潇洒郎:Python爬取"去哪儿网"微信公众号指定年限时间的所有文章信息及文章的所有评论
潇洒郎:Python爬取"去哪儿网"微信公众号指定年限时间的所有文章信息及文章的所有评论
准备工作:
-
由于微信网页版不能登录,不能在浏览器中F12进行抓包分析!所以使用工具Fiddler对PC版微信进行抓包,找到微信公众号的真实地址。
我们准备爬取去哪儿公众号,如图,打开PC版微信,进去去哪儿公众号:
点击。。。。找到文章,
-
我们复制网址,用浏览器打开,
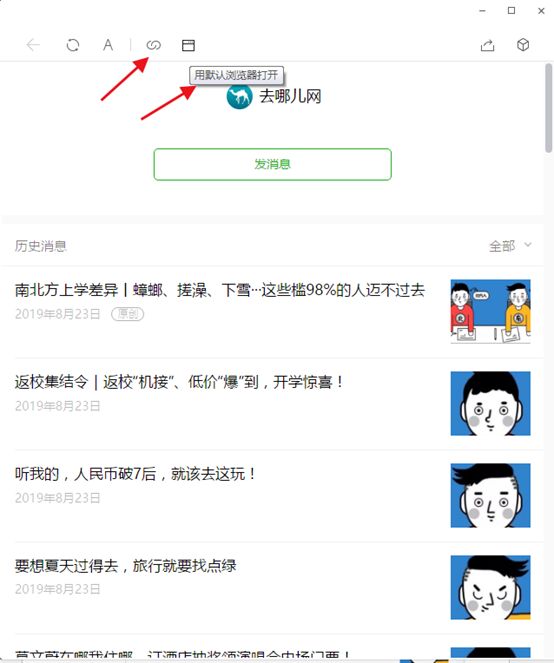
我们发现,需要验证,
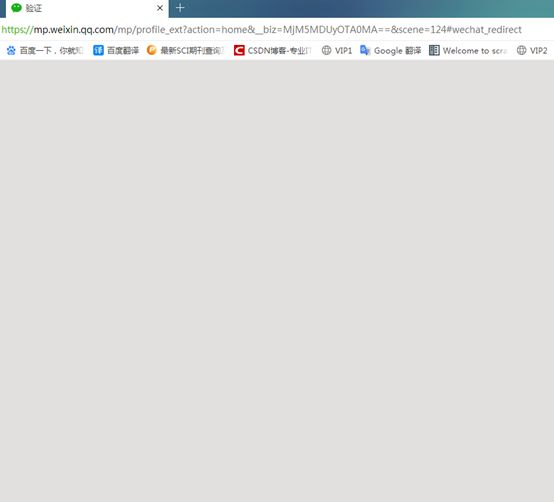
-
首先下载Fiddler,官网直接下载即可。安装这里不多叙述。打开Fiddler。按我的步骤设置Fiddler,其实并不需要怎么设置,一般都可以抓包,有问题可以按网上教程。

我们设置过滤网址,其他没用的网址我们不需要,只会给我们带来分析麻烦。我们只需要mp.weixin.qq.com;的主机网址,
设置完成之后可以点击action生效或者关闭重启。
-
现在准备工作差不多了,我们点击,观察Fidder,
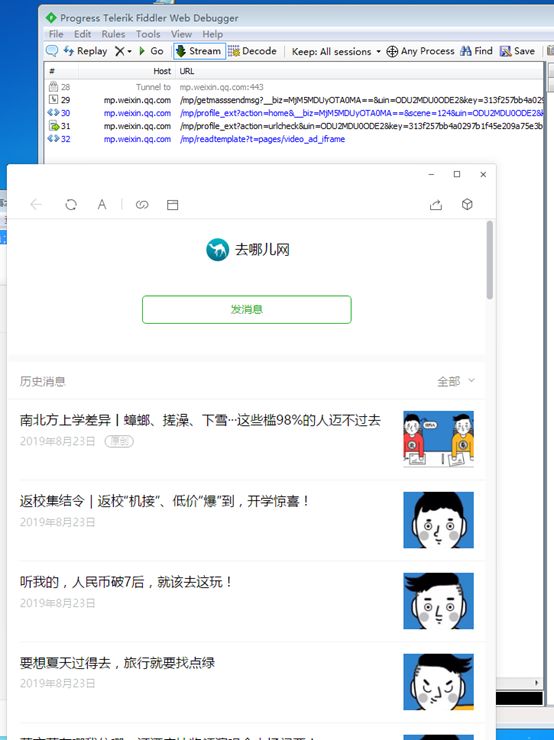
我们发现有四个网址,序号是29-32,复制网址在浏览器中打开第一个试试。
文章历史消息页面网址:
此网址过一段时间就会失效的:
https://mp.weixin.qq.com/mp/getmasssendmsg?__biz=MjM5MDUyOTA0MA==&uin=ODU2MDU0ODE2&key=313f257bb4a0297be33466f015491ce6a815f3e89059fbbee6ef4fbd651e1be175d021d37cd479679f2054fb760ca0a8c0d4f1be9ab940576c0932e469d770f0e70ed3d28774baa2c33922dddae76522&devicetype=Windows+7&version=62060834&lang=zh_CN&ascene=7&pass_ticket=xriNVGbN4amxK7Ljh6PK2yokG%2BSAMmivIPpz97M0To%2F8KhKgzgD2QTgpmiFVipyo

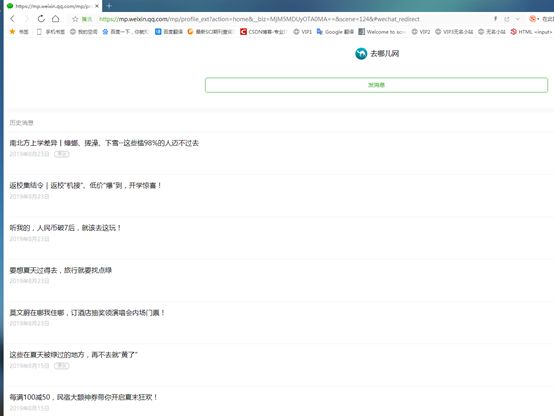
我们发现,不需要验证就可以打开网址,出现去哪儿网,文章历史消息页面,我们按F12,找到刷新网页,点击Network,拉到最上面,找到第一个html文件,点击它,可以看见其Header,Response等,Response是给网址的响应,
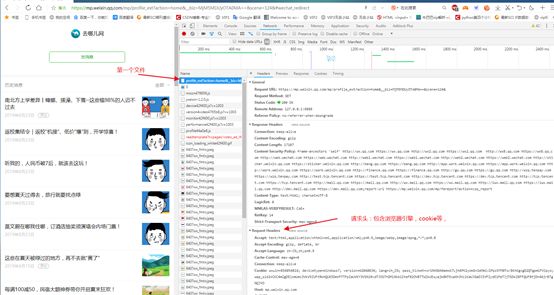
也可以看到该网址的请求头,包含User-Agent引擎,cookie,
我们暂时保存下,留待下面使用:
Cookie: wxuin=856054816; devicetype=Windows7; version=62060834; lang=zh_CN; pass_ticket=xriNVGbN4amxK7Ljh6PK2yokG+SAMmivIPpz97M0To/8KhKgzgD2QTgpmiFVipyo; wap_sid2=CKC4mZgDElxmUmc3VkV5ZUFtRkhQUE5DeVFTTFpIaUVKY3VSN1RvdTJOSThDMl9kb1IteFB2OVBTTWZkUEsyajk0NTExaXh3VzlKaUJGaDJIVFZydE1PeTJjTG5kZ0FFQUFBfjDn46jrBTgNQJVO
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3722.400 QQBrowser/10.5.3771.400
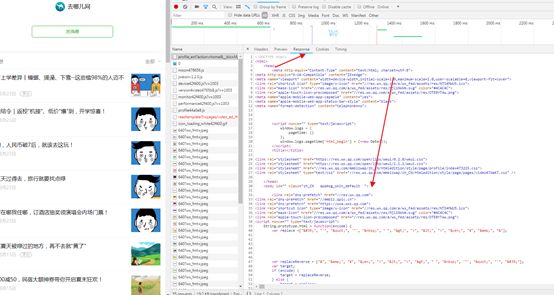
