dns协议的一些整理----简单的名词解释
DNS解析过程的总结
一.几个名词
1. 域名空间(domain name space):
每个域名实际上就是一棵很大的逆向树中的路径,这棵逆向树称为域名空间。

全球的根节点有13台服务器
2.域名(domain name):
从叶节点到根的路径上所有节点标号的顺序连接。
(DNS 要求兄弟节点要有不同的标号)(唯一性)
3. 域(domain):
就是域名空间中的一棵子树。
4. 名字服务器(nameserver):
存储关于域名空间的信息的程序。通常含有域名空间中某一部分的完整信息,这一部分我们称为区(zone)。
(名字服务器要加载区而非域)
5. 区和域的区别:
域:可能含有已经授权给其他名字服务器的数据,是一颗子树
区:是以授权来划分界限的,它决不会含有已被授权出去了的数据
6. primary master(主名字服务器)和 secondary master(辅名字服务器):
一个区的主和辅名字服务器都是该区的权威。
一旦创建了区数据并建立起了主名字服务器,要创建新的名字服务器时, 你只需建立辅名字服务器,它能从该区的主名字服务器获取数据。
主名字服务器从本机中加载数据的文件叫做区数据文件(zone data file)。我们也 常常称之为数据文件(datafile)或数据库文件(database file)。
辅名字服务器常常被配置成为:将主名字服务器传送过来的区数据备份到本机的数据文件当中。
7. 解析器:
解析器是访问名字服务器的客户端程序。主机上运行的应用程序如果需要从域名空 间中获得信息,就要使用解析器。
二.解析过程简介
1. 大致过程
本地名字服务器向根名字服务器查询 girigiri.gbrmpa.gov.au 的地址,根服务器告知它去联系 au 名字服务器。本地名字服务器问 au 名字服务器同样的问题,被告知 gov.au名字服务器的地址列表。本地名字服务器从列表中选择一个 gov.au名字服务 器并向其继续询问同样的题,gov.au 名字服务器就告诉本地名字服务器 gbrmpa. gov.au 名字服务器的地址。最终,本地名字服务器向 gbrmpa.gov.au名字服务器询 问并获得答案。
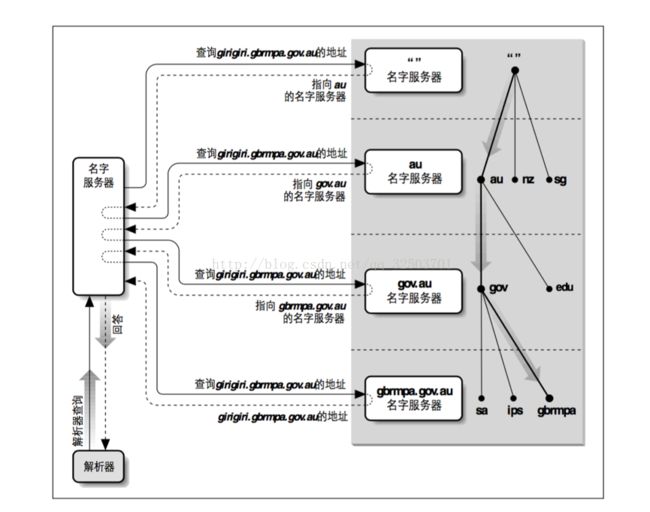
(对于递归查询:解析器向本地名字服务器查询,解析器直接查询的名字服务器(本地名字服务器)却要不断地依照指示(referral)进行查询,直到得到结果。)
2. 两种查询方式
递归查询:
递归查询将大部分的解析负担置于一个名字服务器上。递归或递归解析(recursive resolution)指的是名字服务器在收到递归查询时所使用的解析过程。正如编程中的递归算法,名字服务器只重复一个简单的过程(向远程 名字服务器提出查询,再遵照指示)直到收到结果。
收到递归查询的名字服务器发送的查询总是与解析器发给它的一模一样。
反复解析:
名字服务器只用将它已知的最合适的答案返回给查询者。这个指示包括本地数据中列出的所有名字服务器,由查询者来选择下一个向谁提出查询。
3. 名字服务器的选择
上面写到对于同一个区,可以有多个名字服务器,因此对于名字服务器的选择由RTT决定。
每次 BIND 名字服务器向远程名字服务器发送查询时,都启动一个内部计时器。当它收到响应时就停止计时,记录下该远程名字服务器过了多长时间才响应。当名字服务器要选择向哪个名字服务器发送查询时,它就选择具有最小RTT的名字服务器。
(比如说对于13个根目录名字服务器,一般选择最近的那个)
4.in-addr.arpa域
in-addr.arpa域中的节点都是用数字来作标号的,这些数字就是以点分字节(dotted-octet)来表示的 IP 地址。
比如说,in-addr.arpa最多有 256 个子域,分别和 IP 地址中的第一个字节的每个可能值相对应。这些子域又可以有 256 个自己的子域,分别和第二个字节每个可能的值相对应。 (4层)

