Graph-to-Sequence Learning using Gated Graph Neural Networks
基于门控图网络的图到序列学习
摘要
许多NLP应用可以被构造成图到序列学习的问题。 为了解决这个问题,相比于基于语法的方法,之前的工作提出了神经结构并且获得了满意的效果,但是这个结果仍然依靠于线性启发法或者标准递归网络(standard RN)才能得到较好的性能。在此工作中,我们提出了一个新的模型,其可以把包含在图中的完整的结构信息进行编码,在处理先前工作中的参数爆炸问题时,这个结构结合了最近提出的门控图网络和一个允许节点和边有隐表示(hidden representations)的输入转换。实验结果表明,我们的模型在从AMR图和基于语法的神经机器翻译(NMT)中获得了强大的优势基准(baseline)。
1 介绍
图结构在自然语言表示中无处不在。特别地,许多整个句子的语义框架都采用了有向无环图(DAG)作为基础形式,而大多数基于树的语法表示也可以被看作是图。一系列的NLP应用可以被框定为将图结构转换为一个序列的过程。例如,语言生成可能涉及将语义图实现为表面形式(surface form),并且语法机器翻译涉及将注释树(tree-annotated)的源句子转换为其翻译。
此问题中的先前工作依赖于基于语法的方法,例如树转换器和超边替换语法。这些方法的关键局限是需要图节点和表面token之间的对齐。 这些对齐通常是自动生成的,因此在构建语法时它们会传播错误。最近的方法将图转换为线性形式,并使用现成的方法,例如基于短语的机器翻译或神经序列到序列模型。这些方法忽略了完整的图形结构,丢弃了关键信息。
在这项工作中,我们提出了一个图到序列(以下称为g2s)学习的模型,该模型利用了神经编码器 - 解码器架构的最新进展。 具体来说,我们采用了一种基于门控图神经网络(GGNN)的编码器,它可以在不丢失信息的情况下整合完整的图结构。 这样的网络将边信息表示为标签方式参数(label-wise para),对于小尺寸标签词汇表(大约数百个)也可能存在问题。为了解决这个限制,我们还引入了图转换,它将边更改为额外的节点,解决了参数爆炸问题。 这也确保了边具有特定图的隐向量,为网络中的注意力(attention)和解码模块提供了更多信息。
我们在两个图到序列问题中对我们的模型进行基准测试,从抽象意义表示(AMR)生成和使用源依赖信息的神经机器翻译(NMT)。与以前的工作相比,我们的方法在不依赖标准RNN编码器的情况下优于两项任务(AMR和NMT)中的强s2s基准。特别对于NMT任务,我们通过在依赖关系树中的连续单词之间添加连续边来避免对RNN的需要。这说明了我们方法的一般性:语言偏差(linguistic biases)可以通过简单的图转换添加到输入中,而无需更改模型结构。

图1:左图:AMR图表示句子“The boy wants the girl to believe him.”。右图:我们提出的架构,使用相同的AMR图作为输入,表面形式(surface form)作为输出。第一层是节点和位置嵌入(embeddings)的串联,位置:距根节点的距离。GGNN编码器使用由不同颜色表示的边参数(edge-wise paras)来更新嵌入(在该示例中为![]() 和
和![]() )。编码器还为每个节点添加相应的反向边(图上是较浅的虚线箭头)和自循环边(图上是深色的虚线箭头)。所有参数在层之间共享。注意力(attention)和解码器组件类似于标准s2s模型。这是一个图表示:在我们的实验中,图在被用作输入之前被转换(见§3)。
)。编码器还为每个节点添加相应的反向边(图上是较浅的虚线箭头)和自循环边(图上是深色的虚线箭头)。所有参数在层之间共享。注意力(attention)和解码器组件类似于标准s2s模型。这是一个图表示:在我们的实验中,图在被用作输入之前被转换(见§3)。
2 神经图到序列模型(Neural G2S Model)
我们提出的架构如图1所示,一个示例AMR图并将其转换为表面形式。与标准s2s模型相比,主要区别在于编码器,我们使用GGNN来构建图表示(Graph representation)。在下文中,我们将详细介绍此体系结构的组件![]()
。
(![]() 我们的实现使用MXNet(Chen等,2015),并基于Sockeye工具包(Hieber等,2017)。代码可在https://github.com/beckdaniel/acl2018_graph2seq 获得)
我们的实现使用MXNet(Chen等,2015),并基于Sockeye工具包(Hieber等,2017)。代码可在https://github.com/beckdaniel/acl2018_graph2seq 获得)
2.1 门控图神经网络(GGNNs)
关于图的递归网络的早期方法假设固定点表示参数,并使用收缩图(contraction maps)进行学习。李等人认为这限制了模型的能力(capacity),使得学习节点之间的长距离关系变得更加困难。为了解决这些问题,他们提出了门控图神经网络(GGNN),它采用与门控递归单元(GRU---LSTM的变种,可以解决远距离依赖)类似的门控机制扩展了这些架构。这允许通过现代反向传播过程来学习网络。