我们点击第一个文章,打开源代码,
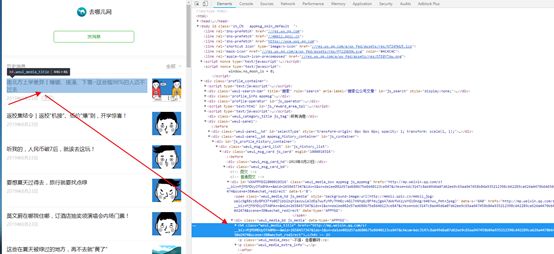
原创
南北方上学差异丨蟑螂、搓澡、下雪···这些槛98%的人迈不过去
我们发现可以找到文章的地址:
hrefs="http://mp.weixin.qq.com/s?__biz=MjM5MDUyOTA0MA==&mid=2658457347&idx=1&sn=da1ee082d57ad680b75e8640123ce847&chksm=bdc3147c8ab49d6a07d62ee9c65aa947458b84a935212398c642289ca626a4470b64650d2474&scene=38#wechat_redirect">
我们在html文件响应中搜索文章名称,发现在html文件中没有,则说明这些文件是被加载出来的,我们通过正常抓取这个历史消息网址是抓取不到内容的。
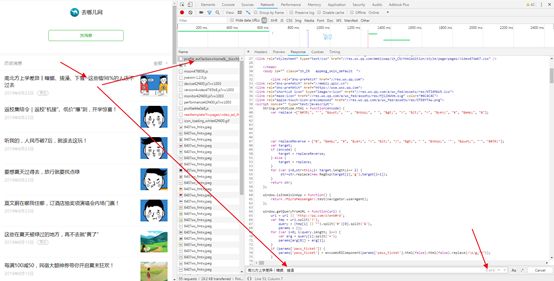
我们打开网页源码,查看到文章名称和网址等信息在var msgList里面,

我们打开Fiddler,抓取网址,

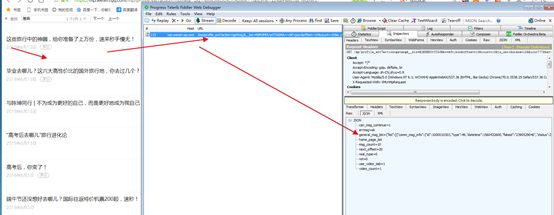
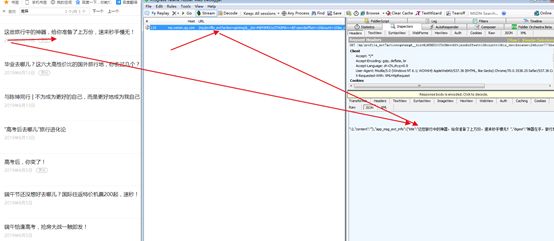
我们找到加载信息的网址,复制并在网络浏览器中打开看看是否是我们所需要的信息。事实证明,就是我们所需要的信息。
https://mp.weixin.qq.com/mp/profile_ext?action=getmsg&__biz=MjM5MDUyOTA0MA==&f=json&offset=10&count=10&is_ok=1&scene=124&uin=777&key=777&pass_ticket=&wxtoken=&appmsg_token=1024_8PPMBj5ErHrJ%252BXjQ4Ex6QeFvOCmSMUoNaqChmQ~~&x5=0&f=json
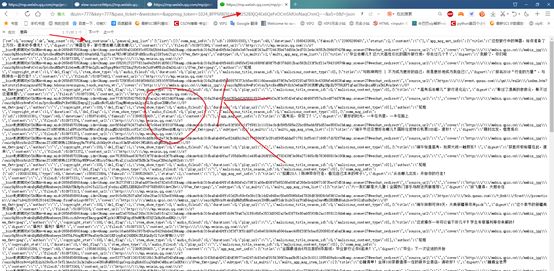
我们分析网址,每次请求的数量只有10个,offset=10&count=10,从10-20,
下拉出现的是offset=21&count=10
依次类推:
offset=31&count=10
offset=41&count=10
经过多次试验:
只有biz,token即可获得msg,但是如果没有offset=41&count=10
只能是默认获得前10个,
https://mp.weixin.qq.com/mp/profile_ext?action=getmsg&__biz=MjM5MDUyOTA0MA==&appmsg_token=1024_8PPMBj5ErHrJ%252BXjQ4Ex6QeFvOCmSMUoNaqChmQ~~&x5=0&f=json
所以我们根据规律
自定义网址,一直增加访问数量到offset=301&count=10,再次增加就无了。我们可以批量获取所有的json文件。
https://mp.weixin.qq.com/mp/profile_ext?action=getmsg&__biz=MjM5MDUyOTA0MA==&offset=301&count=10&appmsg_token=1024_8PPMBj5ErHrJ%252BXjQ4Ex6QeFvOCmSMUoNaqChmQ~~&x5=0&f=json
至此,我们可以从json文件中获取所有指定的文章网址。
说下整体思路:
(1)Fiddler抓包分析得到文章列表网址,cookie,评论网址。 观察简化网址与组合网址格式!(至关重要!)
(2)筛选获取所有文章网址,获取文章信息
(3)根据网址获取相应的评论网址——提取评论信息
(4)爬虫注意事项:同一IP降低爬取速度,避免IP被封。当然,也自制设置代理池。
