最近在SPARK上定位的几个内存泄露问题总结
最近为了测试延云YDB在高并发请求和持续性请求情况下的表现,发现了spark的不少关于内存泄露的问题,这些问题均在延云YDB提供的SPARK版本中得以修正,现将问题总结如下。
1. 高并发情况下的内存泄露
很遗憾,spark的设计架构并不是为了高并发请求而设计的,我们尝试在网络条件不好的集群下,进行100并发的查询,在压测3天后发现了内存泄露。
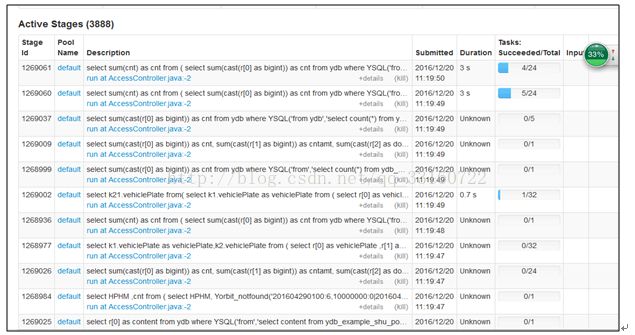
a) 在进行大量小SQL的压测过程中发现,有大量的activejob在spark ui上一直处于pending状态,且永远不结束,如下图所示
b) 并且发现driver内存爆满
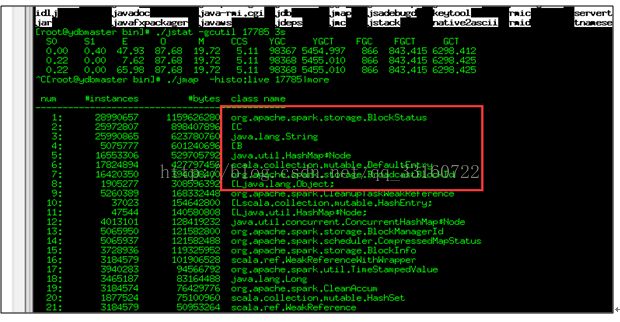
c) 用内存分析分析工具分析了下
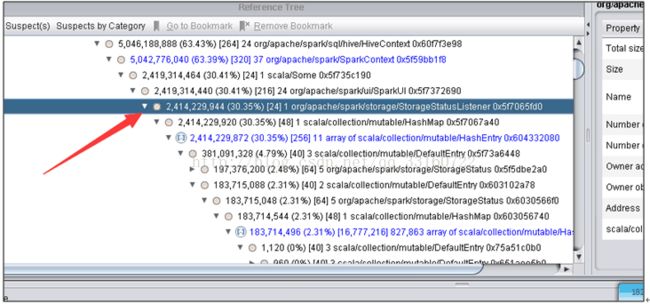
2. 定位到最终内存泄露的原因以及解决办法
1) AsynchronousListenerBus引起的WEB UI的内存泄露
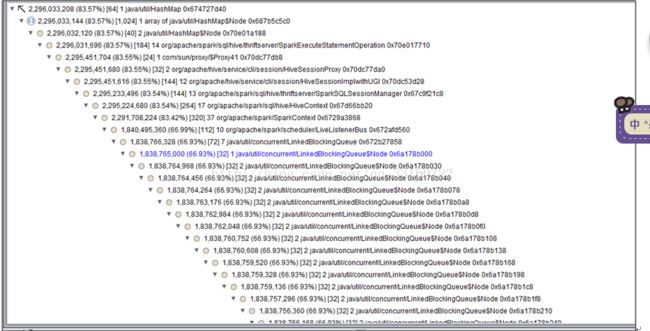
短时间内 SPARK 提交大量的SQL ,而且SQL里面存在大量的 union与join的情形,会创建大量的event对象,使得这里的 event数量超过10000个event ,