在下文中,我们正式定义了我们在本研究中使用的GGNN版本。假设有向图![]() ,其中
,其中 ![]() 是节点集合
是节点集合![]() ,是
,是![]() 边集合
边集合![]() ,
,![]() 和
和![]() 分别是节点和边的词汇表(vocabularies),从其中定义节点和边标签
分别是节点和边的词汇表(vocabularies),从其中定义节点和边标签![]() 。给定一个输入图,其中节点映射到嵌入X(embedding X),GGNN被定义为:
。给定一个输入图,其中节点映射到嵌入X(embedding X),GGNN被定义为:

其中![]() 是节点u和v之间的边,
是节点u和v之间的边,![]() 是v的邻居节点集合,ρ是非线性函数,σ是sigmoid函数,
是v的邻居节点集合,ρ是非线性函数,σ是sigmoid函数,![]() 是归一化常数。
是归一化常数。
我们的公式(formulation)与Li等人2016年的原始GGNN公式有几方面不同:1)我们为隐状态(hidden state)、复位门(reset gate)和更新门(update gate)计算添加偏置向量(bias vectors); 2)特定标签(label-specific)的矩阵不共享任何组件; 3)在计算之前将复位门应用于所有隐状态,4)添加了归一化常数。这些修改基于初步实验,且易于实现。
GGNN的另一种选择是来自Marcheggiani和Titov2017年的模型,其将边标签信息添加到图卷积网络(GCN)。根据Li等人的说法,GCN和GGNN之间的主要区别类似于卷积网络和循环网络之间的差异。更具体地说,GGNN可以看作多层的GCN,且绑定了分层参数(layer-wise parameters),并且添加了门控机制。许多层可以在图中传播较长距离的节点信息,并且与GCN不同的是,GGNN可以具有任意数量的层而不增加参数的数量。尽管如此,我们的架构也借鉴了GCN的想法,例如规范化因素。
2.2 GGNNs在注意力 编码-解码模型中的使用(Using GGNNs in attentional encoder-decoder models)
在s2s模型中,输入是token序列,其中每个token由嵌入向量(embedding vectors)表示。然后,编码器通过合并上下文,通过循环或卷积网络将这些向量转换为隐状态,这些隐状态被馈送到注意力机制(attention mechanism),生成单个上下文向量,通知解码器中的决策。
我们的模型遵循类似的结构,其中编码器是GGNN,其接收节点嵌入(node embedding)作为输入并使用图结构作为上下文生成节点隐状态作为输出,这在图1的示例中表现,其中我们具有4个隐向量,AMR(抽象意义表示)图中的每个节点一个隐向量。注意力和解码器组件遵循类似的标准s2s模型,其中我们使用双线性注意机制和2层LSTM作为解码器。但是,请注意,也可容易地使用其他解码器和注意机制。 Bastings等人对基于语法的NMT(神经机器翻译)采用类似的想法,但使用的是GCN。
2.3 双向性和位置嵌入(Bidirectionality and positional embeddings)
虽然我们的架构在理论上可以与通用图一起使用,但带根有向无环图(RDAG)可以说是我们正在解决的问题中最常见的类型。这意味着节点嵌入信息(node embedding information)以自顶向下的方式传播。然而,我们希望反方向也具有信息流,基于RNN的编码器以同样的方式从右向左的传播中(如在双向RNN中)受益。 Marcheggiani和Titov、Bastings等人通过向图中添加反向边,以及每个节点的自循环边来实现此目的。这些额外的边具有特定的标签,因此它们在网络中具有自己的参数。
在这项工作中,我们还遵循此过程以确保信息在图中均匀传播。然而,这提出了另一个缺陷:因为图基本上变成无向的,编码器现在不知道输入中存在的任何内在层次结构。来自Gehring等人和Vaswani等人的灵感,我们通过向每个节点添加位置嵌入(positional embeddings)来解决这个问题。这些嵌入(embeddings)由表示距根节点的最小距离的整数值索引,并作为模型参数进行学习。(![]() )这种位置嵌入仅限于有根DAG图:对于一般图,可以采用不同的距离概念。
)这种位置嵌入仅限于有根DAG图:对于一般图,可以采用不同的距离概念。
(![]() : Vaswani等人还提出了基于正弦和余弦波长的固定位置嵌入。初步实验表明,这种方法在我们的情况下不起作用:我们推测这是因为波长更适合于顺序输入。)
: Vaswani等人还提出了基于正弦和余弦波长的固定位置嵌入。初步实验表明,这种方法在我们的情况下不起作用:我们推测这是因为波长更适合于顺序输入。)
3 Levi图变换(Levi Graph Transformation)