下面我以代码说事,重要代码我都有注释:
'''我的python之旅'''
#获取所有文章
import requests,re
import json,time,os,csv
class Craw:
def __init__(self):
#抓包分析获得文章列表网址https://mp.weixin.qq.com/mp/getmasssendmsg?__biz=MjM5MDUyOTA0MA==&uin=MTQwNzAxMjQ4NQ%3D%3D&key=8bbaf831af1f1fae1c0e9e9490c79fbb24283dcd1e3db7ab77a5d2b707a19b90b408fbebab3cef23ab45662a8941323aee44ca936b7ec6b8e58695f8a4e93246b76e3ba98b9ae72e09781c42b7cced23&devicetype=Windows+7&version=62060834&lang=zh_CN&ascene=7&pass_ticket=jpKAtjGhSLcN3KQ85Up9bNB6sI6XulmNmeivnjGWl2CMdeUwA%2FiEphk0m5MYPw5l
#其中访问该网址后根据key会在浏览器中生成对应的cookie,但是key也会失效!该网址简化之后可得到self.url ,该网址永久有效,(前提是有最新的cookie才能访问)biz是该公众号文章列表唯一标识;
#所以当key或cookie失效时,我们只需要重新获取cookie即可
self.url = 'https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=MjM5MDUyOTA0MA==&scene=124&#wechat_redirect' # 不变,biz唯一,登录需要验证,
# 一旦cookie发生变化,那么,就必须重新用Fiddler获取
self.cookie = 'rewardsn=; wxtokenkey=777; wxuin=856054816; lang=zh_CN; pass_ticket=jpKAtjGhSLcN3KQ85Up9bNB6sI6XulmNmeivnjGWl2CMdeUwA/iEphk0m5MYPw5l; pgv_pvid=4328408971; wap_sid2=CIWd9Z4FElxFbTFKYlNCcXA3bHNNVDJNVVhvMWZnOXdoM3FzQnM2eWNhZHZnUnpnUTI4bHpPN1hiSDZqVHdZdVd6aTlCdlltOUR5OGNXX0pwamlDOFZaX2Z1QTR0UUFFQUFBfjCclbPrBTgNQJVO'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36 QBCore/3.53.1159.400 QQBrowser/9.0.2524.400 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 MicroMessenger/6.5.2.501 NetType/WIFI WindowsWechat'
, 'Cookie': self.cookie}
self.session = requests.session()
self.num=0 #用于显示我们爬取文章的数量,进度显示
# 在文章列表网址,根据cookie,最初得到的token,在源代码中ctrl+F搜索token,可得到
self.token =self.get_new_token()
# 我们自定义爬取2015.1-2017.2月的所有文章的评论
t1= '2015-01-01 00:00:00'
self.t1 = self.num_time(t1) #将时间转换为数字
t2= '2017-02-28 23:59:59'
self.t2 = self.num_time(t2)