一旦超过10000个event就开始丢弃 event,而这个event是用来回收 资源的,丢弃了 资源就无法回收了。 针对UI页面的这个问题,我们将这个队列长度的限制给取消了。
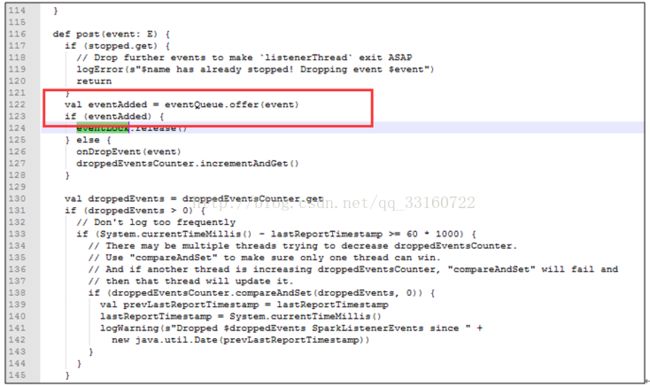
2) AsynchronousListenerBus本身引起的内存泄露
抓包发现

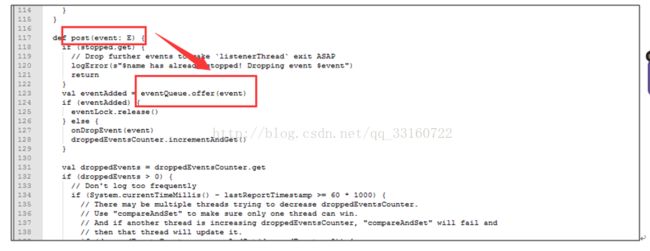
这些event是通过post方法传递的,并写入到队列里
但是也是由一个单线程进行postToAll的
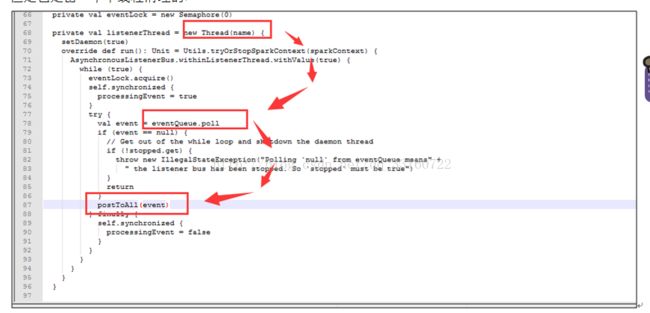
但是在高并发情况下,单线程的postToAll的速度没有post的速度快,会导致队列堆积的event越来越多,如果是持续性的高并发的SQL查询,这里就会导致内存泄露
1) Cleaner的内存泄露
同样的问题在cleaner里面也有
说道这里,Cleaner的设计应该算是spark最糟糕的设计。spark的ContextCleaner是用于回收与清理已经完成了的 广播boradcast,shuffle数据的。但是高并发下,我们发现这个地方积累的数据会越来越多,最终导致driver内存跑满而挂掉。