§2中提出的g2s模型有两个关键缺陷。首先,GGNN每个边类型有三个线性变换,这意味着参数的数量会爆炸:例如,AMR有大约100个不同的谓词对应于边标签。以前的工作通过明确地将边标签分组为单个标签来处理这个问题,但这不是一个理想的解决方案,因为它会导致信息丢失。


图2:上图:把图1中的AMR图转换为相应的Levi图。下图:带有反向和自循环边的Levi图(颜色代表不同的边标签)。
第二个缺陷是边标签信息以网络中的GGNN参数的形式编码,这意味着每个标签在所有图中都具有相同的“表示”。但是,边中的潜在信息可能取决于它们在图形中出现的内容。理想情况下,边应该具有特定实例(instance-specific)的隐状态,与节点的方式相同,并且这些隐状态也应该通过注意力模块通知解码器中的决策(之前已经阐述过)。例如,在图1所示的AMR图中,![]() 和
和 ![]() 之间的
之间的 ![]() 谓词可以解释为表面形式的介词“to”,而连接
谓词可以解释为表面形式的介词“to”,而连接 ![]() 和
和 ![]() 的ARG1谓词实现为代词。请注意,边隐藏向量已经存在于使用线性化图的s2s网络中:我们希望我们的架构也具有这种优势(benefit)。
的ARG1谓词实现为代词。请注意,边隐藏向量已经存在于使用线性化图的s2s网络中:我们希望我们的架构也具有这种优势(benefit)。
我们建议将输入图转换为等效的Levi图,而不是修改架构。给定图![]() ,Levi图(Levi
,Levi图(Levi ![]() )被定义为
)被定义为![]() ,其中
,其中![]() 。新边集
。新边集 ![]() 包含原始图中存在的每个(节点,边)对(pair)的边。根据定义,Levi图是二分图。
包含原始图中存在的每个(节点,边)对(pair)的边。根据定义,Levi图是二分图。
(Levi ![]() ,形式上,Levi图是在任何入射结构上定义的,这是通常在几何背景考虑的一般概念。图是入射结构的一个例子,但欧几里德空间中的点和线也是如此。)
,形式上,Levi图是在任何入射结构上定义的,这是通常在几何背景考虑的一般概念。图是入射结构的一个例子,但欧几里德空间中的点和线也是如此。)
直观地,将图转换为其等效的Levi图形,将边转换为其他节点。虽然理论上很简单,但这种转换以优雅的方式解决了上面提到的模型缺陷。由于Levi图没有标记边(labelled edges),因此不存在参数爆炸的风险:原始边标签(original edge labels)以和节点相同的方式表示为嵌入。此外,编码器现在也自然地为原始边生成隐状态。
在实践中,我们遵循§2.3中的过程并将反向和自循环边添加到Levi图,因此实际的边标签词汇表是![]() = {default,reverse,self}。这仍然保持参数空间适度,因为我们只有三个标签。图2详细显示了转换步骤,应用于图1所示的AMR图。请注意,转换后的图是我们架构中的图:为简单起见,我们在图1中显示原始图。
= {default,reverse,self}。这仍然保持参数空间适度,因为我们只有三个标签。图2详细显示了转换步骤,应用于图1所示的AMR图。请注意,转换后的图是我们架构中的图:为简单起见,我们在图1中显示原始图。
重要的是要注意,此转换可以应用于任何图,因此独立于模型架构。我们推测这可能对其他类型的基于图形的编码器(如GCN)也会有益,并对未来的工作进行进一步的研究。
4 从AMR图生成(Generation from AMR Graphs)
我们的第一个g2s基准是来自AMR的语言生成,这是将句子表示为有根DAG图的一种语义形式,因为AMR从语法中抽象出来,所以图形没有金标准(gold-standard)对齐信息,所以生成不是一项简单的任务。因此,我们假设我们提出的模型针对这个问题是理想的。
4.1 实验装置(Experimental setup)
数据和预处理(Data and preprocessing) 我们使用最新的AMR语料库版本,默认分为 36521/1368/1371 个实例,用于训练/开发(development)/测试集。使用类似于Konstas等人执行的程序对每个图进行预处理,包括实体简化和匿名化。此预处理要在将图形转换为等效的Levi图之前完成。对于s2s基线,我们还添加范围标记,如Konstas等人所述。我们在附录中详述了这些程序。
模型(Models) 我们的基线是注意力s2s模型,将线性图作为输入。该架构类似于Konstas等人使用的用于AMR生成的架构,其中编码器是BiLSTM,后面是单向LSTM。所有维度都固定为512。
对于g2s模型,我们将GGNN编码器中的层数设置为8,因为这样设置在开发集上能获得最佳结果。除了使用576维的GGNN编码器之外,维数尺寸也固定为512维。这是为了确保所有模型具有相当数量的参数并因此具有相似的能力(capacity)。
所有模型的训练都使用Adam,初始学习率(lr)为0.0003,批量大小(![]() )为16。为了使我们的模型正规化,我们在基于 混乱(perplexity)的开发集(development set)上提前停止,并且在源嵌入(source embeddings)上应用0.5的dropout。我们在附录中详细介绍了其他模型和训练超参(training hyperparameters)。