path='C:/Users/xiaosalang/Desktop/url.txt' #用于存储所有满足条件的文章网址
isExists = os.path.exists(path)
if not isExists:
os.makedirs(path)
# 我们对比url.txt的大小,如果该文件的大小小于2kb那么,说明我们未爬取,(当然,可以自定义),如果我们爬取过所有的文章网址,大小肯定不会那么小,除非爬取满足条件的太少
file_size_kb = self.get_file_size(path).split('.')[0]
file_size_kb = int(file_size_kb)
if file_size_kb<2:
self.get_json()#获取所有文章网址
else:
print('正在写入文件。。') #开始写入文章信息以及评论信息
self.main()
def main(self):
for url in self.read_all_article_url():
#pass
time.sleep(2) #获取太频繁导致什么都获得不了
r = self.get_html(url)
a_info = self.get_a_info(r)
self.write_a_info(a_info)
self.write_c_info(r)
def read_all_article_url(self):
'''读取所有文章网址'''
with open('C:/Users/xiaosalang/Desktop/url.txt', 'r') as f:
t = f.readlines()
for i in t:
i = i.replace('\n', '').replace('\n', '')
if i!='':
#print(i)
yield i
def get_a_info(self, r):
'''获取文章的标题,网址,作者'''
try:
pat4 = ''
pat5 = ' '
pat6 = ' '
a_title = re.compile(pat4, re.S).findall(r)[0]
a_url = re.compile(pat5, re.S).findall(r)[0]
a_author = re.compile(pat6, re.S).findall(r)[0]
a_info = {}
a_info['文章标题'] = a_title
a_info['文章网址'] = a_url
a_info['文章作者'] =a_author
if a_author=='':
a_info['文章作者'] ='去哪儿网'
return a_info
except Exception as e:
print('get_a_info+',e)#get_a_info+ list index out of range
def write_a_info(self, a_info):
'''传入文章的信息,写入文章本身的信息,'''
try:
a_head = ['文章作者', '文章标题', '文章网址']
spa1 = {'文章作者': '', '文章标题': '', '文章网址': ''}
spa2 = {'文章作者': '', '文章标题': '', '文章网址': ''}
with open('C:/Users/xiaosalang/Desktop/content.csv', 'a+', encoding='gb18030', newline='') as f:
# 标头在这里传入,作为第一行数据
writer = csv.DictWriter(f, a_head)
writer.writeheader()
writer.writerow(a_info)
writer.writerow(spa1)
writer.writerow(spa2)
except Exception as e:
print('write_a_info+',e)#write_a_info+ 'NoneType' object has no attribute 'keys'
def get_c_info(self, r):
#'传入文章网址的源代码,获取评论id,组合成评论网址,评论网址,传入评论网址的响应内容,根据json文件获取评论信息'
try:
pat = 'var comment_id = "(.*?)"' #获取文章评论id,
com_id = re.compile(pat, re.S).findall(r)[0]
#注意:评论网址的评论内容只与评论id有关;但是必须有token,但是token与评论内容无关,只要有token,就可获得内容;
# offset=0&limit=100的含义是从offset=0开始获得评论,一次可获得limit=100条评论内容,一般评论数量不超过100,如果数量超过100,那么offset的值可以修改为101,201等,但是据我查看,没有超过100条的。
comment_url = 'https://mp.weixin.qq.com/mp/appmsg_comment?action=getcomment&scene=0&__biz=MjM5MDUyOTA0MA==' \
'&comment_id=%s&offset=0&limit=100&appmsg_token=%s&x5=0&f=json' % (com_id, self.token)
r_com = self.session.get(comment_url, headers=self.headers).json()['elected_comment']
if r_com==[]: #comment_url一旦错误,那么,r_com=[],获取不到评论信息,此时就需要重新获取token,
token = self.get_new_token()
comment_url = 'https://mp.weixin.qq.com/mp/appmsg_comment?action=getcomment&scene=0&__biz=MjM5MDUyOTA0MA==&comment_id=%s&offset=0&limit=100&appmsg_token=%s&x5=0&f=json' % (
com_id, token)
r_com = self.session.get(comment_url, headers=self.headers).json()['elected_comment']
for i in r_com:
m = {}
m['评论人'] = i['nick_name']
m['评论时间'] = self.format_time(i['create_time'])
m['评论点赞数'] = i['like_num']
m['评论内容'] = i['content'].replace('\n', '')
yield m
except Exception as e:
print('get_c_info+',e)#get_c_info+ 'elected_comment'
def write_c_info(self,r):
'''传入评论网址的响应内容,写入评论信息'''
c_head = ['评论人', '评论时间', '评论点赞数', '评论内容']
spa1 = {'评论人': '', '评论时间': '', '评论点赞数': '', '评论内容': ''}
spa2 = {'评论人': '', '评论时间': '', '评论点赞数': '', '评论内容': ''}
with open('C:/Users/xiaosalang/Desktop/content.csv', 'a+', encoding='gb18030', newline='') as f:
# 标头在这里传入,作为第一行数据
writer = csv.DictWriter(f, c_head)