我们先看下,是如何触发内存回收的
没错,就是通过System.gc() 回收的内存,如果我们在jvm里配置了禁止执行System.gc,这个逻辑就等于废掉(而且有很多jvm的优化参数一般都推荐配置禁止system.gc 参数)
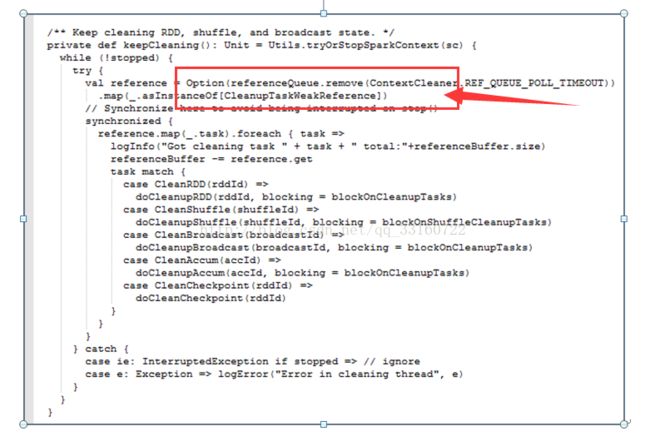
clean过程
这是一个单线程的逻辑,而且每次清理都要协同很多机器一同清理,清理速度相对来说比较慢,但是SQL并发很大的时候,产生速度超过了清理速度,整个driver就会发生内存泄露。而且brocadcast如果占用内存太多,也会使用非常多的本地磁盘小文件,我们在测试中发现,高持续性并发的情况下本地磁盘用于存储blockmanager的目录占据了我们60%的存储空间。
针对这种问题,
1.我们在SQL层加了一个SQLWAITING逻辑,判断了堆积长度,如果堆积长度超过了我们的设定值,我们这里将阻塞新的SQL的执行。堆积长度可以通过更改conf目录下的ya100_env_default.sh中的ydb.sql.waiting.queue.size的值来设置。
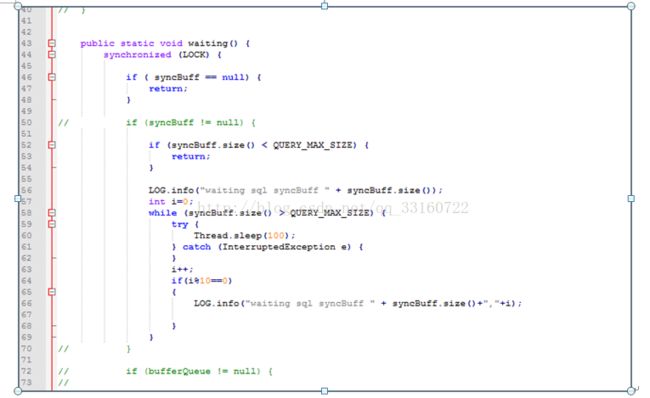
2.建议集群的带宽要大一些,万兆网络肯定会比千兆网络的清理速度快很多。
