《深度学习》学习笔记二——概率论
目录
- 目录
- 随机变量
- 概率分布
- 边缘概率
- 条件概率
- 独立性和条件独立性
- 数学期望
- 方差
- 协方差
- 协方差矩阵
- 常用的概率分布
- Bernoulli 分布
- Multinoulli 分布
- 高斯分布
- 常用函数
- logistic sigmoid函数
- softplus 函数
- 参考资料
随机变量
随机变量(random variable)是可以随机地取不同值的变量.随机变量是可以离散的或者连续的,离散随机变量拥有有限或可数无限多的状态,连续随机变量伴随这实数值的.
概率分布
概率分布(probability distribution)用来描述随机变量或一簇随机变量在每一个可能取到的状态的可能性大小.
概率质量函数(probability mass function,PMF):离散型变量的概率分布可以用概率质量函数来描述,通常使用PP表示概率质量函数
概率质量函数可以同时作用于多个随机变量.这种多个变量的概率分布被称为联合概率分布(joint probability distribution).P(x=x,y=y)P(x=x,y=y)表示x=xx=x和y=yy=y同时发生的概率
一个函数PP是随机变量xx的PMF,必须满足以下条件:
1. PP的定义域必须是xx所有可能状态的集合
2. ∀x∈x,0≤P(x)≤1∀x∈x,0≤P(x)≤1 不可能发生的事件概率为0,一定发生的事件概率为1
3. ∑x∈xP(x)=1∑x∈xP(x)=1这条性质称为归一化(normalized)
如果一个离散型随机变量xx有kk不同的状态,如果每个每个状态的可能性都是相同的(均匀分布(uniform distribution)),那它的PMF为:
因为 kk 是一个正整数,所以 1k1k 也是正的,通过下列计算:
所以均匀分布也是满足归一化条件的
边缘概率
边缘概率分布(marginal probability distribution):如果我们知道了一组变量的联合概率分布,但想要了解其中一个子集的概率分布,这个子集的概率分布称为边缘概率分布
条件概率
条件概率:在其他事件发生的条件想该事件发生的概率.计算公式如下P(x=x)>0P(x=x)>0:
例题
在一汽车工厂中,一辆汽车有两道工序是由机器人完成的,其一是紧固3只螺栓,其二是焊接2处焊点。以 XX 表示由机器人紧固的螺栓紧固得不良的数目,以 YY 表示由机器人焊接的不良焊点数目。据积累的资料知 (X,Y)(X,Y) 具有分布律:
| Y\X | 0 | 1 | 2 | 3 | P{Y=j} |
|---|---|---|---|---|---|
| 0 | 0.840 | 0.030 | 0.020 | 0.010 | 0.900 |
| 1 | 0.060 | 0.010 | 0.008 | 0.002 | 0.080 |
| 2 | 0.010 | 0.005 | 0.004 | 0.001 | 0.020 |
| P{X=i} | 0.910 | 0.045 | 0.032 | 0.013 | 1.000 |
求在X=1X=1的条件下,YY的条件分布律
独立性和条件独立性
相互独立(independent):两个随机变量x和y,如果他们的概率分布可以表示成两个因子的乘积形式,并且一个因子只包含x,另一个因子只包含y,我们就能称这两随机变量是相互独立的.计算如下:
例题
实验 EE 为“抛甲、乙两枚硬币,观察正(H)反(T)面出现的情况”。设事件 AA 为“甲币出现H”,事件B为“乙币出现H”。 EE 的样本空间:
即:
由上可得 P(B|A)=P(B)P(B|A)=P(B) ,而 P(AB)=P(A)P(B)P(AB)=P(A)P(B) 。所以我们知道甲币是否出现正面与乙币是否出现正面是互不影响的。
条件独立(conditionally independent):如果关于x和y的条件概率分布对于zz的每一个值都可以写成乘积的形式那么这两个随机变量x和y子在给定随机变量zz时是条件独立的,计算如下:
数学期望
设离散型随机变量XX的分布律如下:
若是级数绝对收敛,则称级数 ∑∞k=1xkpk∑k=1∞xkpk 的和为随机变量 XX 的数学期望,记作 E(X)E(X) ,公式如下:
设连续型随机变量 XX 的概率密度为 f(x)f(x) ,若为积分绝对收敛,则称积分 ∫∞−∞xf(x)dx∫−∞∞xf(x)dx 的值为随机变量 XX 的数学期望,记作 E(X)E(X) ,公式如下:
数学期望简称期望,又称均值.