writer.writeheader()
for i in self.get_c_info(r): #获取的评论信息
writer.writerow(i)
writer.writerow(spa1)
writer.writerow(spa2)
self.num+=1
print('写完%s'%self.num)
def format_size(self,bytes):
'''将文件大小转换为带单位的格式'''
try:
bytes = float(bytes)
kb = bytes / 1024
except:
print("传入的字节格式不对")
return "Error"
if kb >= 1024:
M = kb / 1024
if M >= 1024:
G = M / 1024
return "%fG" % (G)
else:
return "%fM" % (M)
else:
return "%fkb" % (kb)
def get_file_size(self,path):
'''获取指定文件的大小'''
try:
size = os.path.getsize(path)
return self.format_size(size)
except Exception as err:
print(err)
def get_html(self,url):
'''获取指定网址的源代码'''
try:
r =self.session.get(url, headers=self.headers,timeout=2).content.decode('utf-8')
return r
except Exception as e:
print('get_html+',e)
def get_new_token(self):
'''根据文章列表网址获取新的token,因为token每过一段时间(0.5-2小时)就会失效'''
try:
r = self.get_html(self.url)
pat = 'window.appmsg_token = "(.*?)";'
token = re.compile(pat, re.S).findall(r)[0]
return token
except Exception as e:
print('get_new_token+',e)
def format_time(self,create_time):
'''将格式为15552652的数字时间转换为2013年1月2日 12:23:22'''
try:
accurate_format_time= time.localtime(create_time)
format_time= time.strftime("%Y-%m-%d %H:%M:%S",accurate_format_time)
return format_time
except Exception as e:
print('format_time+',e)
def num_time(self,format_time):
'''将格式为2015年1月1日 00:00:00的时间转换为数字时间 15552652'''
try:
# 转换成时间数组
timeArray = time.strptime(format_time, "%Y-%m-%d %H:%M:%S")
# 转换成时间戳
timestamp = time.mktime(timeArray)
return timestamp
except Exception as e:
print('num_time+',e)
def get_json(self):
'''不断获得所有文章的网址,正常下,文章的信息都是下拉才会被加载出来'''
for i in range(1, 1000, 10):
if i > 1: #使得offset的值为0,11,21,31,,,
i=i
else:
i=i - 1