)为16。为了使我们的模型正规化,我们在基于 混乱(perplexity)的开发集(development set)上提前停止,并且在源嵌入(source embeddings)上应用0.5的dropout。我们在附录中详细介绍了其他模型和训练超参(training hyperparameters)。
(![]() 在我们的初步实验中,更大的batch_size会影响开发性能。有证据表明小批量可以带来更好的泛化性能(Keskar等,2017)。虽然这可以使训练时间变慢,但在我们的情况下这是可行的,因为数据集很小。)
在我们的初步实验中,更大的batch_size会影响开发性能。有证据表明小批量可以带来更好的泛化性能(Keskar等,2017)。虽然这可以使训练时间变慢,但在我们的情况下这是可行的,因为数据集很小。)
评估(Evaluation) 紧随之前的工作,我们使用BLEU评估我们的模型,并执行辅助程序(bootstrap)重采样以检查统计显着性(statistical significance)。然而,由于最近有研究质疑BLEU在辅助程序重采样(bootstrap resampling)方面的有效性,所以我们还使用句子级(sentence-level)的![]()
![]() 报告结果,使用Wilcoxon符号秩检验(signed-rank)检查显着性。评估对两个指标都不区分大小写。
报告结果,使用Wilcoxon符号秩检验(signed-rank)检查显着性。评估对两个指标都不区分大小写。
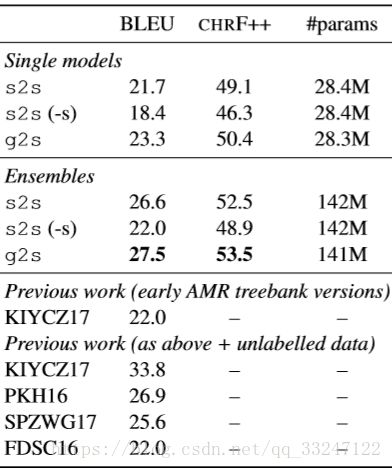
表1:测试集上AMR生成的结果。我们的模型和相应基线之间的所有得分差异都显着不同(p <0.05)。 “(-s)”表示没有范围标记的输入。 KIYCZ17,PKH16,SPZWG17和FDSC16分别是Konstas等人、Pourdamghani等人、Song和弗拉尼根等人报告的结果。
最近的研究表明,仅通过改变随机种子(random seed),神经模型中的评估可能导致错误的结论。为了使我们的结论更加稳健,我们使用不同的种子运行每个模型5次。从每个pool中,我们根据开发集(dev set)的性能(模拟单次运行的预期)和5个模型的集成(ensemble),使用中值模型(median model)报告结果。最后,我们还报告了每个模型中使用的参数数量。由于我们的编码器架构完全不同,我们尝试通过改变隐层的维度来匹配它们之间的参数数量(如上所述)。我们这样做是为了尽量减少模型容量作为混淆因素的影响。
4.2 结果和分析(Results and analysis)
表1显示了测试集上的结果。对于s2s模型,我们还报告了Konstas等人的没有范围标记程序的结果。我们的方法在使用相同数量的参数时,明显优于使用单独的模型和集成的s2s基线。特别是,我们在不依赖范围启发式(scoping heuristics)的情况下获得这些结果。
在图3中,我们展示了一个示例,其中我们的模型优于基线(baseline)。 AMR图包含四个重入(reentrancies),谓词(predicates),这两个概念引用图中先前定义的概念。在包括Konstas等人的s2s模型中,可重入点(reentrant nodes)以线性化形式复制,而这对于我们的g2s模型不是必需的。我们可以看到s2s预测过度生成(overgenerate)了“印度和中国”这个短语。 g2s预测避免了过度生成(overgeneration),并且几乎完全匹配参照(reference)。虽然这只是一个例子,但它提供了一个证据,即保留完整的图形结构对于这项任务是有益的,这可以通过我们的定量结果得到证实。

图3:例子展示了由于重入导致而过度生成的示例。顶部:突出(highlight)关键重入的原始AMR图。底部:s2s和g2s模型生成的参照(references)和输出,突出了过度生成现象。
表1还显示了之前工作中报告的BLEU分数。这些结果不具有严格的可比性,因为它们使用了不同的训练集版本 并且/或者 使用了其他未标记的语料库;尽管如此,仍然可以提出一些见解。特别是,我们的g2s集成(ensemble)比许多以前的模型表现更好,这些模型将较小的训练集与大的未标记(ublabelled)语料库相结合。将我们的s2s模型与Konstas等人进行比较也是最有用的。 (2017),因为这个基线(baseline)与他们的基线非常相似。我们期望我们的单一模型基线优于他们的,因为我们使用更大的训练集但却获得了类似的性能(performance)。我们推测通过更仔细的调整(tuning)可以获得更好的结果,但我们相信这样的调整也将有益于我们提出的g2s架构。
Konstas等人获得了未标记数据的最佳结果,使用Gigaword语句作为附加数据和使用AMR解析器(AMR parser)的配对训练程序(procedure)。值得注意的是,此程序与用于生成和解析的各个模型正交。因此,我们假设我们的模型也可以从这些技术中获益,这是我们为未来工作留下的一条途径。
