强化学习之三点五:上下文赌博机(Contextual Bandits)
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译,该翻译是基于个人分享知识的目的进行的,欢迎交流!(This article is my personal translation for the tutorial written and posted by Arthur Juliani on Medium.com. And my work is completely based on aim of sharing knowledges and welcome communicating!)
原文地址(URL for original article)
纯属自愿翻译,只为学习与分享知识。所以如果本系列教程对你有帮助,麻烦不吝在github的项目上点个star吧!非常感谢!
文章目录
- 上下文赌博机(Contextual Bandit)

(注意,本篇博客是作为一个Part 1到Part 2之间的额外过渡)
在我的强化学习系列的Part 1,我们介绍了增强学习这个领域,并阐释了如何建立一个能解决多臂赌博机问题的agent。在那种情况下,是没有所谓**环境状态(environmental states)**的概念的,而且agent只是学习如何选择最优的行动来采取。当没有一个给定状态时,任何时刻都是最好的行动也就是永远最优的行动。Part 2建立了完备的强化学习问题,在这个问题中存在环境状态,新的状态将取决于之前的行动,而且回报也可能是在时间上有延迟的。
实际上在无状态情况与完全强化学习问题之间还有一系列的问题。我想提供一个问题示例以及如何解决它的方案。我希望强化学习的新手也能从这个逐步走向规范化问题的过程中有收获。具体来说,在这篇博客里,我想解决存在“状态”概念的问题,但它们并不取决于之前的状态或者行动。而且,我们不会考虑延迟的回报。这些东西都会在Part 2才介绍。这种简化强化学习问题的方式称作上下文赌博机(Contextual Bandit)。
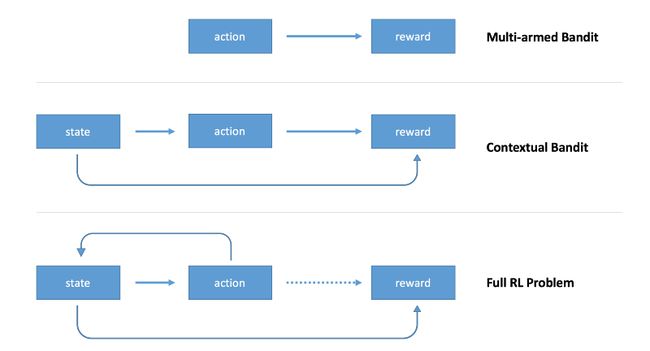
上图:多臂赌博机问题中,只有行动影响回报。中图:上下文赌博机问题中,状态和行动都影响回报。下图:完备强化学习问题中,行动影响状态,回报可能在时间上延迟。
上下文赌博机(Contextual Bandit)
在原来的Part 1中讨论的多臂赌博机问题里,只有一个赌博机,它可以被当做一个槽机器。我们的agent可选行动的范围就是从赌博机的多个臂中选一个拉动。通过这样做,获得一个+1或者-1的回报。当agent学会了总是选择可以返回正回报的臂去拉动时,这个问题就被认为是解决了。在这种情况下,我们可以设计一个完全忽略掉环境状态的agent,因为从各方面来看,都只有一个单一不变的状态。
上下文赌博机引入了状态的概念。状态就是对环境的一种描述,agent使用这种描述来采取更明智的行动。在我们的问题中,相比之前的单一赌博机,现在有多个赌博机。环境的状态告诉我们,我们正在对付哪一台赌博机,agent的目标是去学习并非只针对单一赌博机的最优行动,而是针对任意数量的赌博机的。因为每个赌博机的每个臂都将有不同的回报概率,我们的agent将需要学习如何基于环境状态来选择行动。如果agent不这么做,它将不能保证在最后完成回报的最大化。为了实现这一点,我们将在TensorFlow中建立一个单层神经网络,它接受一个状态作为输入,而输出一个行动。通过使用策略梯度更新方法,我们可以让网络学习采取能让回报最大化的行动。下面是这个教程的iPython notebook代码:
'''
Simple Reinforcement Learning in Tensorflow Part 1.5:
The Contextual Bandits
This tutorial contains a simple example of how to build a policy-gradient based agent that can solve the contextual bandit problem. For more information, see this Medium post.