#评论网址主要由biz永不变,offset获取文章起始号;token会失效,失效之后必须重新获取;我们实验offset得知文章数量才320左右,所以设置i<1000,为了遍历所有文章
json_url = 'https://mp.weixin.qq.com/mp/profile_ext?action=getmsg&__biz=MjM5MDUyOTA0MA==&offset={0}&count=10&appmsg_token=1024_Aq%2F3USwujiEqRaHtqSpP1jk33ndPr_KxGFTBSw~~&x5=0&f=json'.format(i)
r = self.session.get(json_url, headers=self.headers).json() #self.headers中含有必须的cookie,没有cookie是无法获取到token的。
if "base_resp" in r: #如果"base_resp"在响应中,则 "errmsg":"no session"无消息,访问出错,没有文章内容,原因可能是因为token失效,我们重新获取
token = self.get_new_token() #重新获取token
#offset=0&count=10 从0开始获得文章,一次获得最大文章数量是10
json_url = 'https://mp.weixin.qq.com/mp/profile_ext?action=getmsg&__biz=MjM5MDUyOTA0MA==&offset={0}&count=10&appmsg_token={1}&x5=0&f=json'.format(i,token)
r = self.session.get(json_url, headers=self.headers).json()
try:
r = r['general_msg_list'] #我们访问的网址得到的是json文件,文章列表信息内容都在'general_msg_list'里面
r = json.loads(r) #将字符串转换为json格式,否则我们不能以字典的方式访问内容,
f = open('C:/Users/xiaosalang/Desktop/url.txt', 'a+') #我们追加(是为了对多个json文件中多个网址进行写入)创建网址存储文档
for i in r["list"]:
article_time = i['comm_msg_info']['datetime'] #获取文章发布的时间
if self.t1 < article_time < self.t2: #我们筛选我们所需时间段的文章,
article_content_url = i['app_msg_ext_info']['content_url'] #获取文章网址,此文章网址不会改变,包含sn,cksm
f.write(article_content_url) #写入网址
f.write('\n')
multi_app_msg_item_list = i['app_msg_ext_info']['multi_app_msg_item_list'] #此为该天一次发布的多篇文章,时间和上面文章一样,我们遍历该列表中的所有文章网址
for j in multi_app_msg_item_list:
contenturl = j['content_url']
f.write(contenturl)
f.write('\n')
else:
print('不满足')
except Exception as e:
print('get_json+',e)
break #一旦i 超过文章数量,那么结束循环。
f.close()
Craw()
爬取结果1,获取所有文章网址:
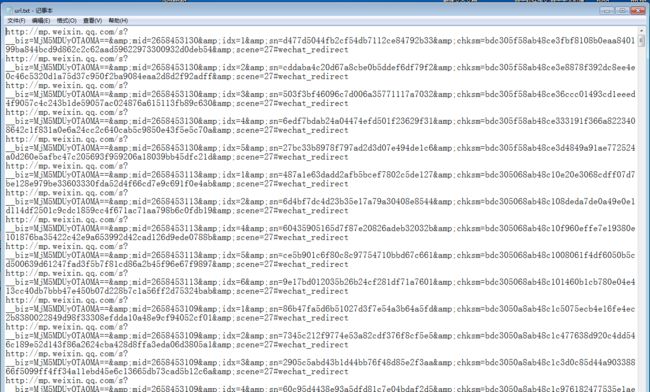
爬取结果2,文章信息以及评论信息:

很开心与各位老铁分享!如有不足,请指教!
转载请标注出处!谢谢!
2019-09-02