5 基于语法的神经机器翻译(Syntax-based Nural Machine Translation)
我们的第二个评估是NMT,使用图源语言依赖语法树(using as graphs source language dependency syntax trees.)。我们专注于中等资源情景(medium resource scenario),其中额外的语言信息往往更有益。我们的实验包括两种语言对(pairs):英语 - 德语和英语 - 捷克语。
5.1 实验装置(Experimental setup)
数据和预处理(Data and preprocessing) 我们使用Bastings(![]() )等人提供的相同数据和设置,使用来自WMT16翻译任务的新闻评论V11(
)等人提供的相同数据和设置,使用来自WMT16翻译任务的新闻评论V11(![]() )语料库。使用
)语料库。使用![]() 对英文文本进行标记和解析,同时使用字节对编码(byte-pair encodings)对德语和捷克文本进行标记并将其拆分为子字(8000合并操作)。我们参考Bastings等人来获得更多有关预处理步骤的信息。
对英文文本进行标记和解析,同时使用字节对编码(byte-pair encodings)对德语和捷克文本进行标记并将其拆分为子字(8000合并操作)。我们参考Bastings等人来获得更多有关预处理步骤的信息。
(![]() : 我们从原作者那里获得了数据,以确保结果具有可比性,而不受预处理步骤的任何影响。
: 我们从原作者那里获得了数据,以确保结果具有可比性,而不受预处理步骤的任何影响。
![]() :http://www.statmt.org/wmt16/ translation-task.html ,
:http://www.statmt.org/wmt16/ translation-task.html ,
![]() :https://github.com/tensorflow/models/ tree/master/syntaxnet,这个网址好像已经done掉了)
:https://github.com/tensorflow/models/ tree/master/syntaxnet,这个网址好像已经done掉了)
源侧(source side)的标记依赖树被转换为Levi图作为预处理步骤。然而,与AMR生成不同,在NMT中,输入最初是包含重要顺序信息的表面形式(surface form),将输入视为依赖树时,此信息会丢失,这可能解释了Bastings等人在编码器中使用初始RNN层并获得最佳性能的原因。为了研究这种现象,我们还对应于它们在原始表面形式中的顺序,在依赖树中为每个单词添加顺序连接进行实验(以下称为g2s +)。这些连接使用具有特定左右标签的边进行表示,这些是在Levi图转换后才添加的。图4显示了g2s +的输入图的示例,其中有连接单词(word)的附加连续边(为简单起见,省略了反边和自边)。

图4:上图:具有相应依赖关系树的句子。下图:将变换后的树转换为在单词之间具有附加顺序连接(虚线)的Levi图。完整图还包含反向和自动边缘,在图中省略。
模型 (Models) 我们的s2s和g2s模型差不多与4.1节的AMR生成实验相同。唯一的例外是GGNN编码器的维度,其中我们使用512维仅用于依赖树的实验,而448维用于当输入具有额外的顺序连接时。如在AMR生成设置中,我们这样做是为了确保模型能力(model capacity)在参数数量上是相当的。另一个关键区别是s2s基线不使用依赖树:它们仅在句子上训练。
除了神经模型,我们还使用Moses(Koehn等,2007)报告了基于短语的统计MT(PB-SMT)的结果。 PB-SMT模型使用与s2s相同的数据条件(无依赖树)进行训练,并使用Moses的标准设置(standard setup),除了语言模型,我们使用在相应并行(repsective parallel)语料库(![]() )的目标侧(target side)训练5-gram LM。(
)的目标侧(target side)训练5-gram LM。(![]() 请注意,目标数据使用BPE进行分段segmented,这不是PB-SMT的常用设置。我们决定保留分割segmentation以确保数据条件相同。)
请注意,目标数据使用BPE进行分段segmented,这不是PB-SMT的常用设置。我们决定保留分割segmentation以确保数据条件相同。)
评估(Evaluation) 我们使用两种区分大小写的指标(metrics)报告BLEU和![]()
![]() 的结果。其他设置与AMR生成实验(第4.1节)中的设置保持一致。对于PB-SMT,我们报告了5次运行的中值结果(median result),通过使用5次MERT调整模型5得。
的结果。其他设置与AMR生成实验(第4.1节)中的设置保持一致。对于PB-SMT,我们报告了5次运行的中值结果(median result),通过使用5次MERT调整模型5得。
