spark rdd---checkpoint机制
先说cache.
val rdd1 = sc.textFile("hdfs://master:9000/wordcount/input")
val rdd2 = rdd1.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
rdd2.collect
这里以wordcount为例,因为rdd2中的数据经复杂操作后很重要,以后可能经常用到(如机器学习中的迭代计算,有些中间结果我们可能反复用到),我们可以将rdd2中的数据进行缓存:
rdd2.cache
观察源码:

实际上cache调用的是persist方法,

在persist方法中可以设置缓存级别:
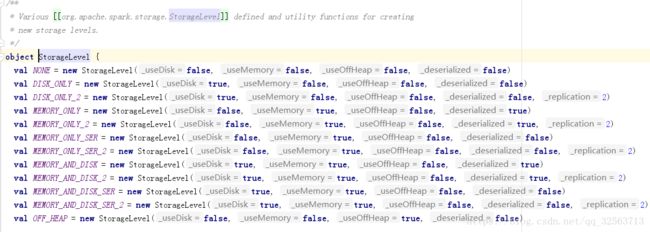
可以指定缓存到内存中、磁盘中、内存和磁盘中、内存序列化(以时间换取空间)等等。。。
cache默认使用的缓存级别是MEMORY_ONLY,只缓存在内存中。进行缓存时,rdd中的每个分区的数据是缓存在当前分区所在的节点的内存中去,如果内存不足,则只缓存部分数据,其他数据计算时还是到hdfs中去读取。
cache方法是一个transformation,惰性,只会在触发action时才会执行:
rdd2.cache
rdd2.collect
进入spark的web界面,点击对应application的detail ui:

会显示出缓存的rdd、缓存级别、缓存的分区数等详细信息。
若想取消缓存,调用rdd.persist 是一个action,会立即取消缓存。
----------------------------------------------------------------------------------------------------------------------------------
对于cache,若机器发生故障,内存或者磁盘中缓存的数据丢失时,就要根据lineage(血统)进行数据恢复,想象一下,如果在这之前有100个rdd,那么在要经过100次的转换,才能将数据恢复过来,这样效率非常低。
所以可以使用rdd的checkpoint机制(检查点,相当于快照),将你认为很重要的rdd存放到一个公共的高可用的存储系统中去,如hdfs,下次数据丢失时,就可以从前面ck的rdd直接进行数据恢复,而不需要根据lineage去从头一个一个的去恢复,这样极大地提高了效率。
首先要设置ck的存放的目录:
sc.setCheckpointDir("hdfs://master:9000/rdd-checkpoint") //使用hdfs做存储,如果文件目录不存在会创建一个新的
创建好后hdfs中会生成一个rdd-checkpoint目录,里面还会自动生成一个目录:

注意:一定不能写到本地文件系统,如果有多个分区的时候,每个executor只能把属于自己分区的数据保存起来,做数据恢复时只能恢复属于自己那部分的,而不是全部的数据!
所以要写入hdfs这种共享文件系统中,每个分区都将自己的数据写入hdfs中的一个目录
接下来:
rdd2.checkpoint
这时里面是不会有数据的,因为checkpoint是一个transformation,要触发action才可以,下面我们进行一个action操作:
rdd2.collect
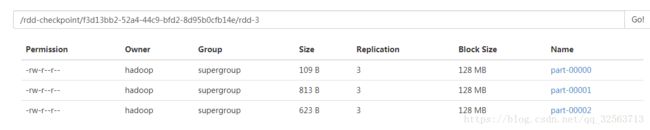
这时会启动两个任务,一个是计算collect结果,另一个是计算rdd2中的数据,并将其保存到hdfs的目录上去,此时会生成一个目录rdd-3:

点进去,里面就是rdd2中的数据啦:(rdd2中有三个分区)
观察checkpoint的源码:

它首先会对你指定的ck目录进行判断。
注意红框中的注释:
1.all references to its parent RDDs will be removed.
这个rdd之前所有的依赖关系会被移除掉,也就是说你再进行计算时,直接从这个hdfs目录中去读取数据,而不需要再根据rdd的依赖关系去重新计算,这样节省了很多计算。
2.It is strongly recommended that this RDD is persisted in memory, otherwise saving it on a file will require recomputation.
建议先将rdd缓存一下,这样会直接对内存中的数据进行ck,即:
rdd2.cache().checkpoint
不然的话还要启动一个任务根据rdd的依赖关系去重新计算。