5. 缓存
处理递归查询的名字服务器可能需要发送好几个查询才能找到结果。 缓存这些名字服务器是哪些区的权威,也知道这些服务器的地址。
名字服务器甚至还进行否定缓存 (negative caching):当某个权威名字服务器返回结果,说所查询域名或数据不存在时,本地名字服务器也会暂时将该信息放入缓存。
数据的区的管理员要为数据设定一个生存期(time to live),简称TTL。 生存期就是名字服务器允许数据在缓存中存放的时间。生存期一过,名字服务器就必须丢弃缓存的数据,并从权威名字服务器上获取新的数据。对于否定缓存数据也是一样;每隔一段时间,名字服务器也要清除否定回答,以防权威名字服务器上已经增加了新的数据。
报文
-
会话标识(2字节):是DNS报文的ID标识,对于请求报文和其对应的应答报文,这个字段是相同的,通过它可以区分DNS应答报文是哪个请求的响应
-
标志(2字节):

QR(1bit) 查询/响应标志,0为查询,1为响应 opcode(4bit) 0表示标准查询,1表示反向查询,2表示服务器状态请求 AA(1bit) 表示授权回答 TC(1bit) 表示可截断的 RD(1bit) 表示期望递归 RA(1bit) 表示可用递归 rcode(4bit) 表示返回码,0表示没有差错,3表示名字差错,2表示服务器错误(Server Failure) -
数量字段(总共8字节):Questions、Answer RRs、Authority RRs、Additional RRs 各自表示后面的四个区域的数目。Questions表示查询问题区域节的数量,Answers表示回答区域的数量,Authoritative namesversers表示授权区域的数量,Additional recoreds表示附加区域的数量
-
Queries区域
 name 查询名:
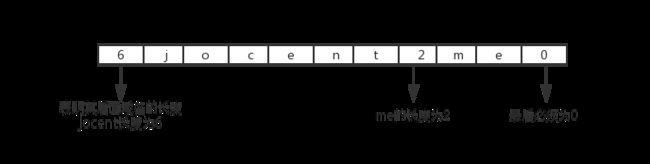
name 查询名:长度不固定,且不使用填充字节,一般该字段表示的就是需要查询的域名(如果是反向查询,则为IP,反向查询即由IP地址反查域名),一般的格式如下图所示。
Type 查询类型:
| 类型 | 助记符 | 说明 |
|---|---|---|
| 1 | A | 由域名获得IPv4地址 |
| 2 | NS | 查询域名服务器 |
| 5 | CNAME | 查询规范名称 |
| 6 | SOA | 开始授权 |
| 11 | WKS | 熟知服务 |
| 12 | PTR | 把IP地址转换成域名 |
| 13 | HINFO | 主机信息 |
| 15 | MX | 邮件交换 |
| 28 | AAAA | 由域名获得IPv6地址 |
| 252 | AXFR | 传送整个区的请求 |
| 255 | ANY | 对所有记录的请求 |
这里给一个域名,可用来模拟DNS的查询类型,可以选择不同的类型,比如A,PTR等玩一下, https://www.nslookuptool.com/chs/
class 查询类:通常为1,表明是Internet数据
-
资源记录(RR)区域(包括回答区域,授权区域和附加区域)

该区域有三个,但格式都是一样的。这三个区域分别是:回答区域,授权区域和附加区域
1. 域名(2字节或不定长)
它的格式和Queries区域的查询名字字段是一样的。有一点不同就是,当报文中域名重复出现的时候,该字段使用2个字节的偏移指针来表示。比如,在资源记录中,域名通常是查询问题部分的域名的重复,因此用2字节的指针来表示,具体格式是最前面的两个高位是 11,用于识别指针。其余的14位从DNS报文的开始处计数(从0开始),指出该报文中的相应字节数。一个典型的例子,C00C(1100000000001100,12正好是头部的长度,其正好指向Queries区域的查询名字字段)。
2. 查询类型:表明资源纪录的类型
3. 查询类:对于Internet信息,总是IN
4. 生存时间(TTL):以秒为单位,表示的是资源记录的生命周期,一般用于当地址解析程序取出资源记录后决定保存及使用缓存数据的时间,它同时也可以表明该资源记录的稳定程度,极为稳定的信息会被分配一个很大的值(比如86400,这是一天的秒数)。
5. 资源数据:该字段是一个可变长字段,表示按照查询段的要求返回的相关资源记录的数据。可以是Address(表明查询报文想要的回应是一个IP地址)或者CNAME(表明查询报文想要的回应是一个规范主机名)等。