3.给集群休息的机会,不要一直持续性的高并发,让集群有间断的机会。
4.增大spark的线程池,可以调节conf下的spark-defaults.conf的如下值来改善。
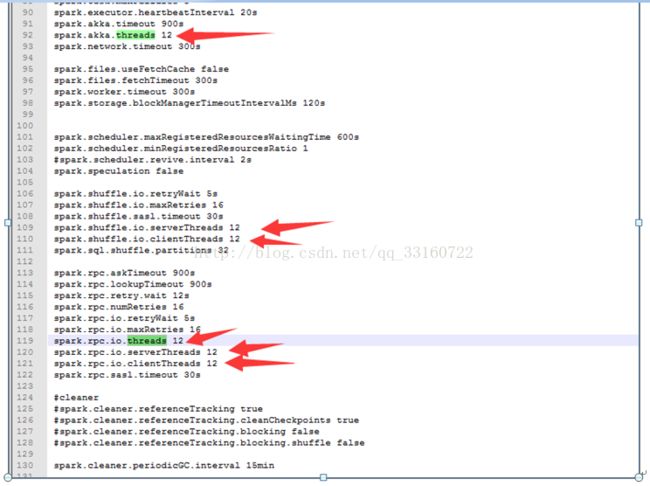
5) 线程池与threadlocal引起的内存泄露
发现spark,hive,lucene都非常钟爱使用threadlocal来管理临时的session对象,期待SQL执行完毕后这些对象能够自动释放,但是与此同时spark又使用了线程池,线程池里的线程一直不结束,这些资源一直就不释放,时间久了内存就堆积起来了。
针对这个问题,延云修改了spark关键线程池的实现,更改为每1个小时,强制更换线程池为新的线程池,旧的线程数能够自动释放。
6. 文件泄露
您会发现,随着请求的session变多,spark会在hdfs和本地磁盘创建海量的磁盘目录,最终会因为本地磁盘与hdfs上的目录过多,而导致文件系统和整个文件系统瘫痪。在YDB里面我们针对这种情况也做了处理。
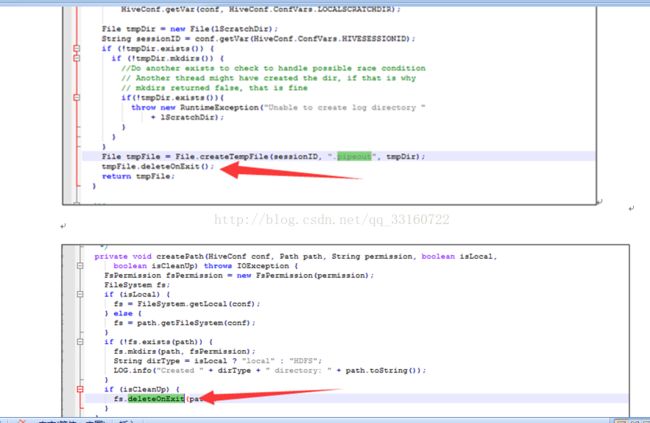
7. deleteONExit内存泄露
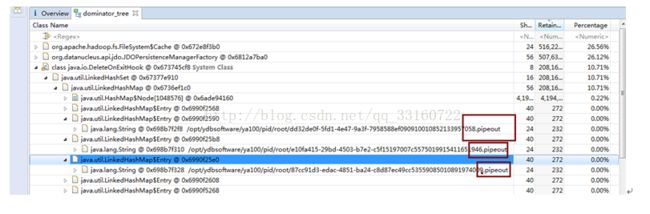
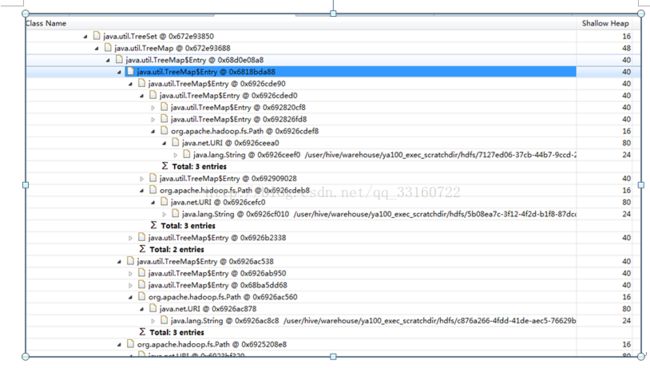