5.2 结果和分析(Results and analysis)
表2显示了两种语言对(language pairs)的相应测试集的结果。不考虑顺序信息的g2s模型落后于我们的基线,这符合Bastings等人的发现:有一个BiRNN层是获得最佳结果的关键。然而,在单一模型和集成场景(ensemble scenarios)中, g2s+ 模型在相同参数预算下的BLEU分数方面优于基线。这个结果表明在我们的模型中包含顺序偏差(sequential biases)是可能的 ,且不依赖RNN或架构中的任何其他修改。
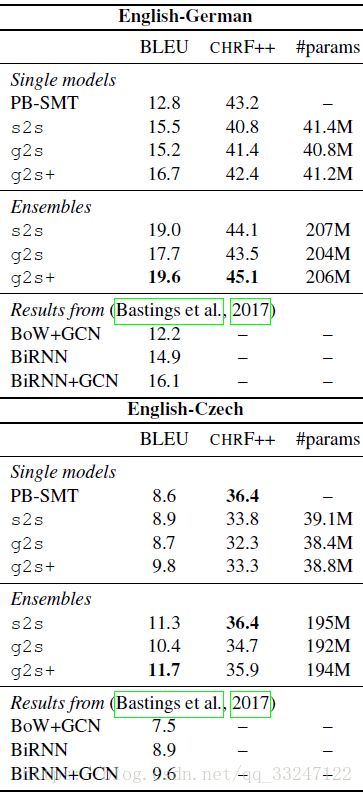
表2:测试集上基于语法的NMT的结果。我们的模型和相应基线之间的所有得分差异显着不同(p <0.05),包括En-Cs的负的(negative)![]()
![]() 结果。
结果。
有趣的是,我们在分析![]()
![]() 数字时发现了不同的趋势。特别是,这个指标(
数字时发现了不同的趋势。特别是,这个指标(![]()
![]() )在两个语言对中都偏爱PB-SMT模型,同时也显示提高了En-C中s2s的性能。在两个语言对中,与BLEU相比,已经证明
)在两个语言对中都偏爱PB-SMT模型,同时也显示提高了En-C中s2s的性能。在两个语言对中,与BLEU相比,已经证明![]()
![]() 与人类判断(human judgments)有更好的相关性,无论是在系统还是句子两个方面,这促使我们选择它作为额外的指标。我们将在今后的工作中进一步调查这个现象。
与人类判断(human judgments)有更好的相关性,无论是在系统还是句子两个方面,这促使我们选择它作为额外的指标。我们将在今后的工作中进一步调查这个现象。
我们在表2中还展示了Bastings等人报告的一些结果。请注意,他们的结果基于不同的实现,这可以解释性能的一些变化。他们的 BoW + GCN 模型与我们的模型十分相似,因为它仅使用嵌入层和GCN编码器。可以看到,即使我们更简单的g2s模型也能胜过他们的结果。他们的方法和我们方法之间的一个关键区别是Levi图变换和作为结果得边的隐矢量,相信他们的架构也能从我们提出的转换中受益。在基线方面,s2s比En-De的BiRNN模型表现更好,与En-Cs表现相当,这证实了我们的基线是强大的。最后,我们的 g2s+ 单一模型优于其BiRNN + GCN的结果,特别对于En-De,这进一步证明RNN对于在此设置中获得最佳性能不是必需的。
关于这些实验的一个重点是我们没有调整架构:我们只使用了我们在AMR生成实验中使用的相同模型,只调整编码器的维度以匹配基线的能力(capacity)。我们推测,对此任务通过架构调整可以获得更好的结果。尽管如此,我们仍然获得了比基线和以前的工作更好的性能,强调了我们架构的泛化性。
6 相关工作(Related work)
图到序列建模(Graph-to-sequence modelling) 针对此问题的早期NLP方法基于Hyperedge Replacement Grammars(超边替换语法)。这些语法假设转换问题可以划分成一些规则,这些规则将 图的部分 映射成输出序列中的token集合。特别是Chiang等人定义了一个解析算法,然后是复杂性分析,而Jones等人报告了使用HRG进行基于语义的机器翻译实验。 HRG也用于以前的AMR解析工作。这些基于语法的方法的主要缺点是需要在图节点和表面token(surface token)之间进行对齐(alignment),这些通常在黄金标准形式(gold-form standard)中无效(not available)。
图神经网络(Neural networks for graphs) 一般图的递归网络(RN)以图神经网络(GNN)的名称首次提出。我们的工作基于Li等人提出的增加了门控机制的架构。他们的工作与我们的工作之间的主要区别在于,他们专注于与输入图本身有关的问题,例如节点分类或路径查找,而我们专注于生成字符串。基于神经的图表示的主要选择方案是图卷积网络(GCN),它已经应用于一系列问题。在NLP中,Marcheggiani和Titov使用类似的语义角色标记(Semantic Role Labelling)体系结构,他们使用启发式通过对边标签进行分组来减轻参数爆炸问题,同时我们通过Levi图变换保留原始标签。Schlichtkrull等人提出了一个有趣的选择,它使用张量因子分解(tensor factorisation)来减少参数的数量。
应用(Applications) 早期的AMR生成工作采用语法和传感器。线性化方法包括(Pourdamghani等,2016)和(Konstas等,2017),它们表明图简化(simplification)和匿名化(anonymisation)是获得良好性能的关键,我们在工作中也采用了这种方法。然而,与我们的方法相比,线性化会导致信息丢失。MT在以前悠久的历史工作中,旨在整合语法,这个想法也在NMT上下文(context)中进行了研究。 Bastings等人做了和我们十分相似的工作,我们在NMT实验中对其方法进行了基准测试。Eriguchi等人也使用源语法,但使用选区树(constituency trees)。其他方法已经研究了目标语言中语法的使用。最后,Hashimoto和Tsuruoka将源语法视为潜在变量,其可以使用注释数据(annotated data)预先训练 。