数学期望 E(X)E(X) 完全由随机变量 XX 的概率分布所确定的,若 XX 从某一分布,也称为 E(X)E(X) 是这一分布的数学期望
离散型例题
某医院当新生儿诞生时,医生要根据婴儿的皮肤颜色、肌肉弹性、反应的敏感性、心脏的搏动等方面的情况进行评分,新生儿的得分 XX 是一个随机变量,根据以往资料表明 XX 的分布律为:
| X | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| pkpk | 0.002 | 0.001 | 0.002 | 0.005 | 0.02 | 0.04 | 0.18 | 0.37 | 0.25 | 0.12 | 0.01 |
求XX的数学期望E(X)E(X)
连续型例题
有两个相互独立工作的电子装置,它们的寿命(以小时计) Xk=(k=1,2)Xk=(k=1,2) 服从同一指数分布,其概率密度为:
若将这两个电子装置串联连接组成整机,求整机寿命(以小时计) NN 的数学期望。
解: Xk(k=1,2)Xk(k=1,2) 的分布函数为:
由 N=min{X1,X2}N=min{X1,X2} 的分布函数
因而 NN 的概率密度为:
于是 NN 的数学期望为:
方差
方差(variance)设XX是一个随机变量,若E{[X−E(X)]2}E{[X−E(X)]2}存在,则称E{[X−E(X)]2}E{[X−E(X)]2}为XX的方差,记为D(X)D(X)或Var(X)Var(X),即:
如果方差很小是, XX 的值形成的簇比较接近它们的数学期望.方差的平方根 D(X)−−−−−√D(X) 称为 标准差(standard deviation)或 均方差(mean square deviation)
当 XX 为离散型随机变量时:
当 XX 为连续型随机变量时:
协方差
量E{[X−E(X)][Y−E(Y)]}E{[X−E(X)][Y−E(Y)]}称为随机变量X与Y的协方差(covariance),记作Cov(X,Y)Cov(X,Y),公式如下:
而
称为随机变量 XX 和 YY 的 相关系数(correlation)
协方差矩阵
二维随机变量(X1,X2)(X1,X2)有四个二阶中心矩(设它们都存在),分别记为:
将它们排列成矩阵的形式:
这个矩阵称为随机变量 (X1,X2)(X1,X2) 的 协方差矩阵(covariance matrix)
常用的概率分布
Bernoulli 分布
Bernoulli 分布(Bernoulli distribution)是单个二值随机变量的分布,它由单个参ϕ∈[0,1]ϕ∈[0,1]控制,ϕϕ给出了随机变量等于1的概率.
Multinoulli 分布
Multinoulli 分布(multinoulli distribution)或者范畴分布(categorical distribution)是指在具有kk个不同状态的单个离散随机变量上的分布,其中kk是一个有限值.
高斯分布
高斯分布(Gaussian distribution)也叫正态分布(normal distribution):
当 μ=0,σ=1μ=0,σ=1 是,这个我们称为 标准正态分布(standard normal distribution)
常用函数
logistic sigmoid函数
公式:
logistic sigmoid函数图
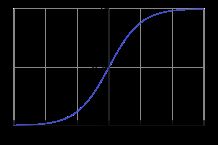
*图片来自网络
softplus 函数
公式:
softplus函数名来源于它是另一个函数的平滑(或”软化”)形式,这个函数是:
softplus函数的图
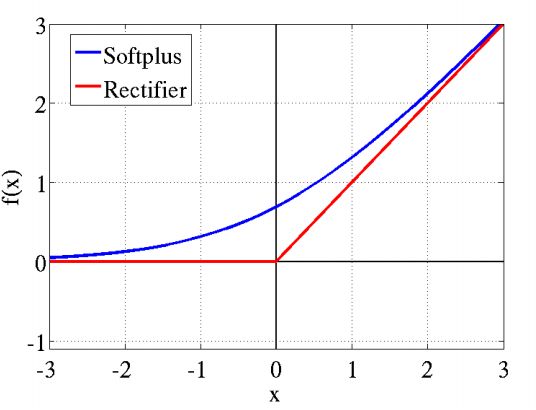
*图片来自网络
参考资料
- lan Goodfellow,Yoshua Bengio,Aaron Courville.深度学习(中文版).赵申剑,黎彧君,符天凡,李凯,译.北京:人民邮电出版社
- 浙江大学,盛骤,谢式千,潘承毅.工程数学-概率论与数理统计(第四版).北京:高等教育出版社