为什么会有这些对象在里面,我们看下源码
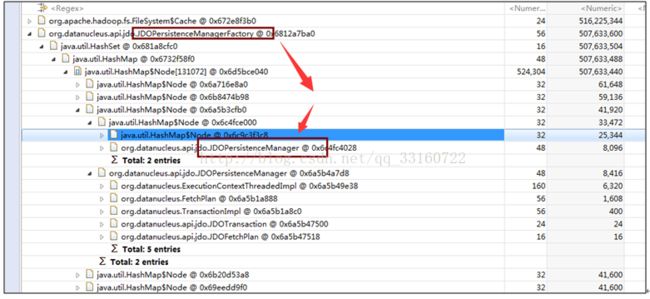
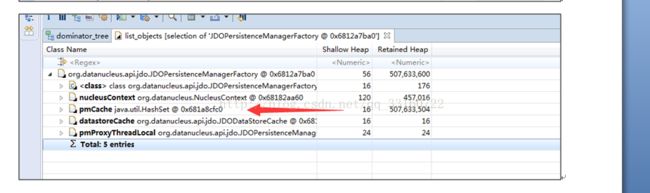
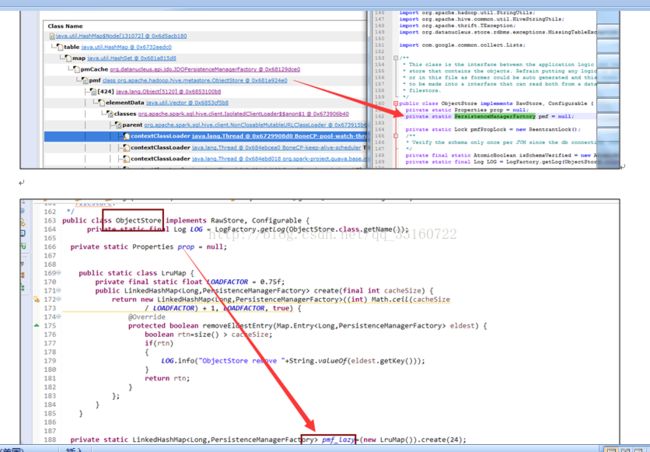
8. JDO内存泄露
多达10万多个JDOPersistenceManager

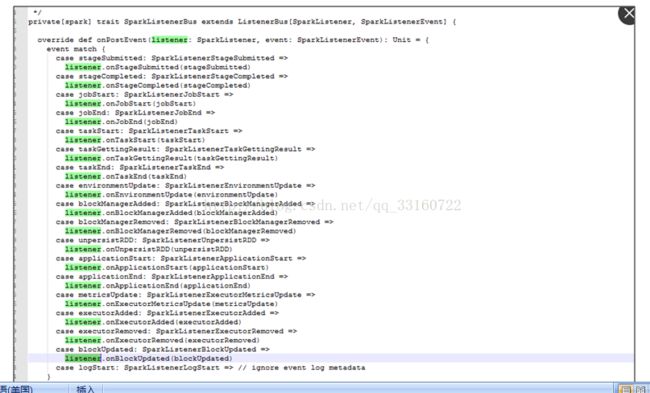
9. listerner内存泄露
通过debug工具监控发现,spark的listerner随着时间的积累,通知(post)速度运来越慢
发现所有代码都卡在了onpostevent上
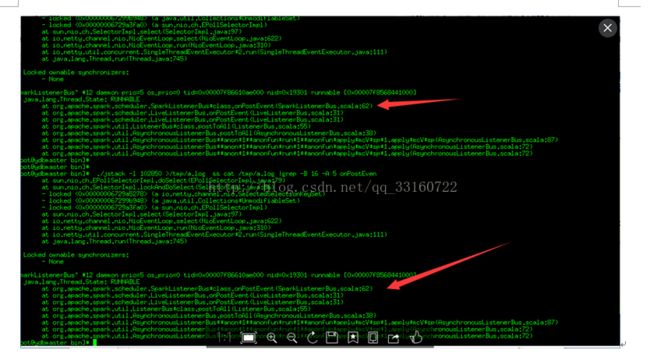
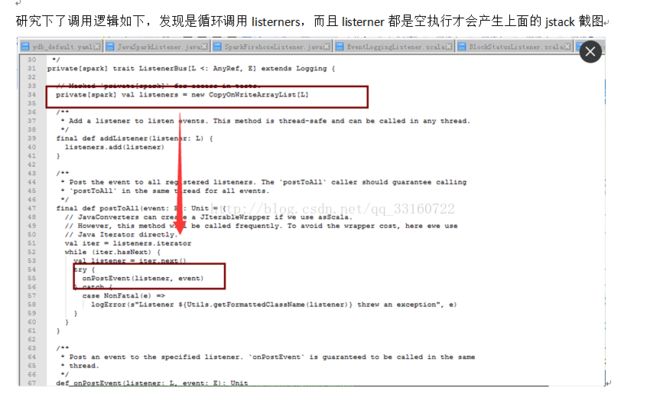
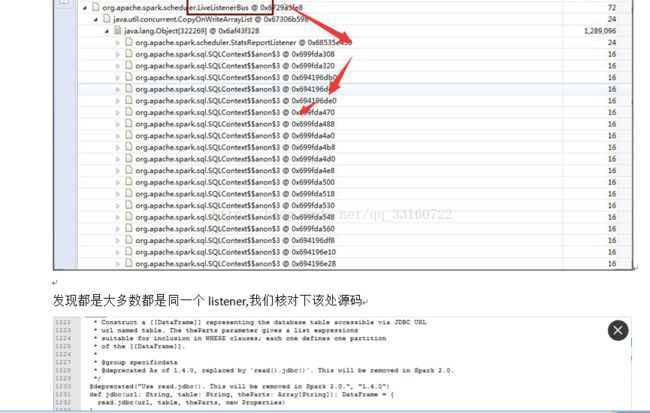
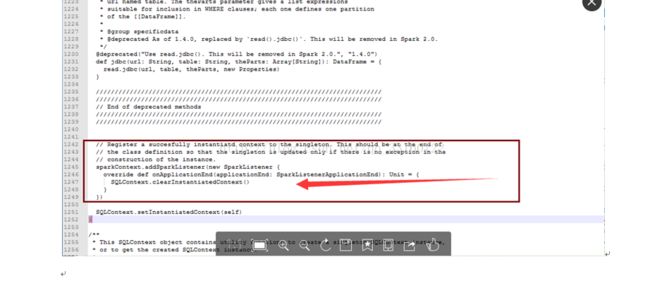
最终定位问题
确系是这个地方的BUG ,每次创建JDBC连接的时候,spark就会增加一个listener,时间久了,listener就会积累越来越多 针对这个问题 我简单的修改了一行代码,开始进入下一轮的压测