For more Reinforcement Learning algorithms, including DQN and Model-based learning in Tensorflow, see my Github repo, DeepRL-Agents.
'''
import tensorflow as tf
import tensorflow.contrib.slim as slim
import numpy as np
# The Contextual Bandits
# Here we define our contextual bandits. In this example, we are using three four-armed bandit. What this means is that each bandit has four arms that can be pulled. Each bandit has different success probabilities for each arm, and as such requires different actions to obtain the best result. The pullBandit function generates a random number from a normal distribution with a mean of 0. The lower the bandit number, the more likely a positive reward will be returned. We want our agent to learn to always choose the bandit-arm that will most often give a positive reward, depending on the Bandit presented.
class contextual_bandit():
def __init__(self):
self.state = 0
#List out our bandits. Currently arms 4, 2, and 1 (respectively) are the most optimal.
self.bandits = np.array([[0.2,0,-0.0,-5],[0.1,-5,1,0.25],[-5,5,5,5]])
self.num_bandits = self.bandits.shape[0]
self.num_actions = self.bandits.shape[1]
def getBandit(self):
self.state = np.random.randint(0,len(self.bandits)) #Returns a random state for each episode.
return self.state
def pullArm(self,action):
#Get a random number.
bandit = self.bandits[self.state,action]
result = np.random.randn(1)
if result > bandit:
#return a positive reward.
return 1
else:
#return a negative reward.
return -1
# The Policy-Based Agent
# The code below established our simple neural agent. It takes as input the current state, and returns an action. This allows the agent to take actions which are conditioned on the state of the environment, a critical step toward being able to solve full RL problems. The agent uses a single set of weights, within which each value is an estimate of the value of the return from choosing a particular arm given a bandit. We use a policy gradient method to update the agent by moving the value for the selected action toward the recieved reward.
class agent():
def __init__(self, lr, s_size,a_size):
#These lines established the feed-forward part of the network. The agent takes a state and produces an action.
self.state_in= tf.placeholder(shape=[1],dtype=tf.int32)
state_in_OH = slim.one_hot_encoding(self.state_in,s_size)
output = slim.fully_connected(state_in_OH,a_size,\
biases_initializer=None,activation_fn=tf.nn.sigmoid,weights_initializer=tf.ones_initializer())
self.output = tf.reshape(output,[-1])
self.chosen_action = tf.argmax(self.output,0)
#The next six lines establish the training proceedure. We feed the reward and chosen action into the network
#to compute the loss, and use it to update the network.
self.reward_holder = tf.placeholder(shape=[1],dtype=tf.float32)
self.action_holder = tf.placeholder(shape=[1],dtype=tf.int32)
self.responsible_weight = tf.slice(self.output,self.action_holder,[1])
self.loss = -(tf.log(self.responsible_weight)*self.reward_holder)
optimizer = tf.train.GradientDescentOptimizer(learning_rate=lr)
self.update = optimizer.minimize(self.loss)
# Training the Agent
# We will train our agent by getting a state from the environment, take an action, and recieve a reward. Using these three things, we can know how to properly update our network in order to more often choose actions given states that will yield the highest rewards over time.
tf.reset_default_graph() #Clear the Tensorflow graph.
cBandit = contextual_bandit() #Load the bandits.
myAgent = agent(lr=0.001,s_size=cBandit.num_bandits,a_size=cBandit.num_actions) #Load the agent.
weights = tf.trainable_variables()[0] #The weights we will evaluate to look into the network.
total_episodes = 10000 #Set total number of episodes to train agent on.
total_reward = np.zeros([cBandit.num_bandits,cBandit.num_actions]) #Set scoreboard for bandits to 0.
e = 0.1 #Set the chance of taking a random action.
init = tf.initialize_all_variables()
# Launch the tensorflow graph
with tf.Session() as sess:
sess.run(init)
i = 0
while i < total_episodes:
s = cBandit.getBandit() #Get a state from the environment.
