> distortion_coeffs_loaded;
cout << "\nintrinsic matrix:" << intrinsic_matrix_loaded;
cout << "\ndistortion matrix:" << distortion_coeffs_loaded<> image0;
if (image0.empty())
break;
cv::remap(
image0,
image,
map1,
map2,
cv::INTER_LINEAR,
cv::BORDER_CONSTANT,
cv::Scalar()
); //利用remap重新传入图像
cv::imshow("Undistored", image);
if ((cv::waitKey(30)) & 255 == 27)
break;
}
return 0;
}
效果展示
目前我用的相机是淘宝四十多随便买的(后面等算法弄的差不多了再买好一点的),所以我没有上淘宝去买标定板(贼贵,肉疼,orz),打算自己DIY一个(当然有朋友赞助一下也是阔以滴,嘤嘤嘤),现在就将就着拿书上的标定板用了。


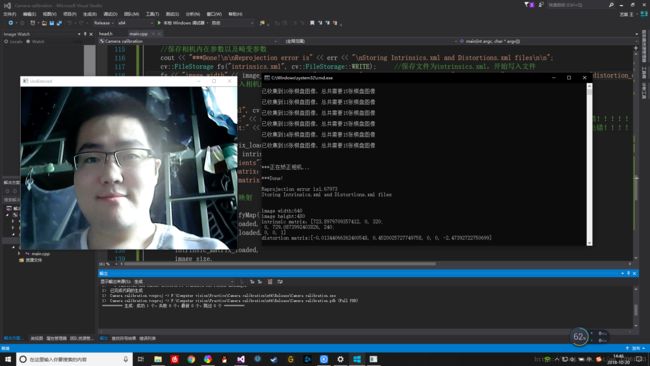
右边的intrinsic matrix返回的是相机内部的参数,是一个3*3的矩阵,distortion matrix返回的是畸变系数,k1、k2、p1、p2。
OK,相机标定大功告成,下一步工作就是立体图像识别,算是触及到项目的第一个核心了,最后的要达到的效果是:生成一张具有深度信息的图像(图像上的每一个点都能有一个深度与之对应,即:相机到物体的距离),只有这样才能对物体在世界坐标系中的具体位置和姿态有一个准确的判断。
以上就是相机标定的具体内容,可能会有问题,欢迎各路大佬指教。
Hunt Tiger Tonight
2018-10-20
PS:原创内容,转载请注明出处。