7 讨论和结论(Discussion and Conclusion)我们提出了一种新的编码器 - 解码器架构,用于图到序列学习,在两个NLP任务中表现优于基线:从AMR图生成和基于语法的NMT。我们的方法解决了以前工作中的缺点,包括线性化和参数爆炸导致的信息丢失。特别是,我们展示了图转换如何在不改变底层架构的情况下解决基于图的网络中的问题。这是所提出的Levi图变换的情况,其确保解码器可以处理边、节点,以及在NMT的情况下添加到依赖树的顺序连接。总的来说,因为我们的架构可以使用一般图工作,所以可以直接以额外节点 和/或 边信息的形式添加语言偏差。我们相信这在应用方面是一个有趣的研究方向。
然而,我们的架构有两个主要限制。第一个是GGNN具有固定数量的层,即使图在节点和边的数量方面可以变化。更好的方法是允许编码器具有动态数量的层,可能基于输入图中的直径(最长路径)。第二个限制来自Levi图变换:因为边标签被表示为节点,它们最终共享词汇表,因此有相同的语义空间。这并不理想,因为节点和边是不同的实体。一个有趣的选择是Weave Module Networks,它明确地解耦(decouple)节点和边表示而不会引起参数爆炸。将这两种想法融入我们的架构是我们为未来工作规划的研究方向。
A AMR图的简化和匿名化(Simplification and Anonymisation for AMR graphs)
图简化和匿名化的过程(procedure)类似于(Konstas等人,2017)所做的过程。主要区别在于我们使用AMR语料库的原始LDC版本提供的对齐(alignments),而他们使用JAMR对齐器(Flanigan等人,2014)和无监督对齐器(Pourdamghani等人,2014)的组合。此预处理在将图形转换为其二分等效值之前完成。
简化(Simplification):我们从概念中删除感知信息(sense info)。例如,![]() 变成
变成![]() 。我们还删除了与wikification相关的任何子图(启动谓词的那些子图:wiki)。
。我们还删除了与wikification相关的任何子图(启动谓词的那些子图:wiki)。
实体匿名化(Entity anonymisation):所有以谓词:![]() 开始的子图被匿名。谓词包含一个AMR实体名称作为源节点,例如
开始的子图被匿名。谓词包含一个AMR实体名称作为源节点,例如![]() 或*
或* ![]() 。它们由单个匿名节点替换,包含原始实体概念和索引。在训练时,我们使用对齐信息在表面形式中查找对应的实体,并用相同的概念名称替换所有对齐的token。在测试时,我们提取一个映射(map),该映射(map)将匿名实体映射到子图中的所有概念名称,且按深度优先顺序排列。在预测之后,如果表面形式中存在匿名token,则使用该映射替换它(只要预测token存在于地图中)。
。它们由单个匿名节点替换,包含原始实体概念和索引。在训练时,我们使用对齐信息在表面形式中查找对应的实体,并用相同的概念名称替换所有对齐的token。在测试时,我们提取一个映射(map),该映射(map)将匿名实体映射到子图中的所有概念名称,且按深度优先顺序排列。在预测之后,如果表面形式中存在匿名token,则使用该映射替换它(只要预测token存在于地图中)。
实体聚类(Enitity clustering):实体也以图和表面形式聚集成四种粗粒度(coarse-grained)类型。例如,country_0变为loc_0。我们使用从(Konstas等,2017)的开源实现获得的列表。
日期匿名化(Date anonymisation):如果存在 ![]() 概念,则所有基础概念也是匿名的,使用单独的token表示日,月和年。在训练时,表面形式在对齐后也是匿名的,但我们还将日(days)和月份(months)分为day_name,day_number,month_name和month_number。在测试时,我们根据表面形式和记录的映射中预测的匿名token来处理日/月。
概念,则所有基础概念也是匿名的,使用单独的token表示日,月和年。在训练时,表面形式在对齐后也是匿名的,但我们还将日(days)和月份(months)分为day_name,day_number,month_name和month_number。在测试时,我们根据表面形式和记录的映射中预测的匿名token来处理日/月。
B 模型超参(Model Hyperparameters)
我们的实现基于Sockeye神经机器翻译工具包(Hieber等,2017)。除了本文中提到的特定超参数值之外,所有其他超参数都设置为Sockeye中的默认值。我们在此详细说明它们的完整性:
B.1 词汇表(Vocabulary)
![]() 对于AMR,我们在源节点和目标表面token中将最小频率设置为2。对于NMT,我们还使用2作为源中的最小频率,但是在目标中使用1,因为我们使用的是BPEtoken。
对于AMR,我们在源节点和目标表面token中将最小频率设置为2。对于NMT,我们还使用2作为源中的最小频率,但是在目标中使用1,因为我们使用的是BPEtoken。
B.2 模型(Model)
![]() 基线编码器使用BiLSTM,后面跟一个单向LSTM。所有模型的解码器都使用2层LSTM。
基线编码器使用BiLSTM,后面跟一个单向LSTM。所有模型的解码器都使用2层LSTM。
![]() AMR训练期间的最大序列长度为200。在NMT中,我们使用100作为s2s基线,200作为g2s模型的基线。这是因为我们不在基线中使用依赖树,因此它自然有一半的tokens。
AMR训练期间的最大序列长度为200。在NMT中,我们使用100作为s2s基线,200作为g2s模型的基线。这是因为我们不在基线中使用依赖树,因此它自然有一半的tokens。
![]() 所有维度都固定为512,这与(Konstas等人,2017)使用的维度相似。唯一的例外是g2s模型中的GGNN隐状态维度。我们使用576用于AMR实验中使用的g2s模型,并使用448用于NMT实验中使用的g2s +模型。正如主要论文所指出的,我们改变GGNN维度,以便与s2s基线相比具有相似的参数预算。
所有维度都固定为512,这与(Konstas等人,2017)使用的维度相似。唯一的例外是g2s模型中的GGNN隐状态维度。我们使用576用于AMR实验中使用的g2s模型,并使用448用于NMT实验中使用的g2s +模型。正如主要论文所指出的,我们改变GGNN维度,以便与s2s基线相比具有相似的参数预算。
B.3 训练(Training)
这些选项适用于s2s基线和g2s g2s +模型。
![]() 我们使用16作为批量大小。这比我们之前比较的大多数工作都要少:我们选择这个是因为我们在AMR开发集中获得了更好的结果。这与最近的证据一致,表明较小的批量大小导致更好的泛化性能(Keskar等,2017)。缺点是较小的批次使得训练时间变慢。然而,由于数据集的中等大小,这在我们的实验中不是问题。
我们使用16作为批量大小。这比我们之前比较的大多数工作都要少:我们选择这个是因为我们在AMR开发集中获得了更好的结果。这与最近的证据一致,表明较小的批量大小导致更好的泛化性能(Keskar等,2017)。缺点是较小的批次使得训练时间变慢。然而,由于数据集的中等大小,这在我们的实验中不是问题。
![]() Bucketing用于加速训练:我们使用10作为bucket大小。
Bucketing用于加速训练:我们使用10作为bucket大小。
![]() 模型使用交叉熵作为loss进行训练
模型使用交叉熵作为loss进行训练
![]() 我们在训练集的每个完整epoch上保存参数检查点。
我们在训练集的每个完整epoch上保存参数检查点。
![]() 我们通过模糊(perplexity)使用patience8对开发集提前停止(如果开发模糊在8个检查点没有改善,则训练停止)。
我们通过模糊(perplexity)使用patience8对开发集提前停止(如果开发模糊在8个检查点没有改善,则训练停止)。
![]() 最多使用30个epochs/检查点。我们所有模型在达到此限制之前都停止了训练
最多使用30个epochs/检查点。我们所有模型在达到此限制之前都停止了训练
![]() 在输入嵌入上使用0.5的dropout,在他们反馈到编码器之前。
在输入嵌入上使用0.5的dropout,在他们反馈到编码器之前。
![]() 使用Xavier初始化(Glorot和Bengio,2010)初始化权重,除了LSTM中的遗忘偏差(forget biases),其初始化为0。
使用Xavier初始化(Glorot和Bengio,2010)初始化权重,除了LSTM中的遗忘偏差(forget biases),其初始化为0。
![]() 使用Adam作为优化器,0.0003的初始化学习率
使用Adam作为优化器,0.0003的初始化学习率
![]() 每当开发模糊在3个epochs/检查点没有改善时,学习率减半。
每当开发模糊在3个epochs/检查点没有改善时,学习率减半。
![]() 梯度剪裁设置为1.0
梯度剪裁设置为1.0
B.4 解码
![]() 我们使用波束搜索(beam search)进行解码,使用5作为波束大小。
我们使用波束搜索(beam search)进行解码,使用5作为波束大小。
![]() 通过在每个步骤平均对数概率(Sockeye中的线性)来创建集成(ensemble)。每个步骤的5个模型的平均注意力得分被平均
通过在每个步骤平均对数概率(Sockeye中的线性)来创建集成(ensemble)。每个步骤的5个模型的平均注意力得分被平均
![]() 仅对于AMR,我们在具有最高注意力得分的节点的预测处替换
仅对于AMR,我们在具有最高注意力得分的节点的预测处替换