#Choose either a random action or one from our network.
if np.random.rand(1) < e:
action = np.random.randint(cBandit.num_actions)
else:
action = sess.run(myAgent.chosen_action,feed_dict={myAgent.state_in:[s]})
reward = cBandit.pullArm(action) #Get our reward for taking an action given a bandit.
#Update the network.
feed_dict={myAgent.reward_holder:[reward],myAgent.action_holder:[action],myAgent.state_in:[s]}
_,ww = sess.run([myAgent.update,weights], feed_dict=feed_dict)
#Update our running tally of scores.
total_reward[s,action] += reward
if i % 500 == 0:
print "Mean reward for each of the " + str(cBandit.num_bandits) + " bandits: " + str(np.mean(total_reward,axis=1))
i+=1
for a in range(cBandit.num_bandits):
print "The agent thinks action " + str(np.argmax(ww[a])+1) + " for bandit " + str(a+1) + " is the most promising...."
if np.argmax(ww[a]) == np.argmin(cBandit.bandits[a]):
print "...and it was right!"
else:
print "...and it was wrong!"
'''
Mean reward for the 3 bandits: [ 0. -0.25 0. ]
Mean reward for the 3 bandits: [ 9. 42. 33.75]
Mean reward for the 3 bandits: [ 45.5 80. 67.75]
Mean reward for the 3 bandits: [ 86.25 116.75 101.25]
Mean reward for the 3 bandits: [ 122.5 153.25 139.5 ]
Mean reward for the 3 bandits: [ 161.75 186.25 179.25]
Mean reward for the 3 bandits: [ 201. 224.75 216. ]
Mean reward for the 3 bandits: [ 240.25 264. 250. ]
Mean reward for the 3 bandits: [ 280.25 301.75 285.25]
Mean reward for the 3 bandits: [ 317.75 340.25 322.25]
Mean reward for the 3 bandits: [ 356.5 377.5 359.25]
Mean reward for the 3 bandits: [ 396.25 415.25 394.75]
Mean reward for the 3 bandits: [ 434.75 451.5 430.5 ]
Mean reward for the 3 bandits: [ 476.75 490. 461.5 ]
Mean reward for the 3 bandits: [ 513.75 533.75 491.75]
Mean reward for the 3 bandits: [ 548.25 572. 527.5 ]
Mean reward for the 3 bandits: [ 587.5 610.75 562. ]
Mean reward for the 3 bandits: [ 628.75 644.25 600.25]
Mean reward for the 3 bandits: [ 665.75 684.75 634.75]
Mean reward for the 3 bandits: [ 705.75 719.75 668.25]
The agent thinks action 4 for bandit 1 is the most promising....
...and it was right!
The agent thinks action 2 for bandit 2 is the most promising....
...and it was right!
The agent thinks action 1 for bandit 3 is the most promising....
...and it was right!
'''
希望你觉得这篇教程有帮助,能够给你一些强化学习agent如何学习解决不同复杂度和交互程度的问题的直觉。如果你已经掌握了这个问题,你就已经准备好探索时间和行动都很重要的完备问题了,它们将在Part 2中被提到。
如果这篇博文对你有帮助,你可以考虑捐赠以支持未来更多的相关的教程、文章和实现。对任意的帮助与贡献都表示非常感激!
如果你想跟进我在深度学习、人工智能、感知科学方面的工作,可以在Medium上follow我 @Arthur Juliani,或者推特@awjliani。
用Tensorflow实现简单强化学习的系列教程:
- Part 0 — Q-Learning Agents
- Part 1 — Two-Armed Bandit
- Part 1.5 — Contextual Bandits
- Part 2 — Policy-Based Agents
- Part 3 — Model-Based RL
- Part 4 — Deep Q-Networks and Beyond
- Part 5 — Visualizing an Agent’s Thoughts and Actions
- Part 6 — Partial Observability and Deep Recurrent Q-Networks
- Part 7 — Action-Selection Strategies for Exploration
- Part 8 — Asynchronous Actor-Critic Agents (A3C)